摘要:伪分布模式在单节点上同时启动等个进程,模拟分布式运行的各个节点。完全分布式模式正常的集群,由多个各司其职的节点构成。在之前在集群中存在单点故障。正确的下载链接会有,这个就是公司需要用户在下载时提供的注册信息。
每一次 Hadoop 生态的更新都是如此令人激动
像是 hadoop3x 精简了内核,spark3 在调用 R 语言的 UDF 方面,速度提升了 40 倍
所以该文章肯定得配备上最新的生态

OS :
组件:
可选项
- Hive
- Flume 1.9
- Sqoop 2
- kafka 2x
- Spark 3x
RDMS:
开发语言:
集群规划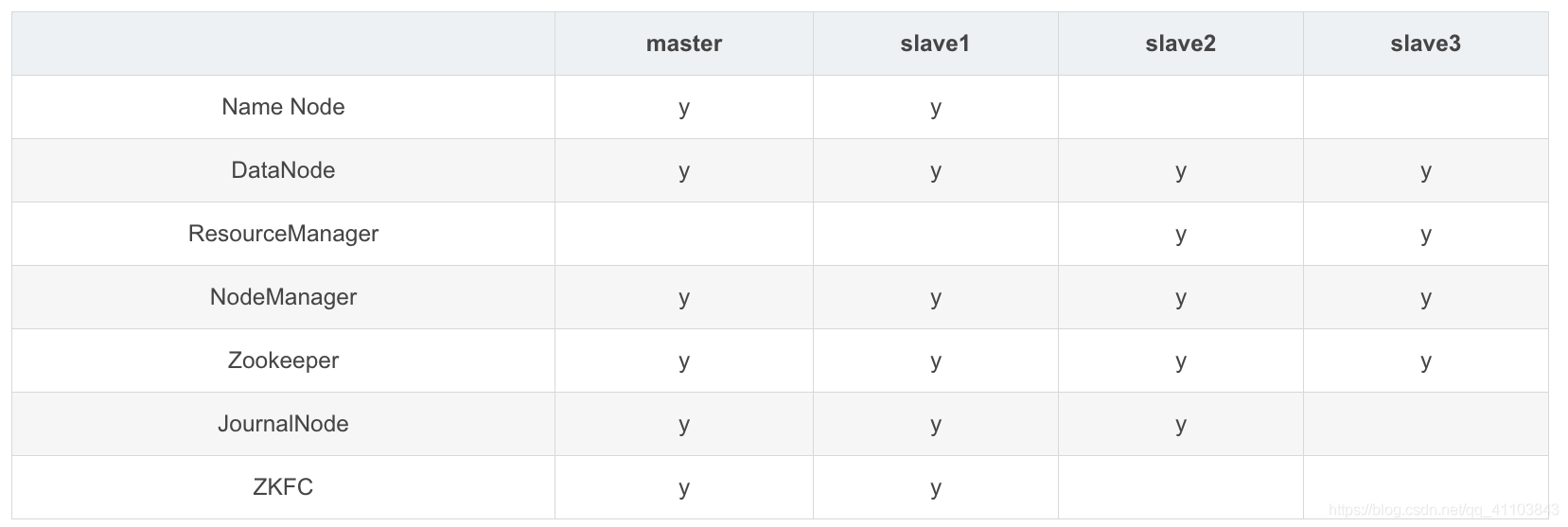
建议:Zookeeper、JournalNode 节点为奇数
- 防止由脑裂造成的集群不可用
- leader 选举,要求 可用节点数量 > 总节点数量/2 ,节省资源
Hadoop 安装有如下三种方式:
此文采用 HA方案 进行部署
可选方案:
此文采用 多台物理机 方案
共 4 台物理设备
此文采用版本:Centos7.4 x64
建议:百度网盘 centos7.4 密码: 8jwf
镜像刻录不进行介绍
请参考:
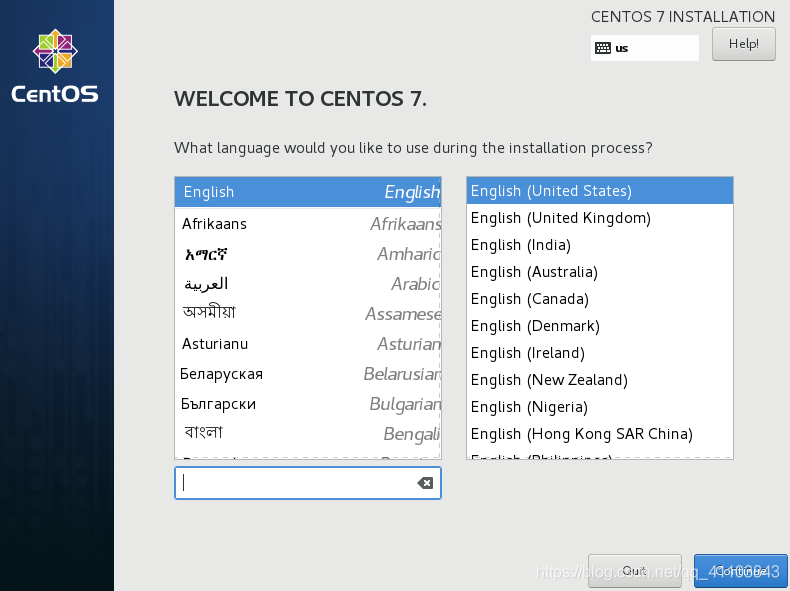
选择语言:
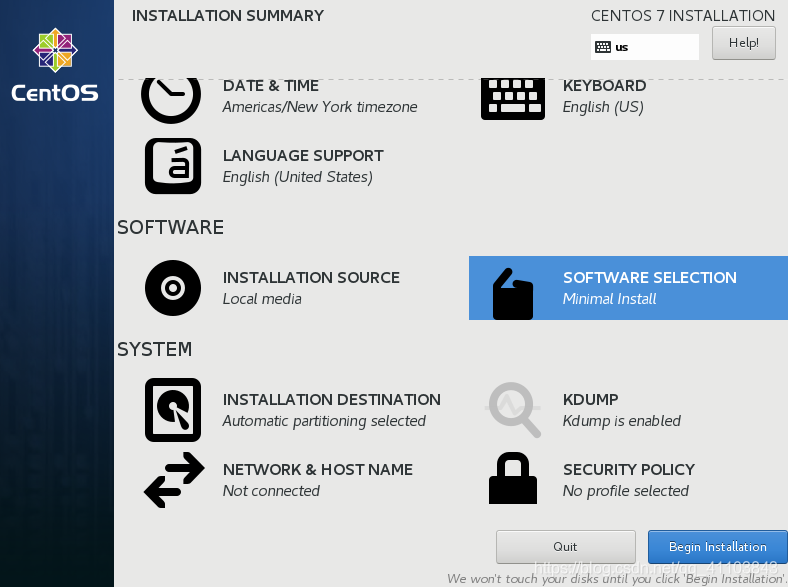
采用最小安装方案
> >
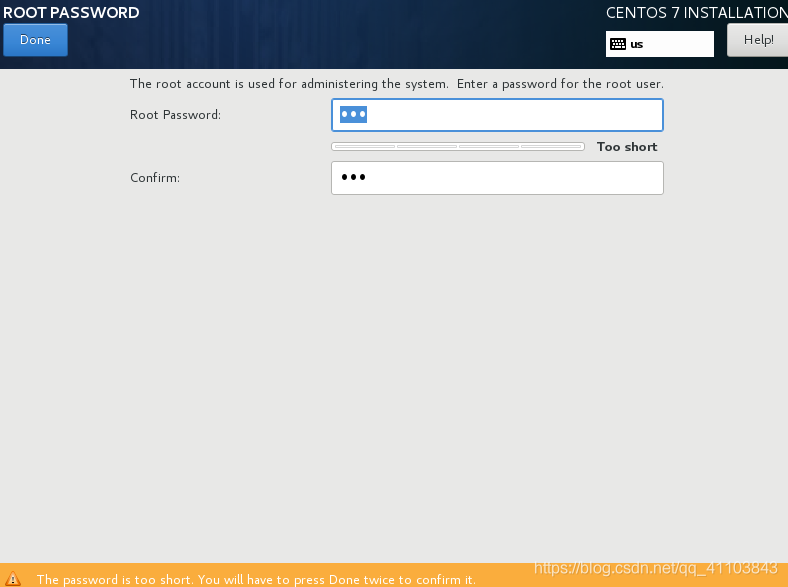
设置 root 密码
点击 ROOT PASSWORD 设置 root 密码,不用添加用户
> >
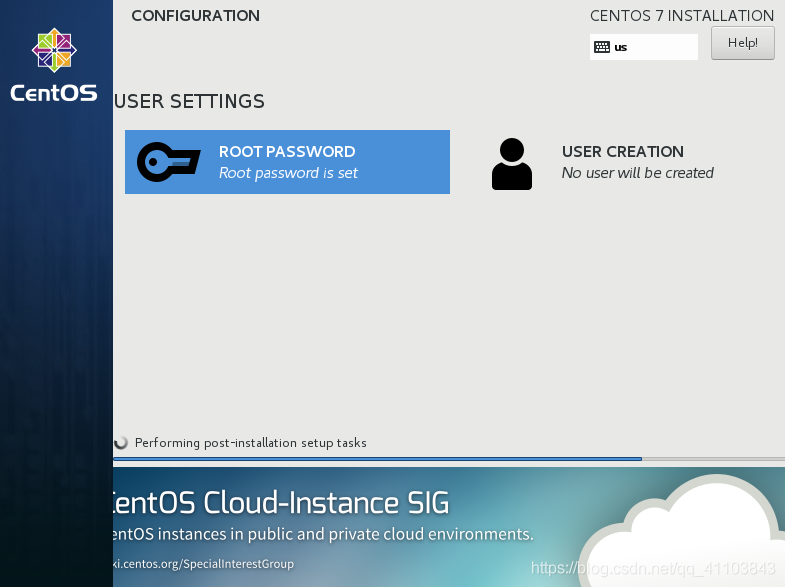
等待完成
完成之后点击Reboot > >
该节点为虚拟机的朋友提供帮助
1)共享网络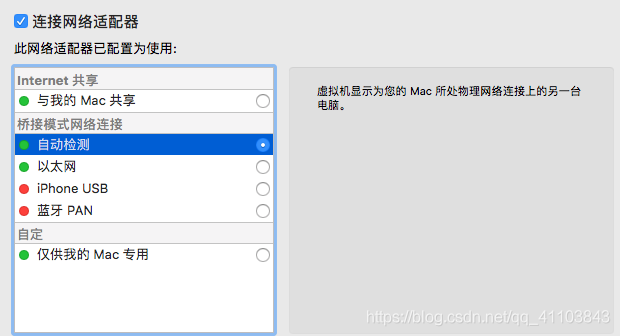
2)选择桥接模式
1)查找配置文件
find / -name ifcfg-*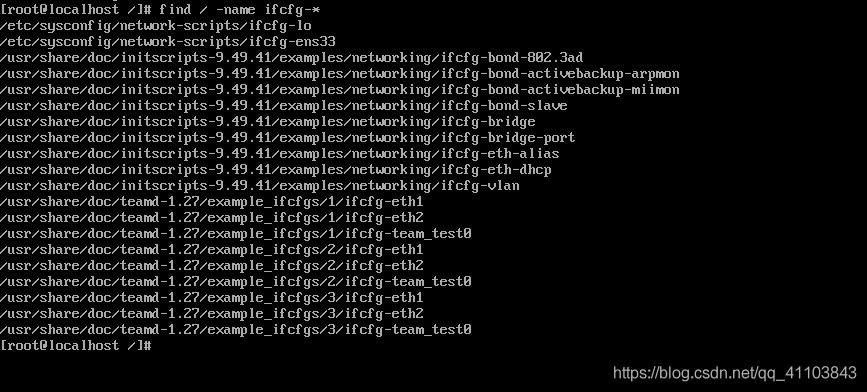
2)修改你 etc 目录下,并以你网卡名结尾的文件
# 这里举例我的vi /etc/sysconfig/network-scripts/ifcfg-ens33动态 IP 修改操作:
- 启用 dhcp
- 注释 ipaddr 和 gateway
- onboot 设置为 yes
建议做如下修改
修改为静态 IP
# 修改BOOTPROTO="static" #dhcp改为staticONBOOT="yes" #开机启用本配置# 添加IPADDR=192.168.x.x #静态IPGATEWAY=192.168.x.x #默认网关NETMASK=255.255.255.0 #子网掩码DNS1=你本机的dns配置 #DNS 配置3)重启服务
service network restart4)ping 一下我的博客试试
ping uiuing.com
安装 net-tools
yum -y install net-tools查看 ip
ifconfig打开客户端终端进行 ssh 连接
ssh root@yourip此文采用版本:mysql5.7
登陆 centos
yum -y install gcc gcc-c++ ncurses ncurses-devel cmakeMysql5.7 版本更新后有很多变化,安装必须要 BOOST 库(版本需为 1.59.0)
boost 库下载地址:boost
1)下载
wget https://jaist.dl.sourceforge.net/project/boost/boost/1.59.0/boost_1_59_0.tar.gz2)检查 MD5 值,若不匹配则需要重新下载
md5sum boost_1_59_0.tar.gz3)解压
tar -vxzf boost_1_59_0.tar.gz4)存储
mv boost_1_59_0 /usr/local/boost_1_59_0安装 wget
yum -y install wget官方下载地址:mysql
1)下载
wget https://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-5.7.21.tar.gz2)检查 MD5 值,若不匹配则需要重新下载
md5sum mysql-5.7.21.tar.gz1)解压
tar -vxzf mysql-5.7.21.tar.gz2)编译
cmake ./make3)安装
make install启动
systemctl start mysqld或者
systemctl start | stop查看 mysql 状态
systemctl status mysqld或者
systemctl status开机自启(可选)
systemctl enable mysqld重载配置(可选)
systemctl daemon-reload配置 root 密码
1)生成默认密码
grep temporary password /var/log/mysqld.log
localhost 后面的就是你的 root 密码
2)修改密码
登陆 mysql
mysql -uroot -p你的密码
修改密码
ALTER USER root@localhost IDENTIFIED BY 你的密码;注意:mysql 5.7 默认安装了密码安全检查插件(validate_password),默认密码检查策略要求密码必须包含:大小写字母、数字和特殊符号,并且长度不能少于8位
以后可以用 update 更新密码
use mysql;update user set password=PASSWORD(你的密码) where user=root;flush privileges;添加远程用户(可选)
GRANT ALL PRIVILEGES ON *.* TO 用户名@% IDENTIFIED BY 密码 WITH GRANT OPTION;use mysql;UPDATE user SET Host=% WHERE User=用户名;flush privileges;配置文件:/etc/my.cnf
日志文件:/var/log/mysqld.log
服务启动脚本:/usr/lib/systemd/system/mysqld.service
socket 文件:/var/run/mysqld/mysqld.pid
此文采用版本:JDK8
安装文本编辑器 vim
yum -y install vimJDK 官方下载地址:oracle jdk
使用命令下载:
wget https://download.oracle.com/otn/java/jdk/8u291-b10/d7fc238d0cbf4b0dac67be84580cfb4b/jdk-8u291-linux-x64.tar.gz?AuthParam=1619936099_3a37c8b389365d286242f4b1aa4967b0因为 oracle 公司不允许直接通过 wget 下载官网上的 jdk 包
正确做法:
通过搜索引擎搜索 jdk 官网下载, 进入 oracle 官网
勾选 accept licence agreement ,并选择你系统对应的版本
点击对应的版本下载,弹出如下下载框,然后复制下载链接
这个复制的链接结算我们 wget 命令的地址。
正确的下载链接会有”AuthParam“,这个就是 oracle 公司需要用户在下载时提供的注册信息。而且这个信息是用时间限制的,过了一段时间后就会失效,如果你想再次下载 jdk 包,只能再次重复上面的操作。
检查大小
ls -lht
查看文件名(用于解压)
ls创建文件夹
mkdir /usr/local/java解压
tar -zxvf 你的jdk包名 -C /usr/local/java/查看文件名(用于配置环境变量)
ls /usr/local/java
打开配置文件
vi /etc/profile在末尾添加
# jdk8 # 添加jdk地址变量 JAVA_HOME=/usr/local/java # 添加jre地址变量 JRE_HOME=${JAVA_HOME}/jre # 添加java官方库地址变量 CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib # 添加PATH地址变量 PATH=${JAVA_HOME}/bin:$PATH # 使变量生效 export JAVA_HOME JRE_HOME CLASSPATH PATH刷新配置文件
source /etc/profile添加软链接(可选)
ln -s /usr/local/java/jdk1.8.0_291/bin/java /usr/bin/java检查
java -version
此文采用版本:Python3.6
我们已经掌握了二进制包安装的方法,所以我们直接通过 yum 来安装 Python
yum -y install python36依赖:python36-libs
安装 pip3(默认已安装)
yum install python36-pip -y检查
python3 --version
此文采用版本:Scala2.11.7
请确保已安装JDK8或者JDK11
Scala 官方下载地址:Scala
使用命令下载:
wget https://downloads.lightbend.com/scala/2.11.7/scala-2.11.7.tgz检查大小
ls -lht查看文件名(用于解压)
ls创建文件夹
mkdir /usr/local/scala解压
tar -zxvf 你的jdk包名 -C /usr/local/scala/查看文件名(用于配置环境变量)
ls /usr/local/scala
打开配置文件
vi /etc/profile在末尾添加
# scala 2.11.7 # 添加scala执行文件地址变量 SCALA_HOME=/usr/local/scala/scala-2.11.7 # 添加PATH地址变量 PATH=$PATH:$SCALA_HOME/bin # 使变量生效 export SCALA_HOME PATH刷新配置文件
source /etc/profile检查
scala -version
使用虚拟机的朋友请直接克隆
切记要返回第四步骤更改各节点ip,不然会发生ip冲突
1)备份
前往根目录
cd /备份
tar cvpzf backup.tgz / --exclude=/proc --exclude=/lost+found --exclude=/mnt --exclude=/sys --exclude=backup.tgz备份完成后,在文件系统的根目录将生成一个名为“backup.tgz”的文件,它的尺寸有可能非常大。你可以把它烧录到 DVD 上或者放到你认为安全的地方去
在备份命令结束时你可能会看到这样一个提示:’tar: Error exit delayed from previous
errors’,多数情况下你可以忽略
2)准备
别忘了到其他设备下重新创建那些在备份时被排除在外的目录(如果不存在):
mkdir procmkdir lost+foundmkdir mntmkdir sys3)复刻
可选前提:
到其他物理机上恢复文件
tar xvpfz backup.tgz -C /恢复 SELinux 文件属性
restorecon -Rv /1)修改 hostname
到各设备下执行
# 设备 1 (立即生效)hostnamectl set-hostname master# 设备 2 (立即生效)hostnamectl set-hostname slave1# 设备 3 (立即生效)hostnamectl set-hostname slave2# 设备 4 (立即生效)hostnamectl set-hostname slave32)配置 host 文件
查看各设备 ip(到各设备下执行)
ifconfig到 master 下打开 host 文件
vim /etc/hosts末尾追加
master设备的ip masterslave1设备的ip masterslave2设备的ip masterslave3设备的ip master3)通过 scp 传输 host 文件
scp 语法:scp 文件名 远程主机用户名@远程主机名或ip:存放路径
到 master 下执行
scp /etc/hosts root@SlaveIP:/etc/注意:请按照 slave 个数,对其 ip 枚举传输
ping 一下
ping -c 4 slave1能 ping 通就没问题
以下操作均在master下执行
1)到各设备下生成密钥
ssh-keygen -t rsa一路回车
到 master 生成公钥
cd ~/.ssh/ && cat id_rsa.pub > authorized_keys之后将各设备的密钥全复制到authorized_keys文件里
2)通过 scp 传输公钥
到 master 下执行
scp authorized_keys root@SlaveNumbe:~/.ssh/注意:请按照之前设置的 hostname ,对其 ip 枚举传输
例如: scp authorized_keys root@slave1:~/.ssh/
注意,如果各节点下没有 ~/.ssh/ 目录则会配置失败
检查
ssh slave1
中断该 ssh 连接(可选)
exit该配置主要方便客户端远程操作
无论是用虚拟机进行学习的朋友,还是工作的朋友都强烈推荐
以下操作均在客户端(MAC OS)上执行
修改 hots 文件
sudo vim /etc/hosts将 master 设备下/etc/hosts 之前追加的内容,copy 追加到客户端 hosts 末尾
ping 一下,能 ping 通就没问题
免密钥 ssh 登陆
客户端生产密钥:
sudo ssh-keygen -t rsa打开密钥
vim ~/.ssh/id_rsa到 master 内向各节点申请同步
scp authorized_keys root@SlaveNumbe:~/.ssh/windows ssh 目录:C:/Users/your_userName.ssh
检查
ssh master
此文采用版本 ZooKeepr3.6.3
官方下载地址:Zookeeper记得下载带bin字样的
从客户端上下载 压缩包
到 master 节点上创建 zookeeper 文件夹
mkdir /usr/local/zookeeper从客户端上传到 master
scp 你下载的Zookeeper路径 root@master:/usr/local/zookeeper以下操作切换至master节点上
解压
cd /usr/local/zookeeper tar xf apache-zookeeper-3.6.3-bin.tar.gz打开配置文件
vim /etc/profile在末尾添加
# ZooKeeper3.6.3 # 添加zookeeper地址变量 ZOOKEEPER_HOME=/usr/local/zookeeper/apache-zookeeper-bin.3.6.3 # 添加PATH地址变量 PATH=$ZOOKEEPER_HOME/bin:$PATH # 使变量生效 export ZOOKEEPER_HOME PATH刷新配置文件
source /etc/profile创建数据目录
mkdir /zookeepermkdir /zookeeper/datamkdir /zookeeper/logs# 同步# 自行枚举添加配置文件
cp $ZOOKEEPER_HOME/conf/zoo_sample.cfg $ZOOKEEPER_HOME/conf/zoo.cfgvim $ZOOKEEPER_HOME/conf/zoo.cfg修改和添加
tickTime=2000initLimit=10syncLimit=5dataDir=/zookeeper/datadataLogDir=/zookeeper/logsclientPort=2181server.1=master:2888:3888server.2=slea1:2888:3888server.3=slea2:2888:3888server.4=slea3:2888:3888:observer到 master 下执行请根据节点个数枚举执行
同步文件
scp /etc/profile root@slave1:/etc/scp -r /zookeeper root@slave1:/scp -r /usr/local/zookeeper root@slave1:/usr/local/配置节点标识
参考资资料:leader 选举
ssh master "echo "9" > /zookeeper/data/myid"ssh slave1 "echo "1" > /zookeeper/data/myid"ssh slave2 "echo "2" > /zookeeper/data/myid"ssh slave3 "echo "3" > /zookeeper/data/myid"防火墙配置
#开放端口firewall-cmd --add-port=2181/tcp --permanentfirewall-cmd --add-port=2888/tcp --permanentfirewall-cmd --add-port=3888/tcp --permanent#重新加载防火墙配置firewall-cmd --reload节点批量执行
# master节点ssh master "firewall-cmd --add-port=2181/tcp --permanent && firewall-cmd --add-port=2888/tcp --permanent && firewall-cmd --add-port=3888/tcp --permanent && firewall-cmd --reload "# slave1节点 其他请自行枚举执行ssh slave1 "firewall-cmd --add-port=2181/tcp --permanent && firewall-cmd --add-port=2888/tcp --permanent && firewall-cmd --add-port=3888/tcp --permanent && firewall-cmd --reload "启动 ZooKeeper
sh $ZOOKEEPER_HOME/bin/zkServer.sh start编写批量启动 shell
vim /bin/zk && chmod 777 /bin/zk#! /bin/shcase $1 in"start"){ echo -e "/e[32m---------------------------------------------------------------------------/033[0m" echo -e "/e[32m...master-start.../033[0m" ssh master "sh $ZOOKEEPER_HOME/bin/zkServer.sh start" echo -e "/e[32m...slave1-start.../033[0m" ssh slave1 "sh $ZOOKEEPER_HOME/bin/zkServer.sh start" echo -e "/e[32m...slave2-start.../033[0m" ssh slave2 "sh $ZOOKEEPER_HOME/bin/zkServer.sh start" echo -e "/e[32m...slave3-start.../033[0m" ssh slave3 "sh $ZOOKEEPER_HOME/bin/zkServer.sh start" echo -e "/e[32m...all-start-end.../033[0m" echo -e "/e[32m---------------------------------------------------------------------------/033[0m"};;"stop"){ echo -e "/e[32m---------------------------------------------------------------------------/033[0m" echo -e "/e[32m...master-stop.../033[0m" ssh master "sh $ZOOKEEPER_HOME/bin/zkServer.sh stop" echo -e "/e[32m...slave1-start.../033[0m" ssh slave1 "sh $ZOOKEEPER_HOME/bin/zkServer.sh stop" echo -e "/e[32m...slave2-start.../033[0m" ssh slave2 "sh $ZOOKEEPER_HOME/bin/zkServer.sh stop" echo -e "/e[32m...slave3-start.../033[0m" ssh slave3 "sh $ZOOKEEPER_HOME/bin/zkServer.sh stop" echo -e "/e[32m...all-stop-end.../033[0m" echo -e "/e[32m---------------------------------------------------------------------------/033[0m"};;"status"){ echo -e "/e[32m---------------------------------------------------------------------------" echo -e "/e[32m...master-status.../033[0m" ssh master "sh $ZOOKEEPER_HOME/bin/zkServer.sh status" echo -e "/e[32m...slave1-start.../033[0m" ssh slave1 "sh $ZOOKEEPER_HOME/bin/zkServer.sh status" echo -e "/e[32m...slave2-start.../033[0m" ssh slave2 "sh $ZOOKEEPER_HOME/bin/zkServer.sh status" echo -e "/e[32m...slave3-start.../033[0m" ssh slave3 "sh $ZOOKEEPER_HOME/bin/zkServer.sh status" echo -e "/e[32m...all-status-end.../033[0m" echo -e "/e[32m---------------------------------------------------------------------------/033[0m"};;esac命令
# 启动zk start# 查看状态zk status# 关闭zk stop启动之后 MODE 和我的显示一样就算成功了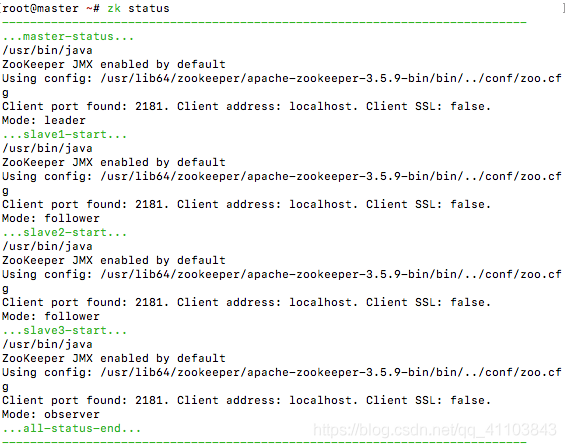
此文采用版本 Hadoop3.2.2
官方下载地址:Hadoop
从客户端上下载 压缩包
到 master 节点上创建 Hadoop 文件夹
mkdir /usr/local/hadoop从客户端上传到 master
scp 你下载的hadoop路径 root@master:/usr/local/hadoop以下操作切换至master节点上
解压
cd /usr/local/hadoop tar xf hadoop包名打开配置文件
vim /etc/profile在末尾添加
# Hadoop 3.2.2 # 添加hadoop地址变量 HADOOP_HOME=/usr/local/hadoop/hadoop-3.3.0 # 添加PATH地址变量 PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin # 使变量生效 export HADOOP_HOME PATH# IF HADOOP >= 3x / for root # HDFS HDFS_DATANODE_USER=root HADOOP_SECURE_DN_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root HDFS_ZKFC_USER=root # YARN YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root # run export HDFS_DATANODE_USER HADOOP_SECURE_DN_USER HDFS_NAMENODE_USER HDFS_SECONDARYNAMENODE_USER HDFS_ZKFC_USER YARN_RESOURCEMANAGER_USER HADOOP_SECURE_DN_USER YARN_NODEMANAGER_USER请自行使用scp将文件同步至各节点
刷新配置文件
source /etc/profile创建数据目录
mkdir /hadoopmkdir /hadoop/journaldatamkdir /hadoop/hadoopdata# 同步# 自行枚举添加 Jdk 环境
打开文件
vim /usr/local/hadoop/hadoop-3.3.0/etc/hadoop/hadoop-env.sh添加或修改
export JAVA_HOME=/usr/local/java接下来我们要修改的文件:
前往配置文件目录
cd /usr/local/hadoop/hadoop-3.3.0/etc/hadoop/core-site.xml
fs.defaultFS hdfs://jed hadoop.tmp.dir /hadoop/hadoopdata ha.zookeeper.quorum master:2181,slave1:2181,slave2:2181,slave3:2181 hdfs-site.xml
dfs.replication 2 dfs.nameservices jed dfs.ha.namenodes.jed nn1,nn2 dfs.namenode.rpc-address.jed.nn1 master:9000 dfs.namenode.http-address.jed.nn1 master:50070 dfs.namenode.rpc-address.jed.nn2 slave1:9000 dfs.namenode.http-address.jed.nn2 slave1:50070 dfs.namenode.shared.edits.dir qjournal://master:8485;slave1:8485;slave2:8485/jed dfs.journalnode.edits.dir /hadoop/journaldata dfs.ha.automatic-failover.enabled true dfs.client.failover.proxy.provider.jed org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider dfs.ha.fencing.methods sshfence shell(/bin/true) dfs.ha.fencing.ssh.private-key-files /var/root/.ssh/id_rsa dfs.ha.fencing.ssh.connect-timeout 20000 mapred-site.xml
mapreduce.framework.name yarn mapreduce.jobhistory.address master:10020 mapreduce.jobhistory.webapp.address master:19888 yarn.app.mapreduce.am.env HADOOP_MAPRED_HOME=${HADOOP_HOME} mapreduce.map.env HADOOP_MAPRED_HOME=${HADOOP_HOME} mapreduce.reduce.env HADOOP_MAPRED_HOME=${HADOOP_HOME} yarn-site.xml
yarn.resourcemanager.ha.enabled true yarn.resourcemanager.cluster-id Cyarn yarn.resourcemanager.ha.rm-ids rm1,rm2 yarn.resourcemanager.hostname.rm1 slave2 yarn.resourcemanager.webapp.address.rm1 slave2 yarn.resourcemanager.hostname.rm2 slave3 yarn.resourcemanager.webapp.address.rm2 slave3 yarn.resourcemanager.zk-address master:2181,slave1:2181,slave2:2181,slave3:2181 yarn.nodemanager.aux-services mapreduce_shuffle yarn.log-aggregation-enable true yarn.log-aggregation.retain-seconds 86400 yarn.resourcemanager.recovery.enabled true yarn.resourcemanager.store.class org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore workers注意!在Hadoop3x以前的版本是 slaves 文件
masterslave1slave2slave3使用 scp 分发给其他节点
scp -r /usr/local/hadoop slave1:/usr/local/请自行枚举执行
使用之前的 zk 脚本启动 zeekeeper 集群
zk start分别在每个 journalnode 节点上启动 journalnode 进程
# master slave1 slave2hadoop-daemon.sh start journalnode在第一个 namenode 节点上格式化文件系统
hadoop namenode -format同步两个 namenode 的元数据
查看你配置的 hadoop.tmp.dir 这个配置信息,得到 hadoop 工作的目录,我的是/hadoop/hadoopdata/
把 master 上的 hadoopdata 目录发送给 slave1 的相同路径下,这一步是为了同步两个 namenode 的元数据
scp -r /hadoop/hadoopdata slave1:/hadoop/也可以在 slave1 执行以下命令:
hadoop namenode -bootstrapStandby格式化 ZKFC(任选一个 namenode 节点格式化)
hdfs zkfc -formatZK启动 hadoop 集群
start-all.sh相关命令请前往 $HADOOP_HOME/sbin/ 查看
启动 mapreduce 任务历史服务器
mr-jobhistory-daemon.sh start historyserver编写 jps 集群脚本
vim /bin/jpall && chmod 777 /bin/jpall#! /bin/sh echo -e "/e[32m---------------------------------------------------------------------------/033[0m" echo -e "/e[32m...master-jps.../033[0m" ssh master "jps" echo -e "/e[32m...slave1-jps.../033[0m" ssh slave1 "jps" echo -e "/e[32m...slave2-jps.../033[0m" ssh slave2 "jps" echo -e "/e[32m...slave3-jps.../033[0m" ssh slave3 "jps" echo -e "/e[32m...all-jps-end.../033[0m" echo -e "/e[32m---------------------------------------------------------------------------/033[0m"运行
jpall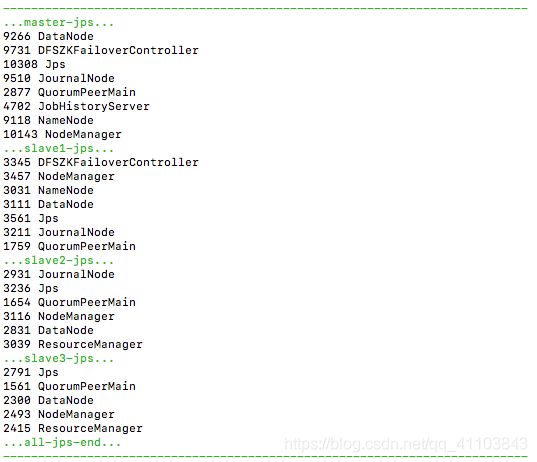
查看各节点的主备状态
hdfs haadmin -getServiceState nn1查看 HDFS 状态
hdfs dfsadmin -reportWEB 访问可以直接浏览器: IP:50070
上传一个文件
hdfs dfs -put test.outcheck
hdfs dfs -ls /user/root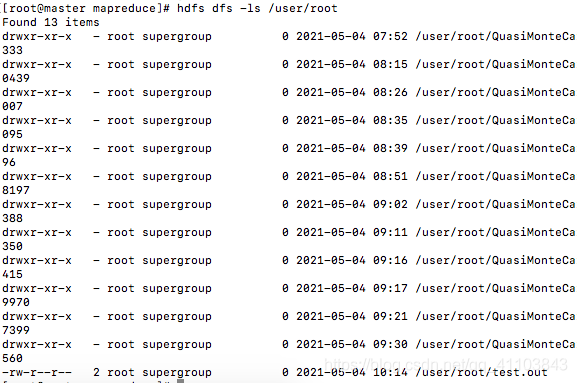
hadoop fs -rm -r -skipTrash /user/root/test.out删除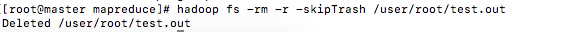
我们使用 hadoop 自带的圆周率测试
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar pi 5 5运行结果
查看进程
jps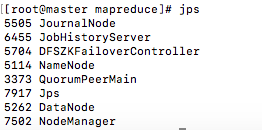
杀死进程
kill -9 5114现在 master 已不是 namenode 了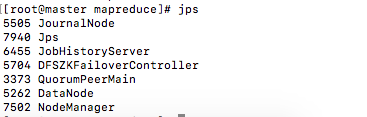
现在 slave1 变成了主节点
恢复 master 节点
hadoop-daemon.sh start namenode
master 变成了 standby,什么 HA 具备
删除所有节点中 hadoop 的工作目录(core-site.xml 中配置的 hadoop.tmp.dir 那个目录)
如果你在 core-site.xml 中还配置了 dfs.datanode.data.dir 和 dfs.datanode.name.dir 这两个配置,那么把这两个配置对应的目录也删除
删除所有节点中 hadoop 的 log 日志文件,默认在 HADOOP_HOME/logs 目录下
删除 zookeeper 集群中所关于 hadoop 的 znode 节点
图中的红色框中 rmstore 这个节点不能删除,删除另外两个就可以
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/123650.html

阅读 832·2023-04-25 19:43
阅读 4086·2021-11-30 14:52
阅读 3910·2021-11-30 14:52
阅读 4000·2021-11-29 11:00
阅读 3895·2021-11-29 11:00
阅读 4022·2021-11-29 11:00
阅读 3738·2021-11-29 11:00
阅读 6459·2021-11-29 11:00