
摘要:开发指南开发指南开发指南本篇目录运行运行定义定义定义工作流,为将多个按照一定的顺序组织起来,按照既定的路径运行的一个整体。配置将定时调度频率改为分钟。一个会创建并执行。例如,,,,则时间为动作的实际创建时间。
Oozie定义工作流,为将多个Hadoop Job按照一定的顺序组织起来,按照既定的路径运行的一个整体。通过启动工作流,就会执行该工作流中的多个Hadoop Job,直到完成。这就是工作流的生命周期。
Oozie提出了Coordinator的概念,能够将每个工作流的Job作为一个Action来运行。相当于工作流中的一个执行节点。这样就能够将多个工作流Job组织起来,称为Coordinator Job,并制定触发时间和频率,还可以配置数据集、并发数等。一个Coordinator Job包含了在Job外部设置执行周期和频率的语义。类似于在工作流外部专家了一个协调器来管理这些工作流的工作流Job的运行。
如果在集群安装了Hue,也可以通过页面操作配置工作流,具体操作步骤点此查看。以下介绍通过后台配置工作流的方法:
先看一下官方发行包自带的一个简单例子 oozie/examples/src/main/apps/cron。它能够实现定时调度一个工作流Job运行,这个例子中给出的一个空的工作流Job,也是为了演示能够使用Coordinator系统给调度起来。
这个例子有3个配置文件。修改后分别如下所示:
job.properties配置nameNode=hdfs://uhadoop-XXXXXX-master1:8020
jobTracker=uhadoop-XXXXXX-master1:23140
queueName=default
examplesRoot=examples
oozie.coord.application.path=${nameNode}/user/${user.name}/${examplesRoot}/apps/cron
start=2016-12-01T19:00Z
end=2016-12-31T01:00Z
workflowAppUri=${nameNode}/user/${user.name}/${examplesRoot}/apps/cron修改了Hadoop集群的配置,以及调度起止时间范围。
wordflow.xml<workflow-app xmlns="uri:oozie:workflow:0.5" name="one-op-wf">
<start to="action1"/>
<action name="action1">
<fs/>
<ok to="end"/>
<error to="end"/>
action>
<end name="end"/>
workflow-app>这是一个空Job,没做任何修改。
corrdinator.xml配置<coordinator-app name="cron-coord" frequency="${coord:minutes(2)}" start="${start}" end="${end}" timezone="UTC" xmlns="uri:oozie:coordinator:0.2">
<action>
<workflow>
<app-path>${workflowAppUri}app-path>
<configuration>
<property>
<name>jobTrackername>
<value>${jobTracker}value>
property>
<property>
<name>nameNodename>
<value>${nameNode}value>
property>
<property>
<name>queueNamename>
<value>${queueName}value>
property>
configuration>
workflow>
action>
coordinator-app>将定时调度频率改为2分钟。然后,将这3个文件上传到HDFS上。
启动一个Coordinator Job和启动一个Oozie工作流Job类似,执行如下命令即可:
bin/oozie job -oozie http://uhadoop-XXXXXX-master2:11000/oozie -config /home/hadoop/oozie/examples/src/main/apps/cron/job.properties -run运行上面命令,在控制台上会返回这个Job的ID,我们也可以通过Oozie的Web控制台来查看。
一个Coordinator Job会创建并执行Coordinator Action。通常一个Coordinator Action是一个工作流Job,这个工作流Job会生成一个dataset实例并处理这个数据集。当一个Coordinator Action被创建以后,它会一直等待满足执行条件的所有输入事件的完成然后执行,或者发生超时。
每个Coordinator Job都有一个驱动事件,来决定它所包含的Coordinator Action的初始化。对于同步Coordinator Job来说,触发执行频率就是一个驱动事件。同样,组成Coordinator Job的基本单元是Coordinator Action,它不像Oozie工作流Job只有OK和Error两个执行结果,一个Coordinator 动作的状态集合,如下所示:
WAITING
READY
SUBMITTED
TIMEDOUT
RUNNING
KILLED
SUCCEEDED
FAILED
Coordinator Application当满足一定条件时,会触发Oozie工作流。其中,触发条件可以是一个时间频率、一个dataset实例是否可用,或者可能是外部的其他事件。 Coordinator Job是一个Coordinator应用的运行实例,这个Coordinator Job是在Oozie提供的Coordinator引擎上运行的,并且这个实例从指定的时间开始,直到运行结束。一个Coordinator Job具有以下几个状态:
PREP
RUNNING
RUNNINGWITHERROR
PREPSUSPENDED
SUSPENDED
SUSPENDEDWITHERROR
PREPPAUSED
PAUSED
PAUSEDWITHERROR
SUCCEEDED
DONEWITHERROR
KILLED
FAILED
Coordinator Job的状态比一个基本的Oozie工作流Job的状态要复杂的多。因为Coordinator Job的基本执行单元可能是一个基本Oozie Job,而且外加了一些调度信息,必然要增加额外的状态来描述。
一个同步的Coordinator Appliction定义的语法格式,如下所示:
<coordinator-app name="[NAME]" frequency="[FREQUENCY]" start="[DATETIME]" end="[DATETIME]" timezone="[TIMEZONE]" xmlns="uri:oozie:coordinator:0.1">
<controls>
<timeout>[TIME_PERIOD]timeout>
<concurrency>[CONCURRENCY]concurrency>
<execution>[EXECUTION_STRATEGY]execution>
controls>
<datasets>
<include>[SHARED_DATASETS]include>
...
<dataset name="[NAME]" frequency="[FREQUENCY]" initial-instance="[DATETIME]" timezone="[TIMEZONE]">
<uri-template>[URI_TEMPLATE]uri-template>
dataset>
...
datasets>
<input-events>
<data-in name="[NAME]" dataset="[DATASET]">
<instance>[INSTANCE]instance>
...
data-in>
...
<data-in name="[NAME]" dataset="[DATASET]">
<start-instance>[INSTANCE]start-instance>
<end-instance>[INSTANCE]end-instance>
data-in>
...
input-events>
<output-events>
<data-out name="[NAME]" dataset="[DATASET]">
<instance>[INSTANCE]instance>
data-out>
...
output-events>
<action>
<workflow>
<app-path>[WF-APPLICATION-PATH]app-path>
<configuration>
<property>
<name>[PROPERTY-NAME]name>
<value>[PROPERTY-VALUE]value>
property>
...
configuration>
workflow>
action>
coordinator-app>基于上述定义语法格式,我们分别说明对应元素的含义,如下所示:
control元素 元素名称含义说明timeout超时时间,单位为分钟。当一个CoordinatorJob启动的时候,会初始化多个Coordinator动作,timeout用来限制这个初始化过程。默认值为-1,表示永远不超时,如果为0则总是超时。concurrency并发数,指多个CoordinatorJob并发执行,默认值为1。execution配置多个CoordinatorJob并发执行的策略:默认是FIFO。另外还有两种:LIFO(最新的先执行)、LAST_ONLY(只执行最新的CoordinatorJob,其它的全部丢弃)。throttle一个CoordinatorJob初始化时,允许Coordinator动作处于WAITING状态的最大数量。 dataset元素Coordinator Job中有一个Dataset的概念,它可以为实际计算提供计算的数据,主要是指HDFS上的数据目录或文件,能够配置数据集生成的频率(Frequency)、URI模板、时间等信息,下面看一下dataset的语法格式:
<dataset name="[NAME]" frequency="[FREQUENCY]" initial-instance="[DATETIME]" timezone="[TIMEZONE]">
<uri-template>[URI TEMPLATE]uri-template>
<done-flag>[FILE NAME]done-flag>
dataset>举例如下:
<dataset name="stats_hive_table" frequency="${coord:days(1)}" initial-instance="2016-12-25T00:00Z" timezone="America/Los_Angeles">
<uri-template>
hdfs://m1:9000/hive/warehouse/user_events/${YEAR}${MONTH}/${DAY}/data
uri-template>
<done-flag>donefile.flagdone-flag>
dataset>上面会每天都会生成一个用户事件表,可以供Hive查询分析,这里指定了这个数据集的位置,后续计算会使用这部分数据。其中,uri-template指定了一个匹配的模板,满足这个模板的路径都会被作为计算的基础数据。 另外,还有一种定义dataset集合的方式,将多个dataset合并成一个组来定义,语法格式如下所示:
<datasets>
<include>[SHARED_DATASETS]include>
...
<dataset name="[NAME]" frequency="[FREQUENCY]" initial-instance="[DATETIME]" timezone="[TIMEZONE]">
<uri-template>[URI TEMPLATE]uri-template>
dataset>
...
datasets>一个Coordinator Application的输入事件指定了要执行一个Coordinator动作必须满足的输入条件,在Oozie当前版本,只支持使用dataset实例。
一个Coordinator Action可能会生成一个或多个dataset实例,在Oozie当前版本,输出事件只支持输出dataset实例。
常量表示形式含义说明${coord:minutes(intn)}返回日期时间:从一开始,周期执行n分钟${coord:hours(intn)}返回日期时间:从一开始,周期执行n*60分钟${coord:days(intn)}返回日期时间:从一开始,周期执行n*24*60分钟${coord:months(intn)}返回日期时间:从一开始,周期执行n*M*24*60分钟(M表示一个月的天数)${coord:endOfDays(intn)}返回日期时间:从当天的最晚时间(即下一天)开始,周期执行n*24*60分钟${coord:endOfMonths(1)}返回日期时间:从当月的最晚时间开始(即下个月初),周期执行n*24*60分钟${coord:current(intn)}返回日期时间:从一个Coordinator动作(Action)创建时开始计算,第n个dataset实例执行时间${coord:dataIn(Stringname)}在输入事件(input-events)中,解析dataset实例包含的所有的URI${coord:dataOut(Stringname)}在输出事件(output-events)中,解析dataset实例包含的所有的URI${coord:offset(intn,StringtimeUnit)}表示时间偏移,如果一个Coordinator动作创建时间为T,n为正数表示向时刻T之后偏移,n为负数向向时刻T之前偏移,timeUnit表示时间单位(选项有MINUTE、HOUR、DAY、MONTH、YEAR)${coord:hoursInDay(intn)}指定的第n天的小时数,n>0表示向后数第n天的小时数,n=0表示当天小时数,n<0表示向前数第n天的小时数${coord:daysInMonth(intn)}指定的第n个月的天数,n>0表示向后数第n个月的天数,n=0表示当月的天数,n<0表示向前数第n个月的天数${coord:tzOffset()}dataset对应的时区与CoordinatorJob的时区所差的分钟数${coord:latest(intn)}最近以来,当前可以用的第n个dataset实例${coord:future(intn,intlimit)}当前时间之后的dataset实例,n>=0,当n=0时表示立即可用的dataset实例,limit表示dataset实例的个数${coord:nominalTime()}nominal时间等于CoordinatorJob启动时间,加上多个CoordinatorJob的频率所得到的日期时间。例如:start=”2009-01-01T24:00Z”,end=”2009-12-31T24:00Z”,frequency=”${coord:days(1)}”,frequency=”${coord:days(1)},则nominal时间为:2009-01-02T00:00Z、2009-01-03T00:00Z、2009-01-04T00:00Z、…、2010-01-01T00:00Z${coord:actualTime()}Coordinator动作的实际创建时间。例如:start=”2011-05-01T24:00Z”,end=”2011-12-31T24:00Z”,frequency=”${coord:days(1)}”,则实际时间为:2011-05-01,2011-05-02,2011-05-03,…,2011-12-31${coord:user()}启动当前CoordinatorJob的用户名称${coord:dateOffset(StringbaseDate,intinstance,StringtimeUnit)}计算新的日期时间的公式:newDate=baseDate+instance*timeUnit,如:baseDate=’2009-01-01T00:00Z’,instance=’2′,timeUnit=’MONTH’,则计算得到的新的日期时间为’2009-03-01T00:00Z’。${coord:formatTime(StringtimeStamp,Stringformat)}格式化时间字符串,format指定模式。文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/126871.html
摘要:创建任务创建任务选择这个标签拖动到中。页面权限控制页面权限控制页面权限控制点击管理用户组选择要修改的组名称,设置相应权限并保存 Hue开发指南本篇目录1. 配置工作流2. Hue页面权限控制Hue是面向 Hadoop 的开源用户界面,可以让您更轻松地运行和开发 Hive 查询、管理 HDFS 中的文件、运行和开发 Pig 脚本以及管理表。服务默认已经启动,用户只需要配置外网IP,在防火墙中配...

摘要:也可以将托管集群设置为快捷方式,通过左侧快捷方式菜单栏点击进入。框架集群中仅部署。用于做存储集群,有专属的节点机型。节点管理节点,负责协调整个集群服务。目前仅节点支持绑定。通过云主机内网进行登录。登录密码为集群创建时设置的密码。 快速上手本篇目录创建集群提交任务本文档将带领您如何创建UHadoop集群,并使用UHadoop集群完成数据处理任务。创建集群本章简单介绍了用户使用UHadoop服务...
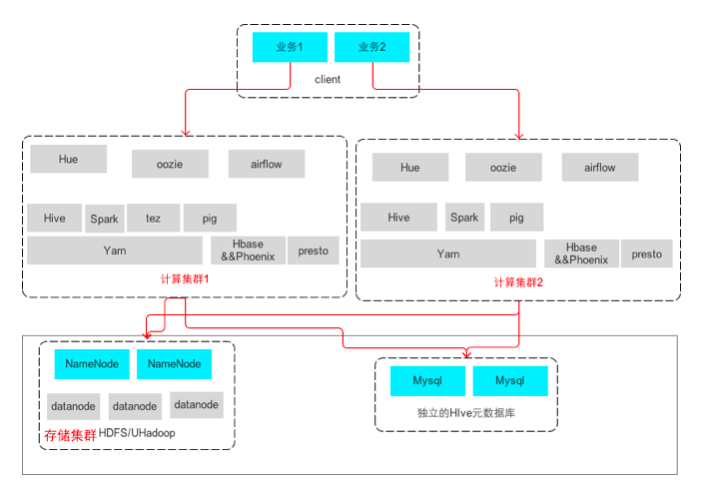
摘要:架构架构元数据管理元数据管理元数据管理创建集群时可在控制台开启元数据独立管理。若项目中已开启过元数据独立管理,则新集群开启该功能时,不再创建新的,而是将新集群的元数据存储于已有的中。 元数据管理本篇目录介绍产品架构元数据管理介绍UHadoop 支持将 Hive-Metastore 的数据库独立于 Hadoop 集群部署,也支持多个集群访问同一个 Hive 元数据库,可在控制台对其做管理。产品...
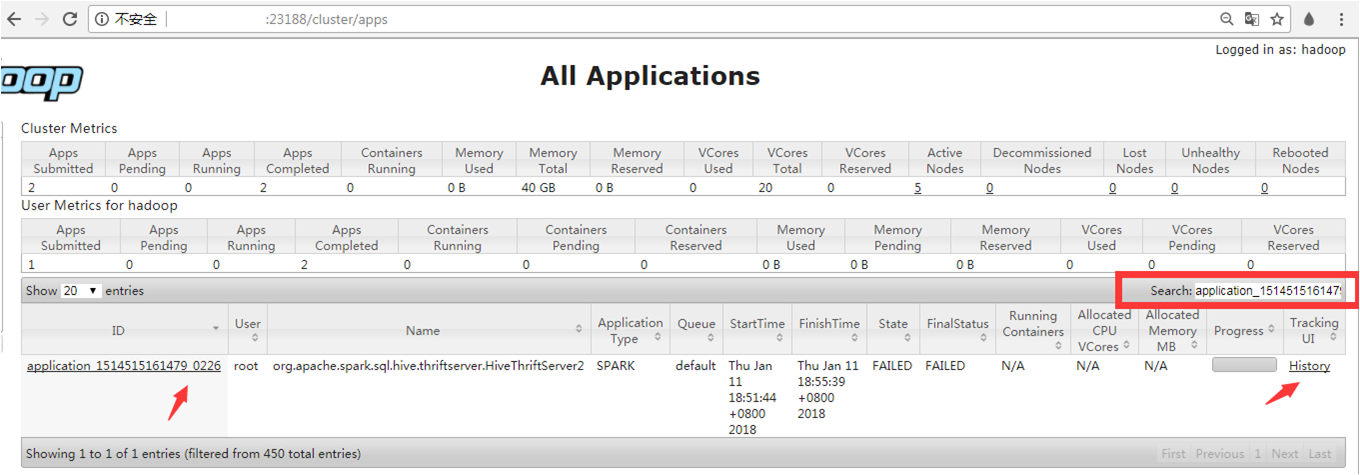
摘要:查看上的历史日志查看上的历史日志任务的日志在任务运行结束之后会上传到上,当日志文件过大无法通过来查看时,可以通过将日志文件从上下载下来查看。挂载在允许的主机上执行 常用操作本篇目录应用的Web接口查看日志配置NFS挂载hdfs到本地应用的Web接口Hadoop 提供了基于 Web 的用户界面,可通过它查看您的 Hadoop 集群。Web 服务会在主节点上运行(Active NameNode或...
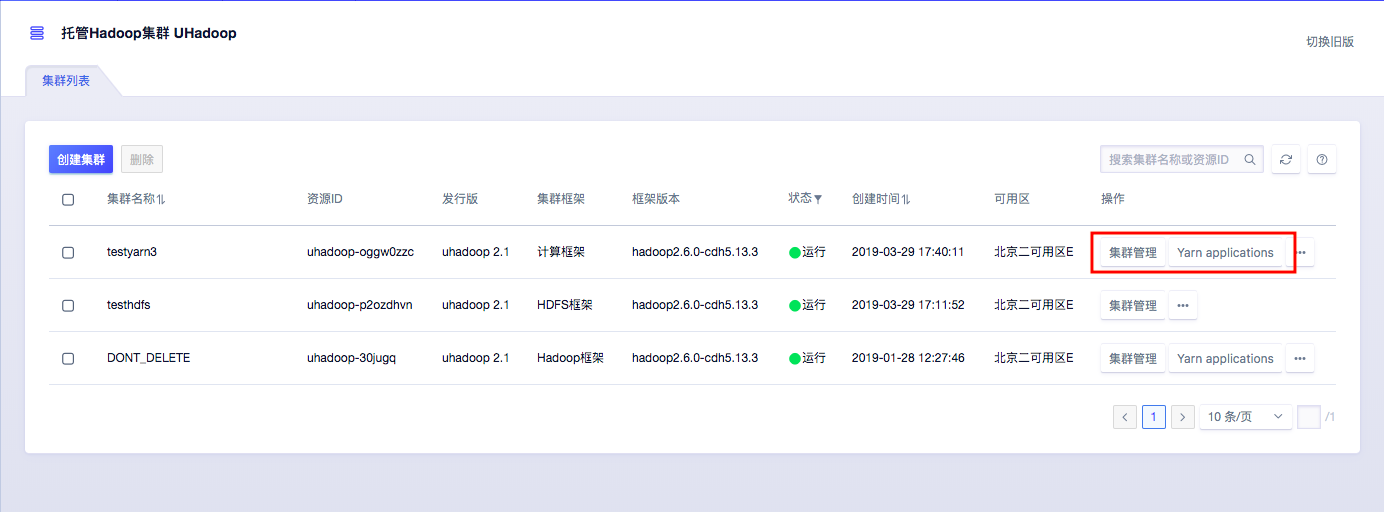
摘要:监控数据查看监控数据查看用户可于产品界面右侧弹框中查看集群监控数据,也可进入监控视图中进行详细查看集群及各节点监控数据信息。 基本操作本篇目录集群管理服务管理告警与监控数据均衡Yarn Application跟踪集群管理1、进入集群管理页面通过UHadoop集群列表页面进入集群管理页面:2、获取当前节点配置信息本例中,Master 节点数量 2,机型为 C1-large;Core 节点数量为...

阅读 2187·2025-02-07 13:29
阅读 1547·2024-11-07 18:25
阅读 132331·2024-02-01 10:43
阅读 2185·2024-01-31 14:58
阅读 1271·2024-01-31 14:54
阅读 84056·2024-01-29 17:11
阅读 4189·2024-01-25 14:55
阅读 2542·2023-06-02 13:36
