
摘要:通过参数来设置,这个参数目前支持两种磁盘选择策略如果想及时了解或者相关的文章,欢迎关注微信公共帐号参数的默认值是。下面对内置的两种磁盘选择策略进行详细的介绍。磁盘选择策略可用空间磁盘选择策略是从开始引入的详情参见。
在 HDFS 中,DataNode 将数据块存储到本地文件系统目录中,具体的目录可以通过配置 hdfs-site.xml 里面的 dfs.datanode.data.dir 参数。在典型的安装配置中,一般都会配置多个目录,并且把这些目录分别配置到不同的设备上,比如分别配置到不同的HDD(HDD的全称是Hard Disk Drive)和SSD(全称Solid State Drives,就是我们熟悉的固态硬盘)上。
当我们往 HDFS 上写入新的数据块,DataNode 将会使用 volume 选择策略来为这个块选择存储的地方。通过参数 dfs.datanode.fsdataset.volume.choosing.policy 来设置,这个参数目前支持两种磁盘选择策略
round-robin
available space

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
dfs.datanode.fsdataset.volume.choosing.policy 参数的默认值是 org.apache.hadoop.hdfs.server.datanode.fsdataset.AvailableSpaceVolumeChoosingPolicy。这两种磁盘选择策略都是对 org.apache.hadoop.hdfs.server.datanode.fsdataset.VolumeChoosingPolicy 接口进行实现,VolumeChoosingPolicy 接口其实就定义了一个函数:chooseVolume 如下:

chooseVolume 函数对指定的副本从 volumes 里面选定满足条件的磁盘。下面对 Hadoop 内置的两种磁盘选择策略进行详细的介绍。
round-robin 磁盘选择策略
从名字就可以看出,这种磁盘选择策略是基于轮询的方式,具体的实现类是 org.apache.hadoop.hdfs.server.datanode.fsdataset.RoundRobinVolumeChoosingPolicy。它的实现很简单:

volumes 参数其实就是通过 dfs.datanode.data.dir 配置的目录。blockSize 就是咱们副本的大小。RoundRobinVolumeChoosingPolicy 策略先轮询的方式拿到下一个 volume ,如果这个 volume 的可用空间比需要存放的副本大小要大,则直接返回这个 volume 用于存放数据;如果当前 volume 的可用空间不足以存放副本,则以轮询的方式选择下一个 volume,直到找到可用的 volume,如果遍历完所有的 volumes 还是没有找到可以存放下副本的 volume,则抛出 DiskOutOfSpaceException 异常。
从上面的策略可以看出,这种轮询的方式虽然能够保证所有磁盘都能够被使用,但是如果 HDFS 上的文件存在大量的删除操作,可能会导致磁盘数据的分布不均匀,比如有的磁盘存储得很满了,而有的磁盘可能还有很多存储空间没有得到利用。
available space 磁盘选择策略
可用空间磁盘选择策略是从 Hadoop 2.1.0 开始引入的(详情参见:HDFS-1804)。这种策略优先将数据写入具有较大可用空间的磁盘(通过百分比计算的)。在实现上可用空间选择策略内部用到了上面介绍的轮询磁盘选择策略,具体的实现代码在 org.apache.hadoop.hdfs.server.datanode.fsdataset.AvailableSpaceVolumeChoosingPolicy 类中,核心实现如下:

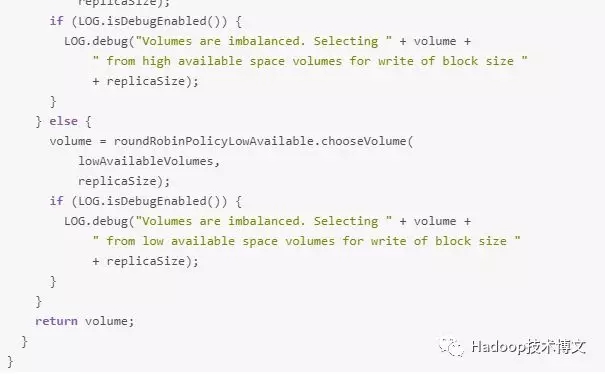
areAllVolumesWithinFreeSpaceThreshold 函数的作用是先计算所有 volumes 的较大可用空间和最小可用空间,然后使用较大可用空间减去最小可用空间得到的结果和 balancedSpaceThreshold(通过 dfs.datanode.available-space-volume-choosing-policy.balanced-space-threshold 参数进行配置,默认值是 10G) 进行比较。
可用空间策略会以下面三种情况进行处理:
1、如果所有的 volumes 磁盘可用空间都差不多,那么这些磁盘得到的较大可用空间和最小可用空间差值就会很小,这时候就会使用轮询磁盘选择策略来存放副本。
2、如果 volumes 磁盘可用空间相差比较大,那么可用空间策略会将 volumes 配置中的磁盘按照一定的规则分为 highAvailableVolumes 和 lowAvailableVolumes。具体分配规则是先获取 volumes 配置的磁盘中最小可用空间,加上 balancedSpaceThreshold(10G),然后将磁盘空间大于这个值的 volumes 放到 highAvailableVolumes 里面;小于等于这个值的 volumes 放到 lowAvailableVolumes 里面。
比如我们拥有5个磁盘组成的 volumes,编号和可用空间分别为 1(1G)、2(50G)、3(25G)、4(5G)、5(30G)。按照上面的规则,这些磁盘的最小可用空间为 1G,然后加上 balancedSpaceThreshold,得到 11G,那么磁盘编号为1、4的磁盘将会放到 lowAvailableVolumes 里面,磁盘编号为2,3和5将会放到 highAvailableVolumes 里面。
到现在 volumes 里面的磁盘已经都分到 highAvailableVolumes 和 lowAvailableVolumes 里面了。
2.1、如果当前副本的大小大于 lowAvailableVolumes 里面所有磁盘较大的可用空间(mostAvailableAmongLowVolumes,在上面例子中,lowAvailableVolumes 里面较大磁盘可用空间为 5G),那么会采用轮询的方式从 highAvailableVolumes 里面获取相关 volumes 来存放副本。
2.2、剩下的情况会以 75%(通过 dfs.datanode.available-space-volume-choosing-policy.balanced-space-preference-fraction 参数进行配置,推荐将这个参数设置成 0.5 到 1.0 之间)的概率在 highAvailableVolumes 里面以轮询的方式 volumes 来存放副本;25% 的概率在 lowAvailableVolumes 里面以轮询的方式 volumes 来存放副本。
然而在一个长时间运行的集群中,由于 HDFS 中的大规模文件删除或者通过往 DataNode 中添加新的磁盘仍然会导致同一个 DataNode 中的不同磁盘存储的数据很不均衡。即使你使用的是基于可用空间的策略,卷(volume)不平衡仍可导致较低效率的磁盘I/O。比如所有新增的数据块都会往新增的磁盘上写,在此期间,其他的磁盘会处于空闲状态,这样新的磁盘将会是整个系统的瓶颈。
欢迎加入本站公开兴趣群软件开发技术群
兴趣范围包括:Java,C/C++,Python,PHP,Ruby,shell等各种语言开发经验交流,各种框架使用,外包项目机会,学习、培训、跳槽等交流
QQ群:26931708
Hadoop源代码研究群
兴趣范围包括:Hadoop源代码解读,改进,优化,分布式系统场景定制,与Hadoop有关的各种开源项目,总之就是玩转Hadoop
QQ群:288410967
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/3936.html
摘要:执行文件系统的操作,例如打开关闭重命名文件和目录,同时决定到具体节点的映射。对于任何对文件元数据产生修改的操作,都使用一个称为的事务日志记录下来。客户端软件实现了文件内容的校验和。 一、前提和设计目标1、硬件错误是常态,而非异常情况,HDFS可能是有成百上千的server组成,任何一个组件都有可能一直失效,因此错误检测和快速、自动的恢复是HDFS的核心架构目标。3、HDFS以支持大数据集合为...
摘要:执行文件系统的操作,例如打开关闭重命名文件和目录,同时决定到具体节点的映射。心跳包的接收表示该节点正常工作,而包括了该上所有的组成的列表。五文件系统元数据的持久化存储的元数据。 一、前提和设计目标 1、硬件错误是常态,而非异常情况,HDFS可能是有成百上千的server组成,任何一个组件都有可能一直失效,因此错误检测和快速、自动的恢复是HDFS的核心架构目标。 2、跑在HDF...
摘要:如何根据数据冷热程度对存储系统进行优化是一个亟待解决的问题。纠删码传统数据采用三副本机制保证数据的可靠性,即每存储数据,实际在集群各节点上占用的数据达到,额外开销为。根据热度和规则,生成具体的任务。 陶捷中国移动苏州研发中心高级软件开发工程师目前负责中国移动大数据平台产品线CMH套件产品的研发,拥有丰富的Hadoop大数据平台研发和建设经验;开源Hadoop社区贡献者。曾任职于阿里巴巴,先后...
摘要:助辅助做元数据的备份。元数据存储在内存和磁盘中,这是因为磁盘的读写效率较低,而保存到内存又有断电消失的隐患。但磁盘中的元数据并不是最新的,内存中的元数据才是实时的。将中的和复制到自身节点上并加载进内存,根据的记录操作更改元数据信息。 HDFS(Hadoop Distributed File System ) 前言:最近正式进入了大数据框架的学习阶段,文章来自个人OneNote笔记全部...

摘要:上节企业级生产调优手册一五存储优化注演示纠删码和异构存储需要一共台虚拟机。引入了纠删码,采用计算的方式,可以节省约左右的存储空间。纠删码案例实操纠删码策略是给具体一个路径设置。集群启动完成后,自动退出安全模式。超过说明有异常。 上节:Hadoop企业级生产调优手册(一)五、HDFS存储优化注:演示纠删码和异构存...

阅读 3466·2023-04-26 00:36
阅读 2437·2021-11-16 11:44
阅读 887·2021-11-15 17:58
阅读 1466·2021-09-30 09:47
阅读 1551·2021-09-26 09:46
阅读 1075·2019-08-30 13:05
阅读 1324·2019-08-30 12:55
阅读 2278·2019-08-30 11:02

















