
摘要:台机器的机器名务必不同,后续会谈到机器名对于有很大的影响。分布式环境中客户端创建任务并提交。可选择配置,主要作用是在每一个执行完分析以后,在本地优先作的工作,减少在过程中的数据传输量。
使用场景:个人觉得最适合的就是海量数据的分析,其实Google最早提出MapReduce也就是为了海量数据分析。同时HDFS最早是为了搜索引擎实现而开发的,后来才被用于分布式计算框架中。
How to Use Hadoop & Tips
7台机器的机器名务必不同,后续会谈到机器名对于MapReduce有很大的影响。
以下是一个简单的Hadoop-site.xml的配置:
hadoop-env.sh文件只需要修改一个参数:
# The java implementation to use.
export JAVA_HOME=/usr/ali/jdk1.5.0_10
Masters中配置Masters的ip或者机器名,如果是机器名那么需要在/etc/hosts中有所设置。
Slaves中配置的是Slaves的ip或者机器名,同样如果是机器名需要在/etc/hosts中有所设置。
范例如下:我这里配置的都是ip.
根据每一个Slave的Java_HOME的不同修改其hadoop-env.sh。
可以通过使用命令:hadoop dfsadmin –report就可以看到各个节点存储的情况
Master和Slave机器上的/etc/hosts中必须把集群中机器都配置上去,就算在各个配置文件中使用的是ip。这个吃过不少苦头,原来以为如果配成ip就不需要去配置host,结果发现在执行Reduce的时候总是卡住,在拷贝的时候就无法继续下去,不断重试。另外如果集群中如果有两台机器的机器名如果重复也会出现问题。
Map的个数通常默认和HDFS需要处理的blocks相同
Hadoop dfs 这个命令后面加参数就是对于HDFS的操作,和Linux操作系统的命令很类似,例如:Hadoop dfs –ls 就是查看/usr/root目录下的内容,默认如果不填路径这就是当前用户路径Hadoop dfs –rmr xxx就是删除目录,还有很多命令看看就很容易上手
Hadoop dfsadmin –report 这个命令可以全局的查看DataNode的情况。Hadoop job 后面增加参数是对于当前运行的Job的操作,例如list,kill等
Hadoop balancer就是前面提到的均衡磁盘负载的命令。
1.
2.
a)
b)
c)
4.
5.
6.
7.
其实当你的数据量没有那么大的时候,这种分布式计算也就仅仅只是一个玩具而已,
文件复制数为1,blocksize 5M
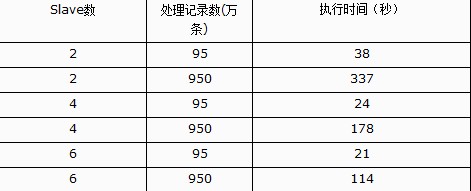
Blocksize 5M
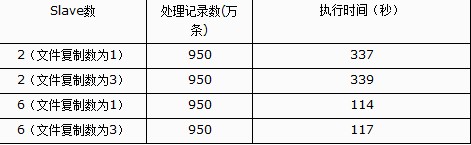
文件复制数为1

测试的数据结果很稳定,基本测几次同样条件下都是一样。
测试结果可以看出一下几点:
1.
2.
3.
4.
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/3691.html
摘要:年肖德时先生加入,担任内部工作组。老肖语录是肖德时先生推出的个人公众号栏目,他利用这个公众号记录自己创业路上的点点滴滴,不时会有精彩的技术感悟与分享,欢迎大家关注。 我今天看到一篇网友分享的 php 环境下的Docker持续集成案例。笔者大胆的试用后尝到了容器技术的甜头,也在文中提出了一个没有解决的困惑。 原来他是把代码放在容器外面,通过挂载目录的方法把代码加到容器里面运行的。这样虽然...
摘要:空谈是不值钱的。有能力的人一直在干活,没能力的人一直在抱怨。这种结果将会是完全无意中产生的副作用。真正的质量意味着让程序员为他们写的代码自豪,参与到编写代码之中并把它当做自己个人的事情。这就是这些纸张的价值所在。 My name is Linus Torvalds and I am your god.我的名字是Linus Torvalds,我是你们的上帝。(在1998 Linux大会上...
摘要:数据体积高达这种级别的数据仍然称不上大数据,当下的笔记本的内存都可以添加到了,而且许多工具并不是一次性将数据完全加载到内存的。大数据的有限价值今天我们几乎可以存储任何具有业务目的明显的数据,比如信用卡销售及问卷调查。 Hadoop只是运行某个通用计算的工具,正因为如此,在使用过程中你会受限于多种规则,比如所有计算都必须按照一个map、一个group by、一个aggregate或者这种计算序...
摘要:下次我会直接忽略你发的垃圾,懂以的咆哮量位居第三的是你要行动起来,对你应该管理的人施加压力。我只给出一个警告。 Linus Torvalds 想必大家并不陌生,不仅因为 Linux 之父的身份被人熟知,更是以火爆的脾气屡受争议,尤其是他在 2015 年曾对 NVIDIA 爆粗口、竖中指的行为...
摘要:月日下午,七牛云美图共享日在厦门举行,来自七牛云美图厦门大学罗普特等众位大咖齐聚一堂。七牛云美图共享日精华语录计算机识别是按照具体问题具体分析,具体场景具体分析。又称小牛汇共享日,是小牛汇举办的第一个系列活动。 时间机器、穿越星际的宇宙飞船、飞行汽车,几乎每一部科幻电影作品中都能发明点新东西。超现实技术在引起人们阵阵赞叹的同时,也在激励着人们思考如何将不可能变成可能。而在我们的生活当中...

阅读 844·2021-09-13 10:29
阅读 3270·2019-08-29 18:31
阅读 2502·2019-08-29 11:15
阅读 2894·2019-08-26 13:25
阅读 1190·2019-08-26 12:00
阅读 2109·2019-08-26 11:41
阅读 3007·2019-08-26 10:31
阅读 1321·2019-08-26 10:25

















