

回答:这个太范化了吧。大数据架构选择的方案就有很多,海量数据的即席查询本省就是业内目前的痛点,暂时没有太好的解决方案,kylin等框架也只是一个折中方案,如果你不是要求海量数据分析的秒级响应的话sparkSql、presto等都是不错的方案,分钟级别可以返回。
 Paul_King
|
418人阅读
Paul_King
|
418人阅读
回答:安装 HBase(Hadoop Database)是在 Linux 操作系统上进行大规模数据存储和处理的一种分布式数据库解决方案。以下是在 Linux 上安装 HBase 的一般步骤: 步骤 1:安装 Java 在 Linux 上安装 HBase 需要 Java 运行时环境(JRE)或 Java 开发工具包(JDK)。您可以通过以下命令安装 OpenJDK: 对于 Ubuntu/Debian...
 hyuan
|
768人阅读
hyuan
|
768人阅读
回答:我们已经上线了好几个.net core的项目,基本上都是docker+.net core 2/3。说实话,.net core的GC非常的优秀,基本上不需要像做Java时候,还要做很多的优化。因此没有多少人研究很正常。换句话,如果一个GC还要做很多优化,这肯定不是好的一个GC。当然平时编程的时候,常用的非托管的对象处理等等还是要必须掌握的。
 ZweiZhao
|
682人阅读
ZweiZhao
|
682人阅读
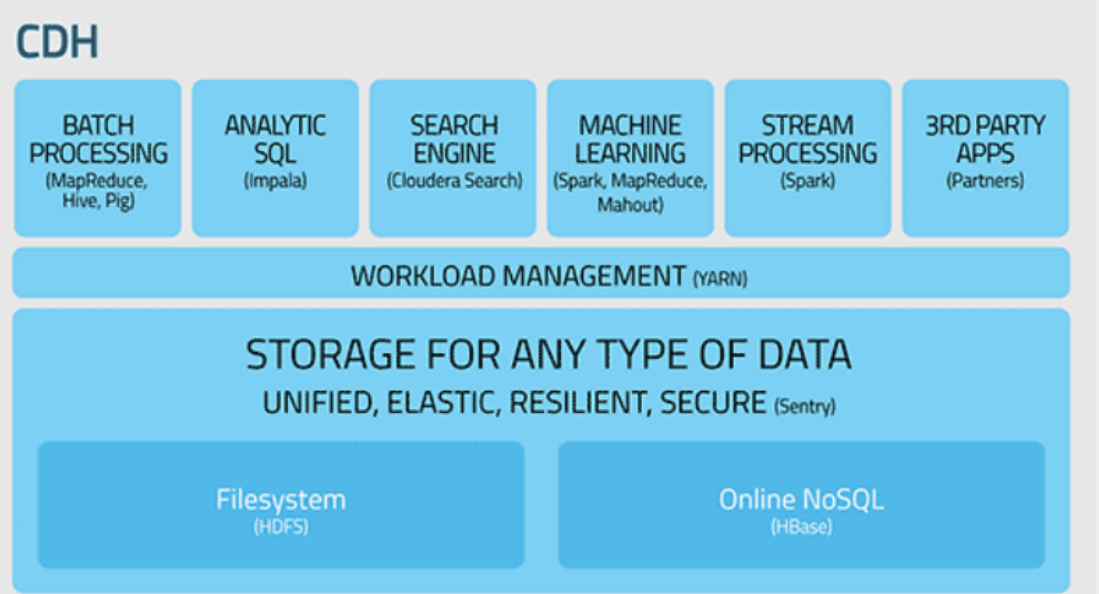
回答:一、区别:1、Hbase: 基于Hadoop数据库,是一种NoSQL数据库;HBase表是物理表,适合存放非结构化的数据。2、hive:本身不存储数据,通过SQL来计算和处理HDFS上的结构化数据,依赖HDFS和MapReduce;hive中的表是纯逻辑表。Hbase主要解决实时数据查询问题,Hive主要解决数据处理和计算问题,二者通常协作配合使用。二、适用场景:1、Hbase:海量明细数据的随机...
 wizChen
|
1961人阅读
wizChen
|
1961人阅读
问题描述:[hadoop@usdp01 ~]$ hbase shellSLF4J: Class path contains multiple SLF4J bindings.SLF4J: Found binding in [jar:file:/opt/usdp-srv/srv/udp/2.0.0.0/hdfs/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]...
回答:1. 如果你对数据的读写要求极高,并且你的数据规模不大,也不需要长期存储,选redis;2. 如果你的数据规模较大,对数据的读性能要求很高,数据表的结构需要经常变,有时还需要做一些聚合查询,选MongoDB;3. 如果你需要构造一个搜索引擎或者你想搞一个看着高大上的数据可视化平台,并且你的数据有一定的分析价值或者你的老板是土豪,选ElasticSearch;4. 如果你需要存储海量数据,连你自己都...
 xiao7cn
|
706人阅读
xiao7cn
|
706人阅读

...避免频繁的内存和磁盘数据交换,从而降低磁盘IO,提高性能。大概估算公式:map = 2 + 2/3cpu_corereduce = 2 + 1/3cpu_core5. HBase优化在HDFS的文件中追加内容HDFS 不是不允许追加内容么?没错,请看背景故事:属性:dfs.support.append文件:hd...
...大数据集群规划,集群部署实施,集群调优(重点,没有性能瓶颈的调优都是耍流氓),集群监控管理,集群日常运维,大数据组件原理剖析,源码演示,二次组件开发等。小伙伴基于日常工作内容演示教学,学到的就是实战,...
...也感谢阿里云技术同学,帮我们解决了底层系统的运维和性能调优,保证了底层系统的稳定,使我们可以更加专注的服务业务,帮助业务发展的更快。原文链接
...的框架,但是后来没好意思开源出来,虽然能跑,但是在性能上完全无法接受。我就想这个东西为什么这么慢?一步一步去看每一层,就想动手改,但是发现工程量巨大,比如 MySQL 的 SQL 优化器, 事务模型等等,完全没有办法...
...求过程 2、有比较过 Http 和 RPC 吗?如果叫你设计一个高性能的 Http 或者 RPC,你会从哪些方面考虑? 3、项目中我看使用了 xxx (ElasticSearch、Hbase、Redis、Flink 等),有深入了解它们的原理和懂点调优技巧吗? 4、项目中我看使用...
...平台可以释放红利给客户存储与计算分离:按需计费优化性能:再把性能提升1倍左右云数据库基本部署结构 假设在北京有三个机房可用区A、B和C,我们会在可用区A中部署一个热的存储集群,在北京整体区域部一个冷的存储集群...
...平台可以释放红利给客户存储与计算分离:按需计费优化性能:再把性能提升1倍左右云数据库基本部署结构 假设在北京有三个机房可用区A、B和C,我们会在可用区A中部署一个热的存储集群,在北京整体区域部一个冷的存储集群...
...平台可以释放红利给客户存储与计算分离:按需计费优化性能:再把性能提升1倍左右云数据库基本部署结构 假设在北京有三个机房可用区A、B和C,我们会在可用区A中部署一个热的存储集群,在北京整体区域部一个冷的存储集群...
...品研发的过程中,技术小哥哥们能文能武,不断提升产品性能和体验的同时,也把这些提升和优化过程记录下来,现录入袋鼠云研发手记专栏中,以和业内童鞋们分享交流。 下为袋鼠云研发手记专栏第三期,本期作者...
...缓存,并在内存buffer中 进行一些预排序来优化整个map的性能。而上图右边的reduce阶段则经历了三个阶段,分别Copy->Sort->reduce。我们能 明显的看出,其中的Sort是采用的归并排序,即merge sort。 了解了什么是mapreduce,接下来,...
...间件实践》 《分布式服务架构.原理、设计与实战》 《高性能服务系统构建与实战》 并发编程类 《图解Java多线程设计模式》 《Java并发编程实战》 《实战Java高并发程序设计》 《Java并发编程之美》 Netty类 《Netty权威指南 第2版...
...来HBase不会再添加大的新功能,而将会更多的在稳定性和性能方面进化,尤其是大内存支持、内存GC效率等。Kudu是Cloudera在2015年10月才对外公布的新的分布式存储架构,与HDFS完全独立。其实现参考了2012年Google发表的Spanner论文。...
...原始模型的输出到线上比起结果数据输出更轻便,对线上性能影响更小,更方便于算法在线调优。 当然也还是存在一些问题: 模型离线训练,用户实时产生的行为无法反馈到模型当中,可能造成推荐结果数据的延迟; 业务混...
...原始模型的输出到线上比起结果数据输出更轻便,对线上性能影响更小,更方便于算法在线调优。 当然也还是存在一些问题: 模型离线训练,用户实时产生的行为无法反馈到模型当中,可能造成推荐结果数据的延迟; 业务混...
轻量云主机已更新简化版Windows帕鲁镜像的安装教程,现在仅需3步,就可以畅游帕鲁大陆!需要Lin...
UCloud轻量云主机已更新Linux帕鲁镜像的安装教程,现在仅需1步,就可以畅游帕鲁大陆!也欢迎大...
























