
摘要:我们很自然地想到将数据一条条插入到中,或者通过方式等。本文将针对这个问题介绍如何通过的方法来快速将海量数据导入到中。这一步是最简单的,通常需要使用更为人所熟知是工具,将文件在上的位置传递给它,它就会利用将数据导入到相应的区域。
在第一次建立HBase表的时候,我们可能需要往里面一次性导入大量的初始化数据。我们很自然地想到将数据一条条插入到Hbase中,或者通过MR方式等。但是这些方式不是慢就是在导入的过程的占用Region资源导致效率低下,所以很不适合一次性导入大量数据。本文将针对这个问题介绍如何通过Hbase的BulkLoad方法来快速将海量数据导入到Hbase中。
总的来说,使用 Bulk Load 方式由于利用了 HBase 的数据信息是按照特定格式存储在 HDFS 里的这一特性,直接在 HDFS 中生成持久化的 HFile 数据格式文件,然后完成巨量数据快速入库的操作,配合 MapReduce 完成这样的操作,不占用 Region 资源,不会产生巨量的写入 I/O,所以需要较少的 CPU 和网络资源。Bulk Load 的实现原理是通过一个 MapReduce Job 来实现的,通过 Job 直接生成一个 HBase 的内部 HFile 格式文件,用来形成一个特殊的 HBase 数据表,然后直接将数据文件加载到运行的集群中。与使用HBase API相比,使用Bulkload导入数据占用更少的CPU和网络资源。
实现原理
Bulkload过程主要包括三部分:
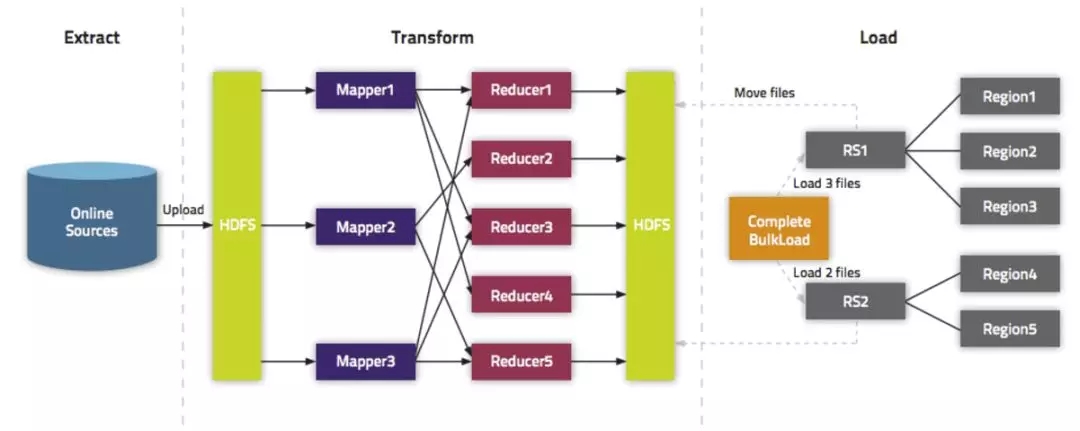
1、从数据源(通常是文本文件或其他的数据库)提取数据并上传到HDFS。抽取数据到HDFS和Hbase并没有关系,所以大家可以选用自己擅长的方式进行,本文就不介绍了。
2、利用MapReduce作业处理事先准备的数据 。这一步需要一个MapReduce作业,并且大多数情况下还需要我们自己编写Map函数,而Reduce函数不需要我们考虑,由HBase提供。该作业需要使用rowkey(行键)作为输出Key;KeyValue、Put或者Delete作为输出Value。MapReduce作业需要使用HFileOutputFormat2来生成HBase数据文件。为了有效的导入数据,需要配置HFileOutputFormat2使得每一个输出文件都在一个合适的区域中。为了达到这个目的,MapReduce作业会使用Hadoop的TotalOrderPartitioner类根据表的key值将输出分割开来。HFileOutputFormat2的方法configureIncrementalLoad()会自动的完成上面的工作。
3、告诉RegionServers数据的位置并导入数据。这一步是最简单的,通常需要使用LoadIncrementalHFiles(更为人所熟知是completebulkload工具),将文件在HDFS上的位置传递给它,它就会利用RegionServer将数据导入到相应的区域。
整个过程图如下:
代码实现
上面我们已经介绍了Hbase的BulkLoad方法的原理,我们需要写个Mapper和驱动程序,实现如下:
使用MapReduce生成HFile文件

驱动程序

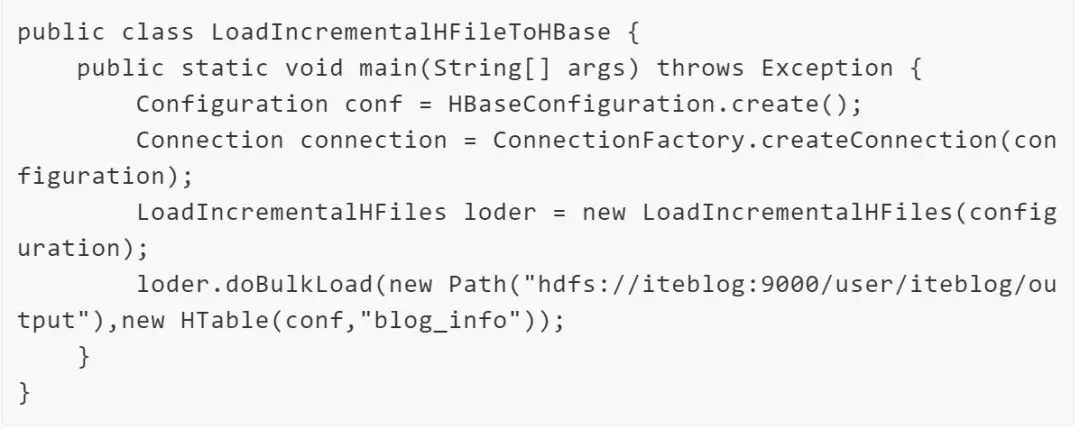
通过BlukLoad方式加载HFile文件
由于Hbase的BulkLoad方式是绕过了Write to WAL,Write to MemStore及Flush to disk的过程,所以并不能通过WAL来进行一些复制数据的操作。后面我将会再介绍如何通过Spark来使用Hbase的BulkLoad方式来初始化数据。
BulkLoad的使用案例
1、首次将原始数据集载入 HBase- 您的初始数据集可能很大,绕过 HBase 写入路径可以显著加速此进程。
2、递增负载 - 要定期加载新数据,请使用 BulkLoad 并按照自己的理想时间间隔分批次导入数据。这可以缓解延迟问题,并且有助于您实现服务级别协议 (SLA)。但是,压缩触发器就是 RegionServer 上的 HFile 数目。因此,频繁导入大量 HFile 可能会导致更频繁地发生大型压缩,从而对性能产生负面影响。您可以通过以下方法缓解此问题:调整压缩设置,确保不触发压缩即可存在的较大 HFile 文件数很高,并依赖于其他因素,如 Memstore 的大小 触发压缩。
3、数据需要源于其他位置 - 如果当前系统捕获了您想在 HBase 中包含的数据,且因业务原因需要保持活动状态,您可从系统中将数据定期批量加载到 HBase 中,以便可以在不影响系统的前提下对其执行操作。
声明:文章收集于网络,如有侵权,请联系小编及时处理,谢谢!
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/3929.html
摘要:摘要第九届中国数据库技术大会,阿里巴巴技术专家孟庆义对阿里的数据管道设施实践与演进进行了讲解。它必须在把风险做完,风控是根据长期的历史信息近期历史的信息和实时的信息三个方向做综合考量。 摘要:第九届中国数据库技术大会,阿里巴巴技术专家孟庆义对阿里HBase的数据管道设施实践与演进进行了讲解。主要从数据导入场景、 HBase Bulkload功能、HImporter系统、数据导出场景、H...
摘要:摘要第九届中国数据库技术大会,阿里巴巴技术专家孟庆义对阿里的数据管道设施实践与演进进行了讲解。它必须在把风险做完,风控是根据长期的历史信息近期历史的信息和实时的信息三个方向做综合考量。 摘要:第九届中国数据库技术大会,阿里巴巴技术专家孟庆义对阿里HBase的数据管道设施实践与演进进行了讲解。主要从数据导入场景、 HBase Bulkload功能、HImporter系统、数据导出场景、H...
摘要:为了避免这种情况,可以针对表短期内被两个以上的语句所加载执行一个大的数据压缩。通常,对一张大表执行数据压缩会花费大量的时间几分钟到几小时不等。 本文介绍了如何将数据从现有的RDBMS迁移到Trafodion数据库。从其它的RDBMS或外部数据源向Trafodion集群中导入大量的重要数据,可以通过下面两步完美实现: 在Trafodion集群中,将数据从源头导入Hive表。使用下列方...
摘要:为了避免这种情况,可以针对表短期内被两个以上的语句所加载执行一个大的数据压缩。通常,对一张大表执行数据压缩会花费大量的时间几分钟到几小时不等。 本文介绍了如何将数据从现有的RDBMS迁移到Trafodion数据库。从其它的RDBMS或外部数据源向Trafodion集群中导入大量的重要数据,可以通过下面两步完美实现: 在Trafodion集群中,将数据从源头导入Hive表。使用下列方...
摘要:是中分布式存储和负载均衡的最小单元,即不同的可以分别在不同的上,但同一个是不会拆分到多个上。目前会有一个线程来负责的操作。当文件的数量增长到一定阈值后,系统会进行合并,在合并过程中会进行版本合并和删除工作,形成更大的。 简介 hbase是大数据hadoop的数据库 存储数据 支持海量数据的存储 hbase是构建在hdfs上的分布式数据库 检索数据 hbase支持对存储在hbase表中...

阅读 747·2023-04-25 17:51
阅读 2595·2021-11-23 09:51
阅读 862·2021-11-15 11:38
阅读 1242·2021-11-08 13:21
阅读 2070·2021-09-22 15:14
阅读 2559·2020-12-03 17:30
阅读 1353·2019-08-30 12:48
阅读 942·2019-08-29 12:44

















