
回答:使用合理的分页方式以提高分页的效率正如楼主所说,分页查询在我们的实际应用中非常普遍,也是最容易出问题的查询场景。比如对于下面简单的语句,一般想到的办法是在name,age,register_time字段上创建复合索引。这样条件排序都能有效的利用到索引,性能迅速提升。如上例子,当 LIMIT 子句变成 LIMIT 100000, 50 时,此时我们会发现,只取50条语句为何会变慢?原因很简单,MyS...
 王晗
|
1488人阅读
王晗
|
1488人阅读

...邮件回复方面。此外,它们还能在好莱坞谋得一职。 在 MIT 的计算机科学和人工智能实验室(CSAIL),一个由 6 位研究人员组成的小组创建了一套机器学习系统,它可以将声音效果与视频剪辑匹配。 别高兴得太早,CSAIL 的算法...
...黑科技:无人驾驶拖拉机一文中提到,一位农民通过学习MIT的计算机网络课程6.00.1x,成功开发出了无人驾驶拖拉机的故事。今天,我与大家分享这套课程的第二部分,也就是6.00.2x,课程名称叫作《计算思维及数据科学导论》,...
...论,价格有点性感,不过不看书也是OK的。Strang是麻省理工MIT的教授,写过很多经典的数学教材。他亲自传授的这个线性代数课程也是享有盛誉。我们还可以在MIT的开放课程里查看更多关于课程的信息:MIT线性代数课程官网。这个...
增量方法,每次处理一小撮数据,增量更新参数,每一步更新的计算量都很小。统计梯度下降法。 有一个基本假设:数据有时序的到来,满足一定的分布(强假设:前面的数据和后面的数据是独立同分布)。所以对于前面的数...
内点法,在大数据里不适用。小数据下收敛速度较快。 了解内点法原理可以参看https://blogs.princeton.edu/imabandit/2013/02/14/orf523-interior-point-methods/
...,再用一些特殊的技巧解决正则项的二次优化问题 priximity 最后:谁能告诉我blog中怎么输入公式?
这一章干货比较多,看起来比较累,收获也比较大。 坚持看,坚持写。 写公式真累,希望segmentfault能尽快支持输入latex公式 一直拿不下最优化这块东西,理论和实践都有欠缺,争取这回能拿下。 $2.1 Introduction $2.1.1 loss函数...
内点法,在大数据里不适用。小数据下收敛速度较快。 了解内点法原理可以参看https://blogs.princeton.edu/imabandit/2013/02/14/orf523-interior-point-methods/
增量方法,每次处理一小撮数据,增量更新参数,每一步更新的计算量都很小。统计梯度下降法。 有一个基本假设:数据有时序的到来,满足一定的分布(强假设:前面的数据和后面的数据是独立同分布)。所以对于前面的数...
$2.2 一般方法 次梯度方法 转化成普通的LP,SDP问题 这类general方法对1范数问题本身的结构没有挖掘,所以收敛速度较慢。 LP、SDP等方法过于追求优化精度,在机器学习领域其实不重要。重要的求一个合理的解,满足实际问...
终于可以直接输入公式了,希望sf越来越好。目前对公式的渲染速度有点慢,而且公式渲染也有问题 (Block) Coordinate Descent Alorithm 所谓的(B)CD,是指每一步迭代的时候,不是对所有的参数进行优化,而是每次只选一个参数进行...
...现年月 2014-2 2013-3 2010-10 框架类型 MVVM MVC MVW 开源许可 MIT license BSD3-license MIT license MIT许可协议(The MIT License)是许多软件许可条款中,被广泛使用的其中一种。与其他常见的软件许可协议(如GPL、LGPL、BSD)相比,MIT是相...
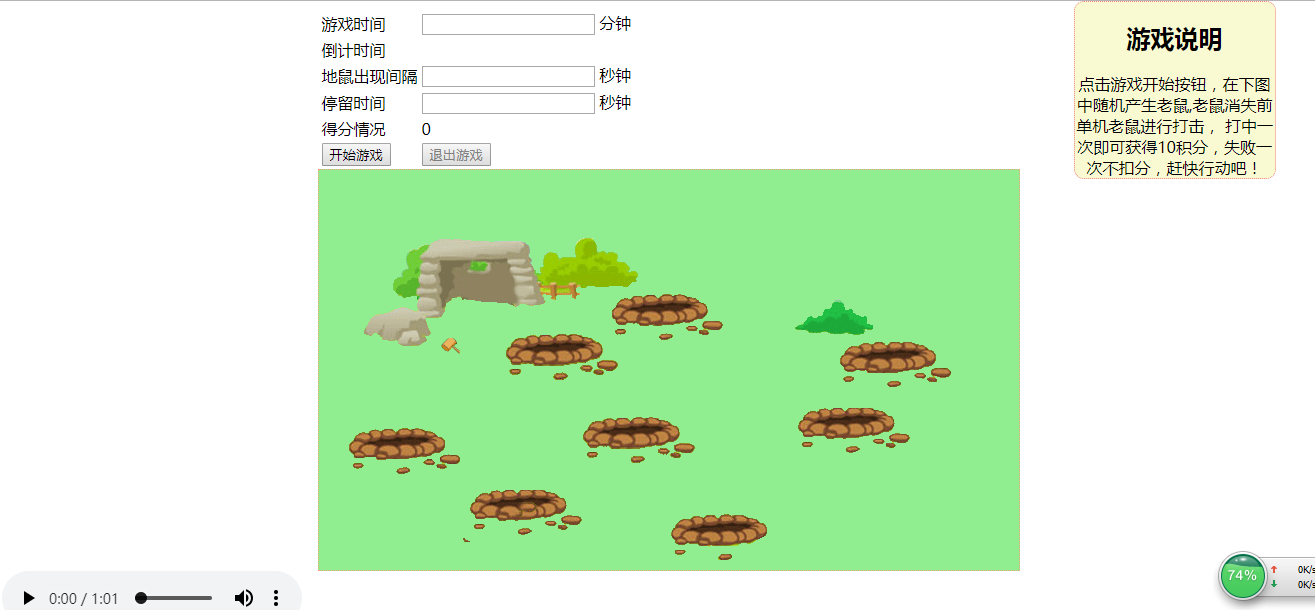
...timesdaojishi!=0){ //倒计时 var mit=$$(inp0).value; mit*=60; daoji= setInterval(function(){ ...
轻量云主机已更新简化版Windows帕鲁镜像的安装教程,现在仅需3步,就可以畅游帕鲁大陆!需要Lin...
UCloud轻量云主机已更新Linux帕鲁镜像的安装教程,现在仅需1步,就可以畅游帕鲁大陆!也欢迎大...




 荆兆峰
荆兆峰 ernest
ernest



















