












9.9元起畅享高性能GPU云服务器
GPU产品新用户均可参与,同一用户限试用一种机型。活动截止至2026年12月31日。

项目算力紧缺?高校优惠1.4折起
科研项目、毕设论文需要算力?高校GPU新客专属优惠1.4折起。

多卡专区,成本直降
多卡型1.1折起,RTX40系低至3.1折,新老同享续费同价。
应用场景
中小规模训练/推理
图像分类、语音识别,单次推理耗时短,并发量低
教学培训/个人学习
轻量级任务,成本敏感度高
开发测试环境
代码调试,小模型验证,算力需求波动大
产品优势

多卡型适配多场景
A/H/RTX系列多款卡型为训练和推理提供可靠算力支撑,打造可拓展的GPU加速服务平台;

性能卓越安全可靠
安全可靠的网络环境和防护服务,高扩展集群提升多卡协作效率满足分布式训练需求;

高性价比开箱即用
涵盖各类热门主流镜像,封装多版本CUDA和驱动,提供开箱即用的AI基础架构能力;

产品灵活与定制化
客户需求响应快,提供私有化部署方案,适配客户复杂的IT环境为其节省IT支出;


, 物理独享, 性能拉满
AI大模型训练/微调
需持续高算力、无中断,显存占用>50GB
HPC高性能计算
需微秒级延迟、计算结果零误差
自动驾驶模型
需7×24小时稳定响应,拒绝延迟波动
实时图形渲染
需帧率稳定>60fps、延迟<20ms
在售裸金属的性能参数说明
| 型号 | 显存 | CPU | 内存 | 系统盘 | 数据盘 |
|---|---|---|---|---|---|
| RTX40系 | 24G*8 | AMD 9354*2 | 1024G | 960G SSD*2 | 7.68T Nvme*1 |
| RTX40系(高显存) | 48G*8 | INTEL 6530*2 | 1024G | 960G SSD*2 | 7.68T Nvme*1 |
| RTX50系 | 32G*8 | INTEL 6530*2 | 1024G | 960G SSD*2 | 7.68T Nvme*1 |
| A系列 | 80G*8 | INTEL 8358*2 | 1024G | 960G SATA*2 | 7.68T Nvme*1 |
| H系列 | 141G*8 | INTEL 8468*2 | 2048G | 960G Nvme*2 | 4.84T Nvme*8 |
点击【立即咨询】查看配置方案和最新报价。
产品优势

物理独占极致性能
物理机资源独享,满足高安全与合规要求,无虚拟化损耗,GPU/网络/存储性能100%释放;尤其适合对计算、存储和网络吞吐有极致要求的场景

安全与合规性更高
金融风控、政务大数据、军工仿真等领域,对“数据物理隔离”的强制要求,裸金属支持自定义安全策略,进一步降低攻击面。

定制优势硬件可配
多卡并行,GPU间通过NVLink/NVSwitch高速互联,用户可自主安装任意版本GPU驱动、操作系统,深度满足用户需求。

高负载场景成本低
裸机交付,无虚拟化层额外成本,适合7×24小时满负载运行场景,充分利用整机资源,避免“为峰值付费”的浪费。
应用场景
AI工具/AI应用
高并发业务快速缩扩容、轻松应对业务洪峰
美颜换脸视频剪辑视频生成
- 实时美颜 + 低延时云上处理 CPU/GPU 智能扩缩容,晚间 8-10 点直播高峰自动扩容 3 倍,从容应对流量峰值
- 智能剪辑一键成片 批量视频处理自动创建临时 Pod,转码 / 特效渲染后即时回收资源
- AI 换脸 / 表情包 基于消息队列(如 RabbitMQ)弹性伸缩,隔离人脸数据仅流向指定推理 Pod,保障安全
立即咨询
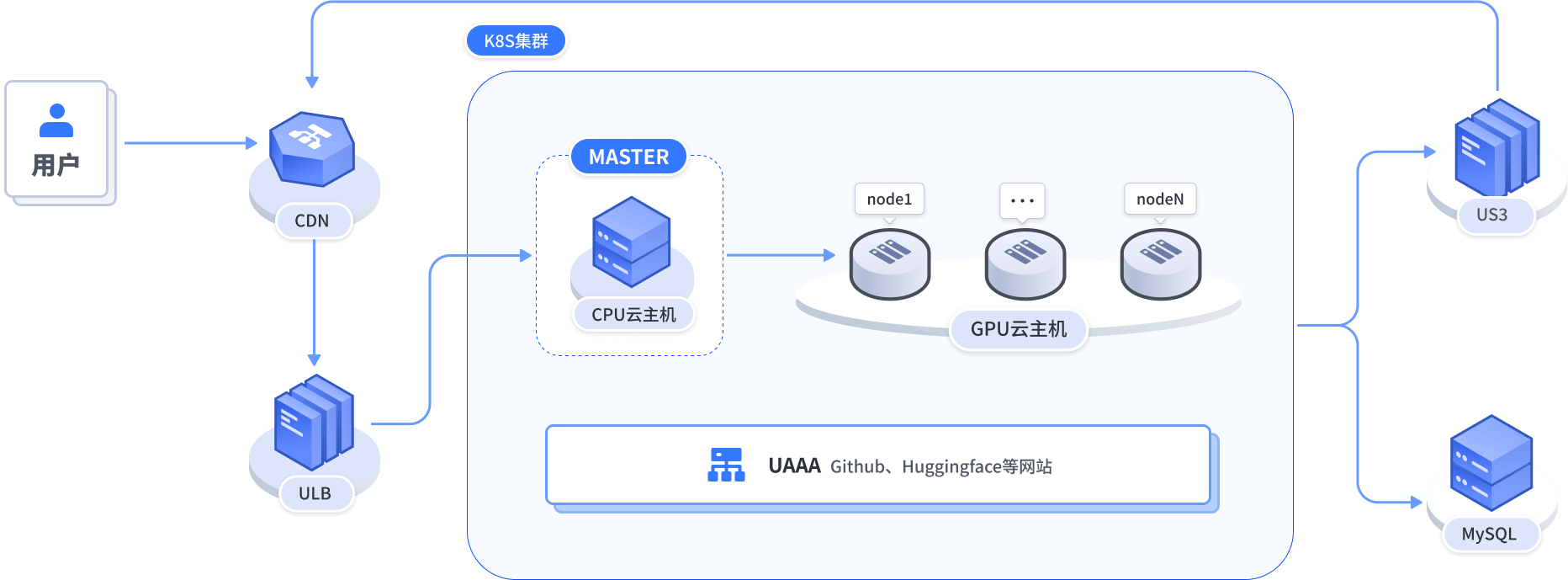
CPU 云主机US3MySQLUAAA
客户案例
