
摘要:本文为家族开篇,家族学习路线图目录家族产品家族学习路线图家族产品截止到年,根据的统计,家族产品已经达到个接下来,我把这个产品,分成了类。家族学习路线图下面我将分别介绍各个产品的安装和使用,以我经验总结我的学习路线。
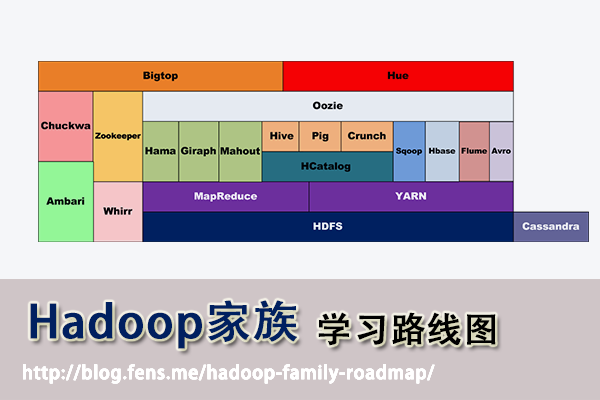
Hadoop家族系列文章, 主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, Pig, HBase, Sqoop, Mahout, Zookeeper, Avro, Ambari, Chukwa,新增加的项目包括,YARN, Hcatalog, Oozie, Cassandra, Hama, Whirr, Flume, Bigtop, Crunch, Hue等。
从2011年开始,中国进入大数据风起云涌的时代,以Hadoop为代表的家族软件,占据了大数据处理的广阔地盘。开源界及厂商,所有数据软件,无 一不向Hadoop靠拢。Hadoop也从小众的高富帅领域,变成了大数据开发的标准。在Hadoop原有技术基础之上,出现了Hadoop家族产品,通 过“大数据”概念不断创新,推出科技进步。
作为IT界的开发人员,我们也要跟上节奏,抓住机遇,跟着Hadoop一起雄起!
关于作者:
转载请注明出处:
http://blog.fens.me/hadoop-family-roadmap/
前言
使用Hadoop已经有一段时间了,从开始的迷茫,到各种的尝试,到现在组合应用….慢慢地涉及到数据处理的事情,已经离不开hadoop了。Hadoop在大数据领域的成功,更引发了它本身的加速发展。现在Hadoop家族产品,已经达到20个了之多。
有必要对自己的知识做一个整理了,把产品和技术都串起来。不仅能加深印象,更可以对以后的技术方向,技术选型做好基础准备。
本文为“Hadoop家族”开篇,Hadoop家族学习路线图
目录
截止到2013年,根据cloudera的统计,Hadoop家族产品已经达到20个!
http://blog.cloudera.com/blog/2013/01/apache-hadoop-in-2013-the-state-of-the-platform/
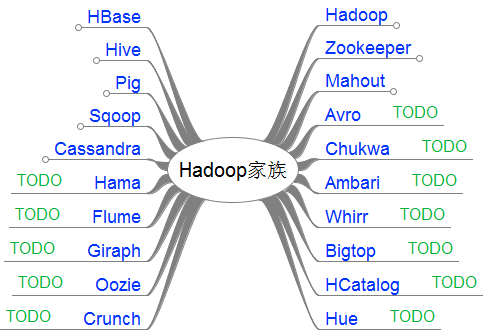
接下来,我把这20个产品,分成了2类。
一句话产品介绍:
下面我将分别介绍各个产品的安装和使用,以我经验总结我的学习路线。
Hadoop
Hive
Pig
Zookeeper
HBase
Mahout
Sqoop
Cassandra
跟上创新的脚步,不断坚持:(TODO列表,不定期更新)
Avro, Ambari, Chukwa, Hama, Flume, Giraph, Oozie, Crunch, Whirr, Bigtop, HCatalog, Hue
欢迎大家留言,提出宝贵建议!
转载请注明出处:
http://blog.fens.me/hadoop-family-roadmap/
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/3813.html
摘要:就是训象人,在上创造新的智慧目录介绍学习路线图我的学习经历的使用案例介绍是基于的机器学习和数据挖掘的一个分布式框架。学习路线图知识点,我已经列在图中,希望帮助其他人更好的了解。 Hadoop家族系列文章, 主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, Pig, HBase, Sqoop, Mahout, Zookeeper, Avro, Ambari, Chukw...
摘要:表示公司招募了一些数据科学家,最初我认为他们可以用已有的技术配合机器学习等技术来改善算法。从开始的技术人生集群软件语言预测分析以及机器学习等技术的引入对的基础架构是一次巨大的飞跃,在此之前他们一直在使用基于规则的系统。 对于Ancestry.com(家谱网)的 技术总监Scott Sorensen来说,大数据其实并不陌生。长久以来,Sorensen和他的同事都在使用Apache Hado...
摘要:看看上的情况找到下载源代码查看用源代码构建环境注上面,包结构已经完全改变,用代替了的构建过程。查看生成的目录发现都是结尾的,合理的解释就是上一个版本的就是下一个版本的。 Hadoop家族系列文章, 主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, Pig, HBase, Sqoop, Mahout, Zookeeper, Avro, Ambari, Chukwa,新增...
摘要:作为界的开发人员,我们也要跟上节奏,抓住机遇,跟着一起雄起关于作者张丹程序员转载请注明出处前言全称分步文件系统,是的核心部分之一。 Hadoop编程调用HDFS Hadoop家族系列文章, 主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, Pig, HBase, Sqoop, Mahout...

阅读 1129·2021-11-25 09:43
阅读 3990·2021-11-23 09:51
阅读 536·2021-11-18 10:02
阅读 2682·2021-09-07 09:59
阅读 2630·2021-08-30 09:44
阅读 2805·2019-08-30 13:17
阅读 2112·2019-08-29 12:17
阅读 1586·2019-08-28 17:57

















