
摘要:下面我们就将一起探讨如何将深度学习最前沿的机器学习框架部署到的集群中。更进一步,可以利用来将任何适合的机器学习算法进行分布计算。能够利用通用的集群平台将极大的利于在大数据上运行可扩展的机器学习算法。
位于波士顿的数据科学团队正在利用前沿的工具和算法,通过对用户数据的分析来优化业务行为。 数据科学很大程度上依赖机器算法,它能帮助我们发现数据的特征。要想洞察互联网般规模的数据还是很有挑战的,因此能够大规模的运行算法成为了我们的关键需求。随着数据的爆炸性增长,以及随之而来的上千节点集群,我们需要将算法的运行适配到分布式环境。在通用的分布式计算环境中运行机器学习算法,这本身有它自己的挑战。
下面我们就将一起探讨如何将深度学习(最前沿的机器学习框架)部署到Hadoop的集群中。还将提供如何对算法进行修改以便适应分布式环境。同时还将展示在标准数据集下的运行结果。
深度信念网
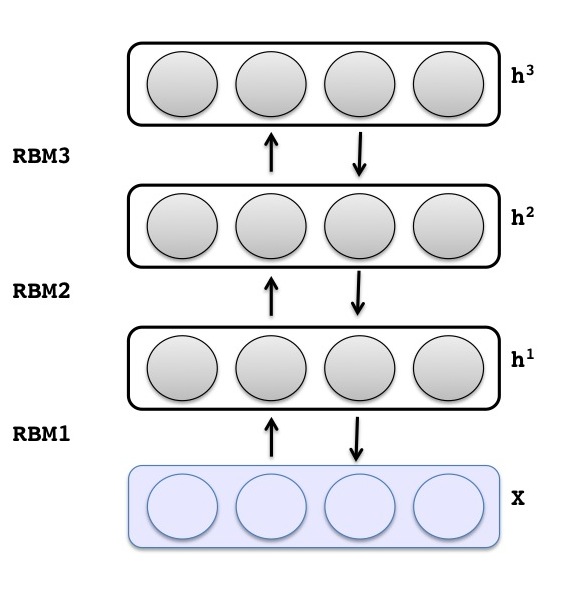
深度信念网(DBN)是一种图模型,可以通过对受限玻尔兹曼机(RBM)以贪婪和无监督的方式进行叠加和训练获得。采用对被观察的x向量和第I隐层的接点进行建模的方式,我们可以训练DBN来提取训练数据的深度层级表示, 这里每个隐层的分布基于它紧邻的上一层的条件。

可以从下图中观察输入层和隐层的关系。从总体上看,第一层被训练成RBM,它为x的原始输入建模。一个输入是指代表一组未分类数据的稀疏二进制向量,比如一个数字的二进制图像。接下来的层采用变换后的数据(sample or mean activations)进行训练,这些数据来自于上一层。层的数量可以基于经验来选取以便获得较好的模型效果,而且DBN也支持任意数量的层。
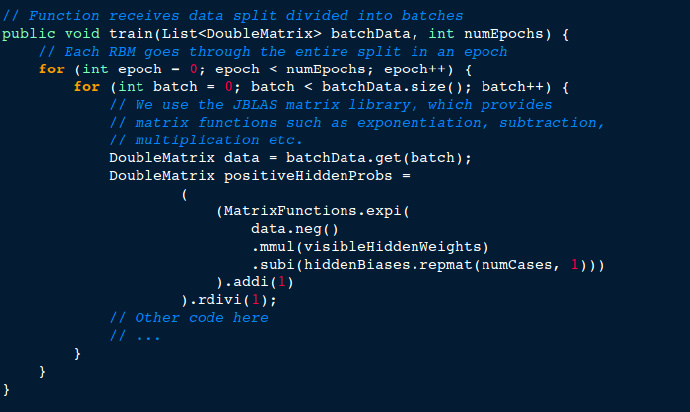
下面的代码段展示了进入RBM的训练。对于RBM的输入数据,这里有多次预定义的迭代(epochs). 输入数据被分成小的批次,并计算出每一层的权重(weight),激活值(activations)和增量(deltas)。
每一层的训练都完成后,深度网络的参数都采用受监督的训练标准进行了调优。举例来说,受监督的标准(criterion), 可以分解为一个分类问题,然后可以用深度网络来解决分类问题。也可以使用更复杂的受监督标准,通过它我们可以获得诸如场景解析的有趣结果,比如可以解释图片上出现了那些对象。
Infrastructure
深度学习获得的广泛关注,不仅因为它能提供优于其他学习算法的结果,还因为它能运行在一个分布式环境从而能处理大规模的数据。深度网络主要从两个级别来并行化 – 层级和数据级。对于层级的并行化实现,大多数采用GPU阵列来并行计算层激活值并对它们进行频繁的同步。然而这种方式对于集群环境不合适,因为当数据分散在多个通过网络连接节点时,会产生较高的网络开销。数据并行化是指通过将数据拆分来进行并行训练,分布式环境更适合采用这种方式。Paypal的大部分数据存放在hadoop集群里,因此我们的首要需求是能够在集群里运行算法。对集群的针对性维护和支持也是我们要考虑的因素。鉴于深度学习天生就继承了迭代性,MapReduce模式可能不太适合运行这些算法。然而Hadoop 2.0 和 基于Yarn的资源管理出现后,我们就可以写出迭代式应用,因为我们可以很好的控制应用占用的资源。我们使用了IterativeReduce, 它是一个在Hadoop YARN里写迭代式算法的一个简单抽象,然后我们就能把它部署到某个运行Hadoop 2.4.1的Paypal集群里。
方法论
我们实现了Hinton的核心深度学习算法。这是因为考虑到我们需要把算法分布到多个机器中去。对于多台机器的算法分布过程,我们采用了Grazia推荐的手册。下面是对我们实现的一个大概总结:
主节点初始化RBM权重。
主节点把权重和分配推送到工作节点
工作节点对一个数据段进行RBM训练,也就是执行完整个分片,将更新后的权重返回给主节点
主节点针对某个数据段把所有工作接点的权重进行平均。
对于预先定于的分段重复3-5步(我们采用的是50)
等到第6步完成后,一个层就训练完了。对后面的RBM层重复以上步骤。
等到所有层的训练完成后,深度网络就已经采用Error Back-propagation进行了调优。
下图展示了单个数据段在运行深度学习时的过程。我们注意到可以采用这套概念来实现一个本质上具有迭代性的机器学习主机

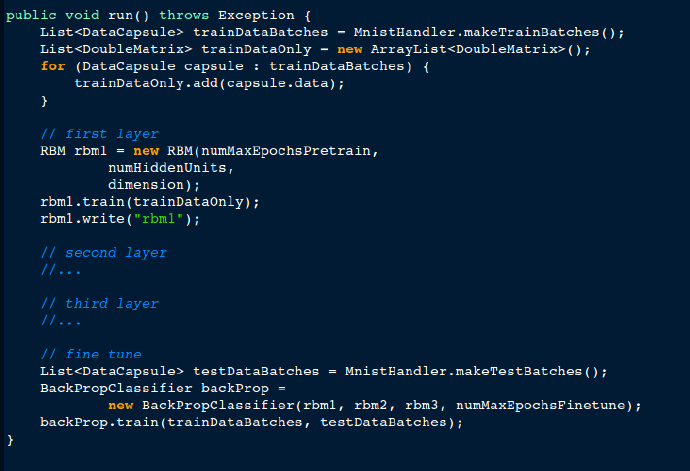
下面的代码段展示了单机训练DBN的步骤。数据集首先被分批,然后初始化多个RBM层,接着进行训练。RBM训练完成后,采用error back propagation进行调优。
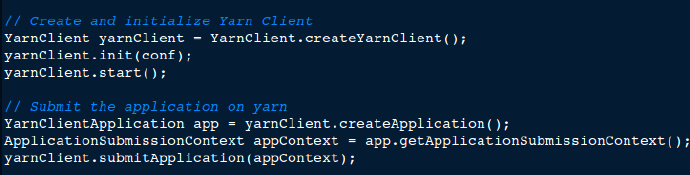
我们使用IterativeReduce的实现与YARN进行了大量适配。并且对实现进行了很多修改以便适用于深度学习。IterativeReduce实现是为Cloudera Hadoop 写的, 我们将它改造成适用于通用的Apache Hadoop 平台。 我们还重写了标准程序模型。特别要提到的是,客户端程序和ResourceManager之间通信采用了YarnClient API。还采用了AMRMClient和AMNMClient在ApplicationMaster和ResourceManager以及NodeManager之间通信。
首先我们使用YarnClient API将程序提交给YARN resource manager
提交之后,YARN resource manager 运行 application master,它将根据需要负责分配和释放工作节点容器。 application master采用AMRMClient与resource manager进行通信。
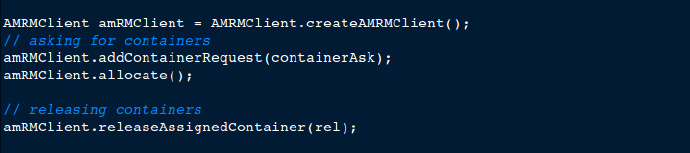
application master 采用 NMClient API在容器中运行来自application master的命令。
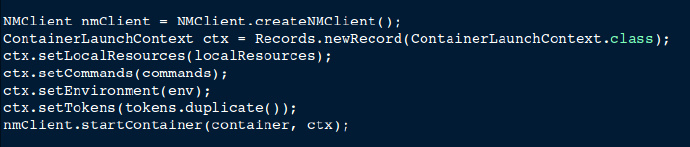
application master运行工作节点容器后,它会立即设置端口用来和工作节点通信。对于我们的深度学习来说,我们给原本的IterativeReduce接口添加了一些方法,用来实现参数初始化,逐层训练和微调信号。IterativeReduce采用Apache Avro IPC进行主节点-工作节点通信。
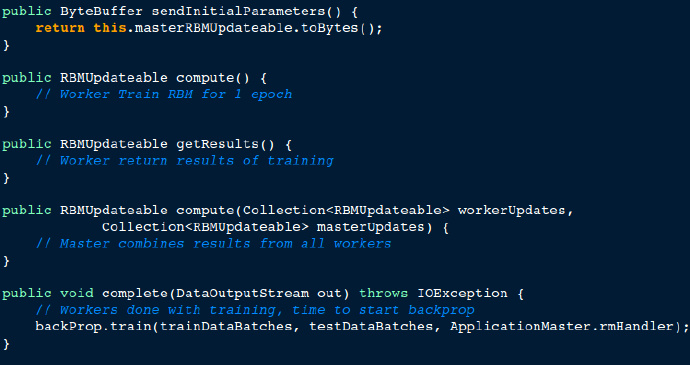
下面的代码段展示了主节点-工作节点在分布式训练中的一系列步骤。主节点把初始参数发送给工作节点,然后工作节点基于自己的数据对RBM进行训练。训练完成后,它将结果发送给主节点,主节点会将结果进行合并。整个迭代完成后,主节点开始back propagation(反向传播算法)微调阶段,标志着主节点流程结束。
结果
我们采用MNIST手写数字识别来评估深度学习的性能。 数据集包含介于0-9之间的手写数字,它们都已经包含一个标签。训练数据包含 60,000张图片,测试数据包含10,000张图片。
为了对结果进行评估, DBN事先进行了训练,然后用60000张训练图片进行微调。进过上述步骤后,用10000张测试图片来进行评估。 在训练和测试过程中,图片没进行任何预处理。 通过分类错误的图片和图片总数就能获得错误率。
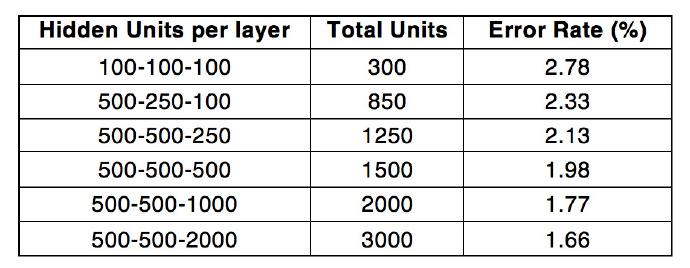
通过采用每层RBM还有500-500-2000 隐藏units的RBM以及10个节点的分布式设置,我们能达到最优的1.66%的错误率。把这个错误率和算法的原作者报告的1.2%错误率进行对比,以及其他一些类似的结果对比,我们注意到原本的实现是基于单机的,而我们的实现是基于分布式环境的。参数平均化(parameter-averaging)步骤稍微降低了性能,然而多台机器的分布式计算带来的优势远远超过其瑕疵。下表总结了基于10个节点时每层含有的隐藏单位数与错误率之间的变化关系。
下一步想法
我们已经成功部署了一个分布式的深度学习系统。我相信这有助于我们解决机器学习的一些问题。更进一步,可以利用iterative reduce abstraction来将任何适合的机器学习算法进行分布计算。能够利用通用的Hadoop集群平台将极大的利于在大数据上运行可扩展的机器学习算法。我们注意到目前的框架还有很多值得改进的地方,主要集中在降低网络延迟和更高级的资源管理。另外像我们希望优化DBN框架以便减少节点内通信。Hadoop Yarn框架带有更精细的集群资源控制,它能为我们提供这种灵活性。
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/3925.html
摘要:简称是为和编写的较早的商业级开源分布式深度学习库。这一灵活性使用户可以根据所需,在分布式生产级能够在分布式或的基础上与和协同工作的框架内,整合受限玻尔兹曼机其他自动编码器卷积网络或递归网络。 Deeplearning4j(简称DL4J)是为Java和Scala编写的较早的商业级开源分布式深度学习库。DL4J与Hadoop和Spark集成,为商业环境(而非研究工具目的)所设计。Skymind是...
摘要:虽然广受欢迎,但是仍受到来自另外一个基于的机器学习库的竞争年出现的。还提供更传统的机器学习功能的库,包括神经网络和决策树系统。和的机器学习库。顾名思义,是用于神经网络机器学习的库,便于将浏览器用作数据工作台。 关于机器学习的11个开源工具 翻译:疯狂的技术宅英文标题:11 open source tools to make the most of machine learning英文连...
摘要:机器学习的开源项目除了之前的等,今年发生了很多令人瞩目的大事,迎来了数个明星巨头的重磅加入年月,开源前沿深度学习工具。由一个服务于分布式机器学习的框架和一组分布式机器学习算法组成,可将机器学习算法应用到大数据中。 本文分为技术篇、产业篇、应用篇、展望篇四部分技术篇2006年项目成立的一开始,Hadoop这个单词只代表了两个组件——HDFS和MapReduce。到现在的10个年头,这个单词代表...
摘要:在一个完美的大数据环境下,及时向用户道歉也能给客户留下很好的影响。受益于的更新,现在将支持和快照处理,这意味着企业客户在出现问题时可以回滚。比如查询工具来自于年对的收购来自于同年对的收购。 【编者按】Pivotal公司由EMC和Vmware部分业务分拆合并而成,Pivotal通过不断吸收新技术并将新技术融合到自己的产品中而成长壮大,现在Pivotal还很好地利用开源力量完善自身的产品,P...
摘要:大数据通常是不确定的,而多数处理框架已经适应了这一特性。正如其名,大数据通常以其大量的数据为特征,而这要求巨大乃至理论上无限的存储容量。栈是大数据处理框架的祖师爷,并且已经成为这些技术汇集的事实上的平台。 欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文讨论大数据处理生态系统和相关的架构栈,包括对适应于不同任务的多种框架特性的调研。除此之外,文章还从多个层次对框架进行...

阅读 1773·2021-10-12 10:11
阅读 2265·2021-10-09 09:59
阅读 1927·2021-09-23 11:30
阅读 2361·2019-08-30 15:56
阅读 1034·2019-08-30 14:00
阅读 2802·2019-08-29 12:37
阅读 1050·2019-08-28 18:16
阅读 1555·2019-08-27 10:56











