
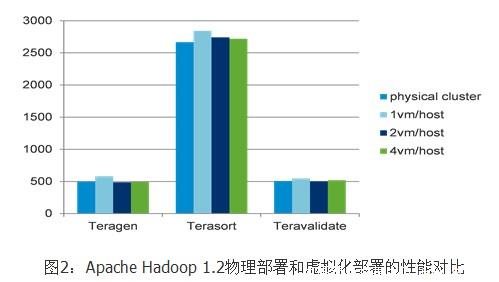
摘要:虚拟化环境和物理环境的性能对比图显示了性能调优试验的部署样式,一台物理服务器上只部署一台虚拟机,和一起跑在同一个节点中。试验结果在图中显示,虚拟化相对于物理环境的性能对比几乎是持平的。
Hadoop和其他消耗不同类型资源的应用一起部署共享数据中心可以提高总体资源利用率;
·灵活的虚拟机操作使得用户可以动态的根据数据中心资源创建、扩展自己的Hadoop集群,也可以缩小当前集群、释放资源支持其他应用如果需要;
·通过与虚拟化架构提供的HA、FT集成,避免了传统Hadoop集群中的单点失败,再加之Hadoop本身的数据可靠性,为企业大数据应用提供了可靠保证。
基于这些原因,vSphere Big Data Extensions(BDE)为用户在虚拟化环境中灵活的部署和管理Hadoop集群提供了有效的支持。除却这些优势,虚拟化是否会伤害Hadoop运 行的性能呢?为此,我们在同等规模上做了虚拟化部署和物理部署的Hadoop集群的性能对比和优化,实验表明虚拟化Hadoop集群可以很好地支持生产环 境。
虚拟化环境和物理环境的性能对比
图1显示了性能调优试验的部署样式,一台物理服务器上只部署一台虚拟机,Tasktracker和Datanode一起跑在同一个节点中。因为 每个 虚拟节点可以使用全部的服务器资源,方便进行虚拟化和传统物理环境部署的Hadoop做性能对比和分析。试验结果在图2中显示,虚拟化Hadoop相对于 物理环境的性能对比几乎是持平的。
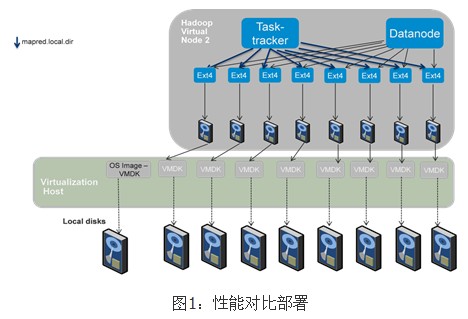

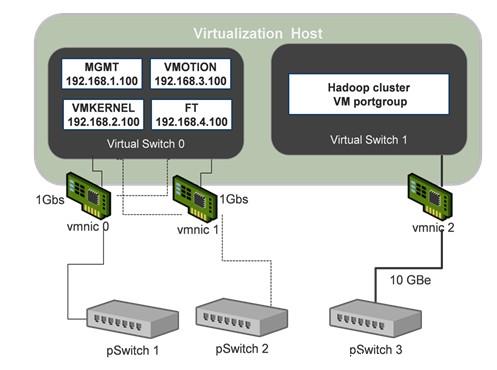
(5)Hadoop配置: BDE将会自动产生并配置hadoop配置文件(主要在map- site.xml,core-site.xml,和 hdfs-site.xml内),包括块大小(blocksize),会话管理和日志功能。但是有一些相关于MapReduce任务的参数,包括 mapred.reduce.parallel.copies,io.sort.mb,io.sort.factor,io.sort.record.percent, 和tasktracker.http.thread,需要根据不同负载具体设置。
(6)扩展建议:如果用户观察集群中CPU的利用率经常超过80%,建议加入新的节点。另外单个存贮节点的容量不建议超过24TB,否则一旦节点失败,数据备份拷贝容易造成数据拥塞。扩展可以按照小规模集群上运行性能基准经验和资源使用情况进行。
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/3851.html
摘要:那么,什么样的机遇能够带来最好的结果如何确保能取得成功的结果呢英特尔为此提出了一套概念验证的解决方案,并且详细撰写了一套白皮书,能够帮助决策者回答这些问题,同时最大化价值,最小化风险。 showImg(http://upload-images.jianshu.io/upload_images/13825820-5ded473acf69a9d1.jpg?imageMogr2/auto-o...

摘要:恢复回收站数据二集群压测在企业中非常关心每天从后台拉取过来的数据,需要多久能上传到集群消费者关心多久能从上拉取需要的数据为了搞清楚的读写性能,生产环境上非常需要对集群进行压测。 一、HDFS核心参数1.1 NameNode内存生产配置1. NameNode 内存计算 每个文件块大概占用 150byte,一台服...
摘要:下面我们就将一起探讨如何将深度学习最前沿的机器学习框架部署到的集群中。更进一步,可以利用来将任何适合的机器学习算法进行分布计算。能够利用通用的集群平台将极大的利于在大数据上运行可扩展的机器学习算法。 位于波士顿的数据科学团队正在利用前沿的工具和算法,通过对用户数据的分析来优化业务行为。 数据科学很大程度上依赖机器算法,它能帮助我们发现数据的特征。要想洞察互联网般规模的数据还是很有挑战的,因此...
摘要:且系统会出现严重过载情况。对于这个程序来说调整为的时候需要小时分钟。从这个结果可知对于该平台的应该是才是最优的。结论在调优这块,有很多现成的经验可供参考。但是对于具体应用,我们应该根据实际,利用性能监控工具来调整参数。 利用ganglia 监控集群状态为调优提供依据 单位同事在对Hadoop集群调优的时候,大多数看中的是个体.看中的是本段代码的执行情况.而很少从整集群的...
摘要:关于快杰云主机的性能表现,已在阿里云腾讯云华为云云主机对比测试报告中详细测试对比过,其对数据库的支持能力尤为突出。快杰经过此次架构和硬件升级,无论是对比自建,还是友商同等配置下的,其高性能和高性价比都是企业部署高性能数据库的优秀选择。2020年4月中旬,UCloud云数据库产品线发布了MySQL版本的快杰UDB,作为UDB产品架构升级后的最新一代云数据库,快杰UDB采用了业内主流的计算存储分...

阅读 2302·2021-11-22 09:34
阅读 3346·2021-11-15 11:37
阅读 2048·2021-09-13 10:37
阅读 1930·2021-09-04 16:40
阅读 1172·2021-09-02 15:40
阅读 2351·2019-08-30 13:14
阅读 3194·2019-08-29 13:42
阅读 1740·2019-08-29 13:02

















