

回答:Hadoop生态Apache™Hadoop®项目开发了用于可靠,可扩展的分布式计算的开源软件。Apache Hadoop软件库是一个框架,该框架允许使用简单的编程模型跨计算机集群对大型数据集进行分布式处理。 它旨在从单个服务器扩展到数千台机器,每台机器都提供本地计算和存储。 库本身不是设计用来依靠硬件来提供高可用性,而是设计为在应用程序层检测和处理故障,因此可以在计算机集群的顶部提供高可用性服务,...
 娣辩孩
|
1210人阅读
娣辩孩
|
1210人阅读
回答:1998年9月4日,Google公司在美国硅谷成立。正如大家所知,它是一家做搜索引擎起家的公司。无独有偶,一位名叫Doug Cutting的美国工程师,也迷上了搜索引擎。他做了一个用于文本搜索的函数库(姑且理解为软件的功能组件),命名为Lucene。左为Doug Cutting,右为Lucene的LOGOLucene是用JAVA写成的,目标是为各种中小型应用软件加入全文检索功能。因为好用而且开源(...
 ctriptech
|
626人阅读
ctriptech
|
626人阅读
回答:可以自行在某些节点上尝试安装 Spark 2.x,手动修改相应 Spark 配置文件,进行使用测试,不安装 USDP 自带的 Spark 3.0.1
回答:Spark Shark |即Hive onSparka.在实现上是把HQL翻译成Spark上的RDD操作,然后通过Hive的metadata获取数据库里的表信息,Shark获取HDFS上的数据和文件夹放到Spark上运算.b.它的最大特性就是快以及与Hive完全兼容c.Shark使用了Hive的API来实现queryparsing和logic plan generation,最后的Physical...
 liaoyg8023
|
774人阅读
liaoyg8023
|
774人阅读

...算框架。Spark基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将Spark部署在大量廉价硬件之上,形成集群。 Spark与Hadoop Spark是一个计算框架,而Hadoop中包含计算框架MapReduce和...
...不同。因此,在选择合适的ETL工具时,除了需要考虑数据处理的正确性、完整性、工具易用性、对不同数据格式的支持程度之外,还必须考虑数据处理的效率、处理能力的可扩展、容错性。Spark是UC Berkeley AMP lab开源的类Hadoop MapRe...
...不同。因此,在选择合适的ETL工具时,除了需要考虑数据处理的正确性、完整性、工具易用性、对不同数据格式的支持程度之外,还必须考虑数据处理的效率、处理能力的可扩展、容错性。Spark是UC Berkeley AMP lab开源的类Hadoop MapRe...
...用 Spark 在 TiDB 上做 OLAP 分析 TiDB 是一款定位于在线事务处理/在线分析处理的融合型数据库产品,实现了一键水平伸缩,强一致性的多副本数据安全,分布式事务,实时 OLAP 等重要特性。TiSpark 是 PingCAP 为解决用户复杂 OLAP 需求...
...用 Spark 在 TiDB 上做 OLAP 分析 TiDB 是一款定位于在线事务处理/在线分析处理的融合型数据库产品,实现了一键水平伸缩,强一致性的多副本数据安全,分布式事务,实时 OLAP 等重要特性。TiSpark 是 PingCAP 为解决用户复杂 OLAP 需求...
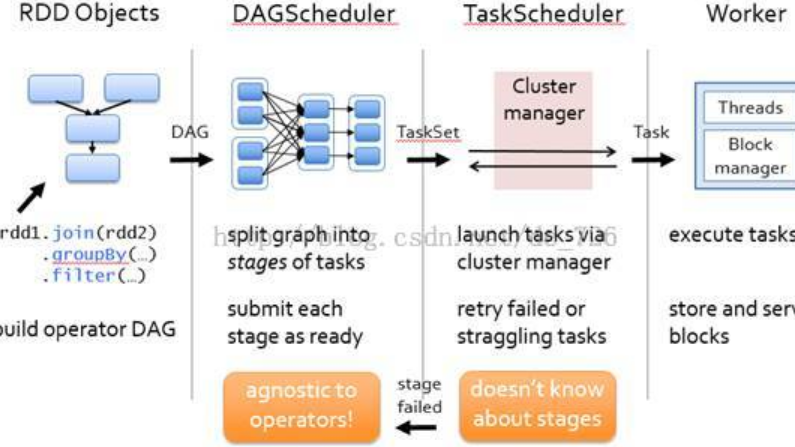
...工具和技术,例如 Apache Spark,它是一种用于大规模数据处理的快速灵活的数据处理引擎。 CDH Spark2 是 Apache Spark 的一个版本,包含在 Cloudera Distribution for Apache Hadoop (CDH) 中。它是一个强大而灵活的数据处理引...
...方提供的 streaming api [twitter 等] 来作为数据源加载数据 处理数据,这是重点中的重点,不过不外乎都是从三个方面来完成这里的数据清理,逻辑运算等: 自定义的一些复杂处理函数或者第三方包 [下面我们称为函数集] 通过 RDD ...
...方提供的 streaming api [twitter 等] 来作为数据源加载数据 处理数据,这是重点中的重点,不过不外乎都是从三个方面来完成这里的数据清理,逻辑运算等: 自定义的一些复杂处理函数或者第三方包 [下面我们称为函数集] 通过 RDD ...
...Spark、Mesos、Akka、Cassandra以及Kafka)堆栈构建可扩展数据处理平台。虽然这套堆栈仅由数个简单部分组成,但其能够实现大量不同系统设计。除了纯粹的批量或者流处理机制之外,我们亦可借此实现复杂的Lambda以及Kappa架构。 基...
...cheme, Java, Perl, C, C++, Ruby等语言。Holden著有《Spark快速数据处理》,与人合著有《Spark快速大数据分析》。 问:你是《Spark快速数据处理》和《Spark快速大数据分析》的作者,这两本书有什么区别?你的写作过程是什么样的? 《Spa...
...十分之一的机器。Spark集群目前最大的可以达到8000节点,处理的数据达到PB级别,在互联网企业中应用非常广泛。 二、Spark理论导读 2.1 大数据技术生态介绍 写的很好的一篇大数据技术生态圈介绍文章,层次条理分明,内容详尽...
...临时文件通常保存7天,以便加快针对同一数据集的任何处理。磁盘空间相对便宜,由于Spark不使用磁盘输入/输入用于处理,已使用的磁盘空间可以用于SAN或NAS。 容错上:Spark使用弹性分布式数据集(RDD),它们是容错集合,里...
...临时文件通常保存7天,以便加快针对同一数据集的任何处理。磁盘空间相对便宜,由于Spark不使用磁盘输入/输入用于处理,已使用的磁盘空间可以用于SAN或NAS。 容错上:Spark使用弹性分布式数据集(RDD),它们是容错集合,里...
...临时文件通常保存7天,以便加快针对同一数据集的任何处理。磁盘空间相对便宜,由于Spark不使用磁盘输入/输入用于处理,已使用的磁盘空间可以用于SAN或NAS。 容错上:Spark使用弹性分布式数据集(RDD),它们是容错集合,里...
...临时文件通常保存7天,以便加快针对同一数据集的任何处理。磁盘空间相对便宜,由于Spark不使用磁盘输入/输入用于处理,已使用的磁盘空间可以用于SAN或NAS。 容错上:Spark使用弹性分布式数据集(RDD),它们是容错集合,里...
轻量云主机已更新简化版Windows帕鲁镜像的安装教程,现在仅需3步,就可以畅游帕鲁大陆!需要Lin...
UCloud轻量云主机已更新Linux帕鲁镜像的安装教程,现在仅需1步,就可以畅游帕鲁大陆!也欢迎大...




 Object
Object



















