
问题描述:[hadoop@usdp01 ~]$ hbase shellSLF4J: Class path contains multiple SLF4J bindings.SLF4J: Found binding in [jar:file:/opt/usdp-srv/srv/udp/2.0.0.0/hdfs/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]...
问题描述:日志信息 如下,麻烦大佬帮忙看下[root@hdfs2 udp]# tail -f udp-server-info.2022-10-10.log 2022-10-10 17:05:42 [main] INFO cn.ucloud.udp.UDPServerApplication - The following profiles are active: server2022-10-10 17:05:59 [main] INFO...
...型配置权限可以分为两种类别允许的权限拒绝的权限。 HDFS配置Ranger本篇目录启用 HDFS-Ranger 插件配置权限添加测试用户编辑权限验证权限配置HDFS 作为底层存储,本章节将以 HDFS 为例,进行说明。启用 HDFS-Ranger 插件1. 登陆NameNode...

...e日志采集框架 安装和部署 Flume运行机制 采集静态文件到hdfs 采集动态日志文件到hdfs 两个agent级联 Flume日志采集框架 在一个完整的离线大数据处理系统中,除了hdfs+mapreduce+hive组成分析系统的核心之外,还需要数据采集、结果数...
...数据、jms、avro端口、kafka、系统本地目录下... 目的地=>hdfs、hive、hbase、kafka、系统本地一个文件中... 如何将linux本地的一个日志文件中的日志数据采集到hdfs上 脚本+hdfs命令 =>【周期性】上传 #!/bin/sh HADOOP_HOME=/opt/cdh-5.14....
...到大数据平台上。在典型的Hadoop大数据平台中,人们使用HDFS作为存储服务的核心。而在大数据发展之初,最主要的应用场景仍然是离线批处理场景,对存储的需求追求的是吞吐量,HDFS正是针对这样的场景而设计的,而随着技术...
Hadoop编程调用HDFS Hadoop家族系列文章, 主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, Pig, HBase, Sqoop, Mahout, Zookeeper, Avro, Ambari, Chukwa,新增加的项目包括,YARN, Hcatalog, Oozie, C...
1. hdfs(分布式文件系统) 1.1 分布式文件系统 数据集的大小超过一台独立的计算机的存储能力时,就要通过网络中的多个机器来存储数据集,把管理网络中多台计算机组成的文件系统,称为分布式文件系统 1.2 hdfs的特点 分布...
Hadoop分布式文件系统(hadoopdistributed filesystem,HDFS)。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。HDFS可以实现流的形式访问(streaming access)文件系...
1. HDFS initialized but not healthy yet, waiting... 这个日志会在启动hadoop的时候在JobTracker的log日志文件中出现,在这里就是hdfs出现问题,导致DataNode无法启动,这里唯一的解决方式就是把所有的NameNode管理的路径下的文件删除然后重...
...主流的分布式系统基础架构。这其中,分布式文件系统(HDFS)发挥了重要作用。但Hadoop并不完美。更为讽刺的是,Hadoop较大的缺点之一就是其较大的优势所在——分布式文件系统(HDFS)。在Apache软件基金会,HDFS是为了提高性能...
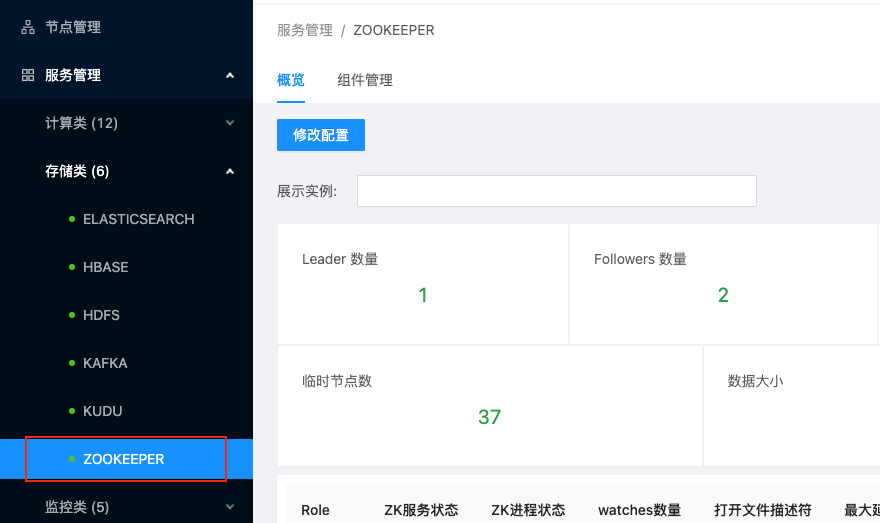
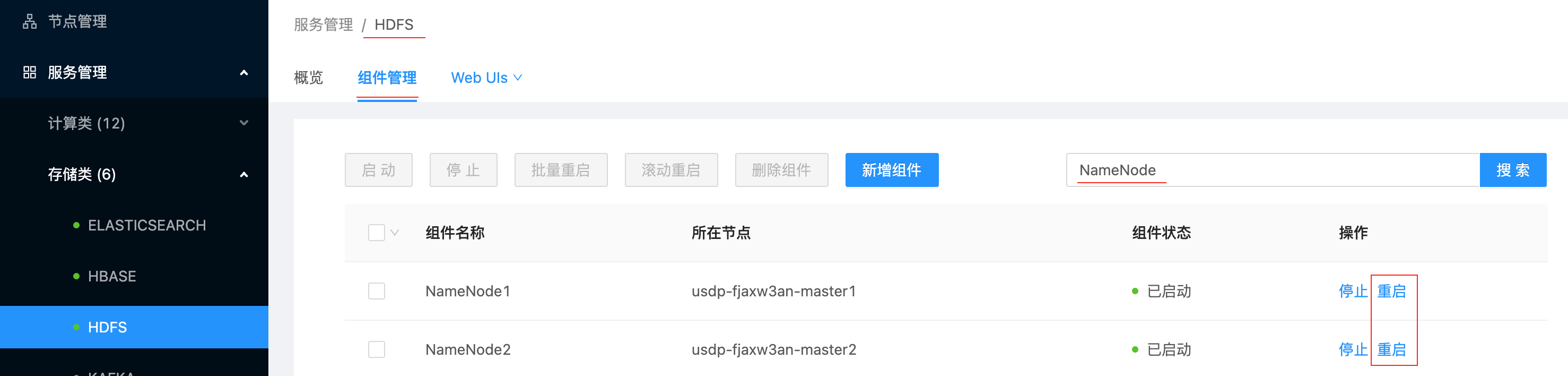
存储类服务管理本篇目录Zookeeper服务管理HDFS服务管理其他存储类服务管理在USDP1.0.0.0版本中,集群存储类服务组件主要有Elasticsearch、HBase、HDFS、Kafka、KUDU、Zookeeper在内的6个服务组件,下面将以Zookeeper及HDFS为代表展示存储类组...
...件 (1) mesos-site.xml mesos.hdfs.namenode.cpus 0.25 mesos.hdfs.datanode.cpus 0.25 ...
...提和设计目标 1、硬件错误是常态,而非异常情况,HDFS可能是有成百上千的server组成,任何一个组件都有可能一直失效,因此错误检测和快速、自动的恢复是HDFS的核心架构目标。 2、跑在HDFS上的应用与一般的应用不同...
...、前提和设计目标1、硬件错误是常态,而非异常情况,HDFS可能是有成百上千的server组成,任何一个组件都有可能一直失效,因此错误检测和快速、自动的恢复是HDFS的核心架构目标。3、HDFS以支持大数据集合为目标,一个存储在...
...户ID 组ID 示例: hadoop fs -ls /user/hadoop/file1 /user/hadoop/file2 hdfs://host:port/user/hadoop/dir1 /nonexistentfile 返回值: 成功返回0,失败返回-1。text使用方法:hadoop fs -text将源文件输出为文本格式。允许的格式是zip和TextRecordInputStr...
上周已经把Hadoop的HDFS的架构和设计大概说了下,也有部署过程。在这周讲的HDFS的数据流及操作例子 HDFS数据流 HDFS系统依赖于以下服务1.NameNode2.DataNode3.JournalNode4.zkfc 其中JournalNode和zkfc是用来做高可用的。 那么数据流将在客...
轻量云主机已更新简化版Windows帕鲁镜像的安装教程,现在仅需3步,就可以畅游帕鲁大陆!需要Lin...
UCloud轻量云主机已更新Linux帕鲁镜像的安装教程,现在仅需1步,就可以畅游帕鲁大陆!也欢迎大...




















