
摘要:机架内的机器之间的网络速度通常都会高于跨机架机器之间的网络速度,并且机架之间机器的网络通信通常受到上层交换机间网络带宽的限制。第二个副本放置在与第一个节点不同的机架中的中随机选择。配置默认情况下,的机架感知是没有被启用的。
背景
分布式的集群通常包含非常多的机器,由于受到机架槽位和交换机网口的限制,通常大型的分布式集群都会跨好几个机架,由多个机架上的机器共同组成一个分布式集群。机架内的机器之间的网络速度通常都会高于跨机架机器之间的网络速度,并且机架之间机器的网络通信通常受到上层交换机间网络带宽的限制。
具体到Hadoop集群,由于hadoop的HDFS对数据文件的分布式存放是按照分块block存储,每个block会有多个副本(默认为3),并且为了数据的安全和高效,所以hadoop默认对3个副本的存放策略为:
第一个block副本放在和client所在的node里(如果client不在集群范围内,则这第一个node是随机选取的)。
第二个副本放置在与第一个节点不同的机架中的node中(随机选择)。
第三个副本 放置在与第二个副本所在节点同一机架的另一个节点上
如果还有更多的副本就随机放在集群的node里。
这样的策略可以保证对该block所属文件的访问能够优先在本rack下找到,如果整个rack发生了异常,也可以在另外的rack上找到该block的副本。这样足够的高效,并且同时做到了数据的容错。
但是,hadoop对机架的感知并非是自适应的,亦即,hadoop集群分辨某台slave机器是属于哪个rack并非是只能的感知的,而是需要hadoop的管理者人为的告知hadoop哪台机器属于哪个rack,这样在hadoop的namenode启动初始化时,会将这些机器与rack的对应信息保存在内存中,用来作为对接下来所有的HDFS的写块操作分配datanode列表时(比如3个block对应三台datanode)的选择datanode策略,做到hadoop allocate block的策略:尽量将三个副本分布到不同的rack。
接下来的问题就是:通过什么方式能够告知hadoop namenode哪些slaves机器属于哪个rack?以下是配置步骤。
配置
默认情况下,hadoop的机架感知(Rack Awareness)是没有被启用的。所以,在通常情况下,hadoop集群的HDFS在选机器的时候,是随机选择的,也就是说,很有可能在写数据时,hadoop将第一块数据block1写到了rack1上,然后随机的选择下将block2写入到了rack2下,此时两个rack之间产生了数据传输的流量,再接下来,在随机的情况下,又将block3重新又写回了rack1,此时,两个rack之间又产生了一次数据流量。在job处理的数据量非常的大,或者往hadoop推送的数据量非常大的时候,这种情况会造成rack之间的网络流量成倍的上升,成为性能的瓶颈,进而影响作业的性能以至于整个集群的服务。
要将hadoop机架感知的功能启用,配置非常简单,在namenode所在机器的hadoop-site.xml配置文件中配置一个选项:
这个配置选项的value指定为一个可执行程序,通常为一个脚本,该脚本接受一个参数,输出一个值。接受的参数通常为某台datanode机器的ip地址,而输出的值通常为该ip地址对应的datanode所在的rack,例如”/rack1”。Namenode启动时,会判断该配置选项是否为空,如果非空,则表示已经用机架感知的配置,此时namenode会根据配置寻找该脚本,并在接收到每一个datanode的heartbeat时,将该datanode的ip地址作为参数传给该脚本运行,并将得到的输出作为该datanode所属的机架,保存到内存的一个map中。
至于脚本的编写,就需要将真实的网络拓朴和机架信息了解清楚后,通过该脚本能够将机器的ip地址正确的映射到相应的机架上去。一个简单的实现如下:
#!/usr/bin/python
#-*-coding:UTF-8 -*-
import sys
rack = {"hadoopnode-176.tj":"rack1",
"hadoopnode-178.tj":"rack1",
"hadoopnode-179.tj":"rack1",
"hadoopnode-180.tj":"rack1",
"hadoopnode-186.tj":"rack2",
"hadoopnode-187.tj":"rack2",
"hadoopnode-188.tj":"rack2",
"hadoopnode-190.tj":"rack2",
"192.168.1.15":"rack1",
"192.168.1.17":"rack1",
"192.168.1.18":"rack1",
"192.168.1.19":"rack1",
"192.168.1.25":"rack2",
"192.168.1.26":"rack2",
"192.168.1.27":"rack2",
"192.168.1.29":"rack2",
}
if __name__=="__main__":
print "/" + rack.get(sys.argv[1],"rack0")
由于没有找到确切的文档说明 到底是主机名还是ip地址会被传入到脚本,所以在脚本中较好兼容主机名和ip地址,如果机房架构比较复杂的话,脚本可以返回如:/dc1/rack1 类似的字符串。
执行命令:chmod +x RackAware.py
重启namenode,如果配置成功,namenode启动日志中会输出:
2018-06-28 14:28:44,495 INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /rack1/192.168.1.15:50010
网络拓扑机器之间的距离
这里基于一个网络拓扑案例,介绍在复杂的网络拓扑中hadoop集群每台机器之间的距离
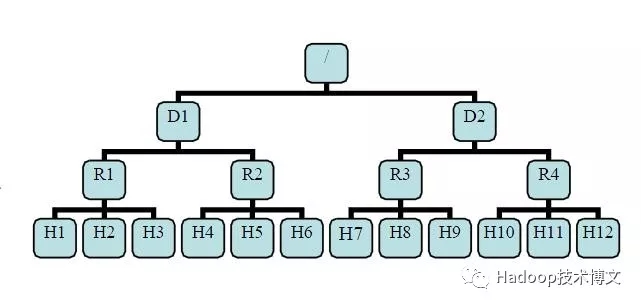
有了机架感知,NameNode就可以画出上图所示的datanode网络拓扑图。D1,R1都是交换机,最底层是datanode。则H1的rackid=/D1/R1/H1,H1的parent是R1,R1的是D1。这些rackid信息可以通过topology.script.file.name配置。有了这些rackid信息就可以计算出任意两台datanode之间的距离。
distance(/D1/R1/H1,/D1/R1/H1)=0 相同的datanode
distance(/D1/R1/H1,/D1/R1/H2)=2 同一rack下的不同datanode
distance(/D1/R1/H1,/D1/R1/H4)=4 同一IDC下的不同datanode
distance(/D1/R1/H1,/D2/R3/H7)=6 不同IDC下的datanode
声明:文章收集于网络,如有侵权,请联系小编及时处理,谢谢!
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/3932.html
摘要:机架内的机器之间的网络速度通常都会高于跨机架机器之间的网络速度,并且机架之间机器的网络通信通常受到上层交换机间网络带宽的限制。第二个副本放置在与第一个节点不同的机架中的中随机选择。配置默认情况下,的机架感知是没有被启用的。 背景分布式的集群通常包含非常多的机器,由于受到机架槽位和交换机网口的限制,通常大型的分布式集群都会跨好几个机架,由多个机架上的机器共同组成一个分布式集群。机架内的机器之间...
摘要:上篇笔记做了一个简单的了解,这次咱们需要了解下谷歌的三篇论文一定搜下看看然后过几遍以后再来进行下边的学习。 上篇笔记做了一个简单的了解,这次咱们需要了解下谷歌的三篇论文Google FS、MapReduce、BigTable(一定搜下看看然后过几遍)以后再来进行下边的学习 。 各章概述,继续熏陶 Hadoop部分Hadoop的起源与背景知识 1.大数据的核心问题: ...
摘要:开源在大量服务器上实现了大数据应用程序的分布式数据处理。到达的数据会被划分成段,并分布于数据节点,以支持并行处理。引擎能够管理分布式数据处理由一个和多个组成。和都宣布了支持计划。 开源Hadoop在大量服务器上实现了大数据应用程序的分布式数据处理。它将给云中的应用程序带来冗余和更高的性能,从而防止出现故障。 Hadoop是Apache软件基金会的一个开源项目,它的出现是基于谷歌、雅虎、...
摘要:历史日志作业的历史文件集中存放在,这个也可以是在分布式文件系统下的路径,其默认值为。启动启动集群需要启动集群和集群。格式化一个新的分布式文件系统在分配的上,运行下面的命令启动脚本会参照上文件的内容,在所有列出的上启动守护进程。 本文描述了如何安装、配置和管理有实际意义的Hadoop集群,其规模可从几个节点的小集群到几千个节点的超大集群。 如果你希望在单机上安装Hadoop玩玩,从这里能找到相...
摘要:下列哪个是运行的模式答案单机版伪分布式分布式提供哪几种安装的方法答案判断题不仅可以进行监控,也可以进行告警。但是在预警以及发生事件后通知用户上并不擅长。错误分析一旦节点宕机,数据恢复是一个难题命令用于检测损坏块。 单项选择题1. 下面哪个程序负责 HDFS 数据存储。a)NameNodeb)Jobtrackerc)Datanoded)secondaryNameNodee)tasktracke...

阅读 1039·2023-04-25 23:22
阅读 1422·2023-04-25 20:04
阅读 2376·2021-11-22 15:24
阅读 2548·2021-11-11 16:54
阅读 2287·2021-09-28 09:35
阅读 1711·2019-08-30 14:03
阅读 1373·2019-08-29 16:35
阅读 1530·2019-08-26 10:29











