
摘要:索引树的作用是为了让快速找到对应的。这个图假设有个下标到,那么我们最终获得个样,即个样下标为的为最后一个样图中的圆圈,代表索引树上的节点,索引树共层。
1、1TB(或1分钟)排序的冠军
作为分布式数据处理的框架,集群的数据处理能力究竟有多快?或许1TB排序可以作为衡量的标准之一。
1TB排序,就是对1TB(1024GB,大约100亿行数据)的数据进行排序。2008年,Hadoop赢得1TB排序基准评估第一名,排序1TB数据耗时209秒。后来,1TB排序被1分钟排序所取代,1分钟排序指的是在一分钟内尽可能多的排序。2009年,在一个1406个节点组成的hadoop集群,在59秒里对500GB完成了排序;而在1460个节点的集群,排序1TB数据只花了62秒。
这么惊人的数据处理能力,是不是让你印象深刻呢?下面我们来看看排序的过程吧。
2、排序的过程
1TB的数据?100亿条数据?都是什么样的数据呢?让我们来看几条:
.t^#|v$2 0AAAAAAAAAABBBBBBBBBBCCCCCCCCCCDDDDDDDDDDEEEEEEEEEEFFFFFFFFFFGGGGGGGGGGHHHHHHHH
75@~?"WdUF 1IIIIIIIIIIJJJJJJJJJJKKKKKKKKKKLLLLLLLLLLMMMMMMMMMMNNNNNNNNNNOOOOOOOOOOPPPPPPPP
w[o||:N&H, 2QQQQQQQQQQRRRRRRRRRRSSSSSSSSSSTTTTTTTTTTUUUUUUUUUUVVVVVVVVVVWWWWWWWWWWXXXXXXXX
^Eu)
描述一下:每一行,是一条数据。每一条,由2部分组成,前面是一个由10个随即字符组成的key,后面是一个80个字符组成的value。
排序的任务:按照key的顺序排。
那么1TB的数据从何而来?答案是用程序随即生成的,用一个只有map,没有reduce的MapReduce job,在整个集群上先随即生成100亿行数据。然后,在这个基础上,再运行排序的MapReduce job,以测试集群排序性能。
3、排序的原理
先说明一点,熟悉MapReduce的人都知道:排序是MapReduce的天然特性!在数据达到reducer之前,mapreduce框架已经对这些数据按键排序了。
所以,在这个排序的job里,不需要特殊的Mapper和Reducer类。用默认的IdentityMapper和IdentityReducer即可。
既然排序是天然特性,那么1TB排序的难点在哪里呢??答:100亿行的数据随即分散在1000多台机器上,mapper和reducer都是Identity的,这个难点就在MapReduce的shuffle阶段!关键在如何取样和怎么写Partitioner。
好在这个排序的源代码已近包含在hadoop的examples里了,下面我们就来分析一下。
4、取样和partition的过程
面对对这么大量的数据,为了partition的更均匀。要先“取样”:
1) 对Math.min(10, splits.length)个split(输入分片)进行随机取样,对每个split取10000个样,总共10万个样
2) 10万个样排序,根据reducer的数量(n),取出间隔平均的n-1个样
3) 将这个n-1个样写入partitionFile(_partition.lst,是一个SequenceFile),key是取的样,值是nullValue
4) 将partitionFile写入DistributedCache
接下来,正式开始执行MapReduce job:
5) 每个map节点:
a.根据n-1个样,build一棵类似于B-数的“索引树”:
b.前缀相同的key,被分配到同一个叶子节点。
c.一个子节点上,可能有多个reducer
d.比第i个样小的key,被分配到第i个reducer,剩下的被分配到最后一个reducer。
6) 针对一个key,partition的过程:
a. 推荐判断key的第1个byte,找到第1层非叶子节点
b. 再根据key的第2个byte,叶子节点
c. 每个叶子节点可能对应多个取样(即多个reducer),再逐个和每个样比较,确定分配给哪一个reducer
5、图解partition的“索引树”
对上面的文字描述可能比较难理解,etongg 同学建议我画个图。所有才有了下面这些文字。感谢etongg和大家对本帖的关注。
“索引树”的作用是为了让key快速找到对应的reducer。下图是我画的索引树示意图:
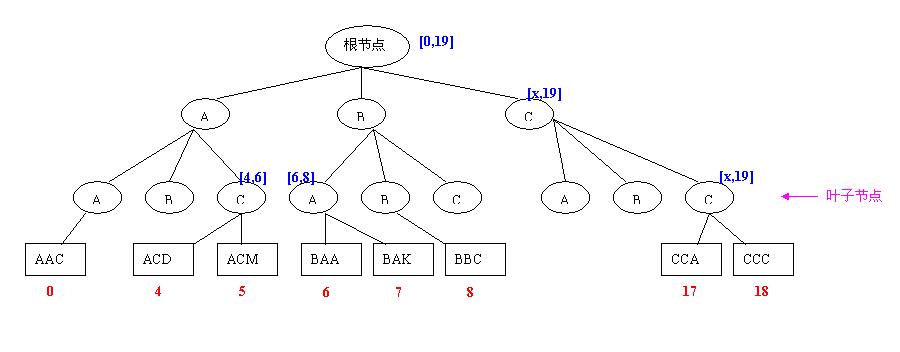
对上面的图做一点解释:
1、为了简单,我只画了A、B、C三个节点,实际的是有256个节点的。
2、这个图假设有20个reducer(下标0到19),那么我们最终获得n-1个样,即19个样(下标为18的为最后一个样)
3、图中的圆圈,代表索引树上的节点,索引树共3层。
4、叶子节点下面的长方形代表取样数组。红色的数字代表取样的下标。
5、每个节点都对应取样数组上的一个下标范围(更准备的说,是对应一个partition number的范围,每个partition number代表一个reducer)。这个范围在途中用蓝色的文字标识。
前面文中有一句话:
比第i个样小的key,被分配到第i个reducer,剩下的被分配到最后一个reducer
这里做一个小小的纠正,应该是:
小于或者等于第i个样的key,被分配到第i个reducer,剩下的被分配到最后一个reducer。
下面开始partition:
如果key以”AAA”开头,被分配到第“0”个reducer。
如果key以”ACA”开头,被分配到第“4”个reducer。
如果key以”ACD”开头,被分配到第“4”个reducer。
如果key以”ACF”开头,被分配到第“5”个reducer。
那么,
如果key以”ACZ”开头,被分配到第几个reducer??
答案是:被分配到第“6”个reducer。
同理,
如果key以”CCZ”开头,被分配到第“19”个reducer,也就是最后一个reducer。
6、为什么不用HashPartitioner?
还需要再说明的一点:
上面自定义的Partitinoner的作用除了快速找到key对应的reducer,更重要的一点是:这个Partitioner控制了排序的总体有序!
上文中提到的“排序是MapReduce的天然特性!”这句话有点迷惑性。更准确的说,这个“天然特性”只保证了:a) 每个map的输出结果是有序的; b) 每个reduce的输入是有序的(参考下面的图)。而1TB的整体有序还需要靠Partitioner的帮助!
Partitioner控制了相似的key(即前缀相同)落在同一个reducer里,然后mapreduce的“天然特性”再保证每个reducer的输入(在正式执行reduce函数前,有一个排序的动作)是有序的!
这样就理解了为什么不能用HashPartitioiner了。因为自定义的Partitioner要保证排序的“整体有序”大方向。
另外,推荐一篇关于partitioner博文:Hadoop Tutorial Series, Issue #2: Getting Started With (Customized) Partitioning
再贴《Hadoop.The.Definitive.Guide》中一张图,更有利于理解了:

文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/3726.html
摘要:英文原文随着的起步,云客户的增多面临的首要问题就是如何为他们新的的集群选择合适的硬件。为你的选择硬件选择机器配置类型的第一步就是理解你的运维团队已经在管理的硬件类型。 英文原文:How-to: Select the Right Hardware for Your New Hadoop Cluster 随着Apache Hadoop的起步,云客户的增多面临的首要问题就是如何为他们新的的Hado...
摘要:五我的数据超过了你应该考虑使用,而无需做过多的选择。使用的好处是可伸缩性非常好。如果你没有这样大数据量的表,那么你应该像躲避瘟疫那样避免使用。支持使用语言来编写任务链,隐藏了其下的。 有人问我,你在大数据和Hadoop方面有多少经验?我告诉他们,我一直在使用Hadoop,但是我处理的数据集很少有大于几个TB的。他们又问我,你能使用Hadoop做简单的分组和统计吗?我说当然可以,我只是告诉他们...
摘要:谈到应用,如果仅将目光集中在为搜索引擎提供动力或者为广告服提供用户行为分析的平台上,那么显然有所局限。个典型应用领域最近,在版本的发布会上,和业内一些专家指出了在不同领域的应用案例。这是的另一项匿名统计,为美国智能手机提供服务。 谈到Hadoop应用,如果仅将目光集中在为搜索引擎提供动力或者为广告服提供用户行为分析的平台上,那么显然有所局限。本文提供了搜索以及广告分析以外的10个应用领域,...
摘要:后来结局可能大家也猜到了,投入了很多钱,招了不少牛人,确实也做出了还算不错的云计算至少在国内是数一数二的。虽然我前公司这个云计算项目是否会成功,这里没办法预测,但是前途终究还是比较黯淡的。 写在前面的话: 今天听同事分享了一篇很有意思的讲座,叫做Why Map-Reduce Is Not The Solution To Your Big-Data Problem(为什么Map-Redu...
摘要:的带宽虽然不常见,但是却能显著的提高核心和磁盘驱动器的密集性。更多的核心和磁盘驱动器,意味着数据能得到更多的并行处理能力和更快的结果。就是在你的机器扩展更多个磁盘驱动器和更多的核心,而不是增加机器的数量。 本文将着重于讨论Hadoop集群的体系结构和方法,及它如何与网络和服务器基础设施的关系。最开始我们先学习一下Hadoop集群运作的基础原理。 Hadoop里的服务器角色 Hadoop主要...

阅读 1643·2021-11-19 09:40
阅读 2425·2021-08-30 09:46
阅读 2028·2021-08-03 14:01
阅读 2532·2019-08-30 10:54
阅读 1059·2019-08-29 16:38
阅读 1337·2019-08-29 11:02
阅读 2425·2019-08-28 18:16
阅读 1548·2019-08-28 18:09

















