ElasticSearch全文搜索进阶
点击上方“IT那活儿”,关注后了解更多内容,不管IT什么活儿,干就完了!!!
索引(index) -- Elasticsearch通过索引的方式对逻辑数据进行逻辑存储。索引类似于关系型数据库中的表,索引的结构是为了进行快速有效的全文索引,索引不保存原始值。可将索引多带带放在一台主机或分散在多个主机上,每个索引至少有一个或多个分片,每个分片可以有多个副本。
文档 -- 文档是存储在Elasticsearch中的主要实体,一个文档就是索引所对应的一条记录。Elasticsearch的文档有不同的结构,但相同的字段必须是相同类型。文档可以有多个字段,每个字段可能在一个文档中多次出现,这类字段称为多值字段。字段的类型可以是数值、文本或日期,复杂类型的字段可以包含其他文档或数组。映射 -- 文档写进索引前需要进行分析,即写入的文本如何分割为词条、词条是否又会被过滤,这样的分析行为就是映射,映射规则一般由用户自定义。 非结构化索引即不需要创建索引结构既可写入数据到索引中,但实际上在Elasticsearch底层会进行结构化操作,如下示例创建空索引。 更新文档时的数据其实是不会被修改的,而是通过覆盖的形式进行更新,即更新文档的版本号,版本号+1。如下查看结果数据已更新: 同样也可以局部更新数据,即更新文档中的指定字段。更新时,先查询这个文档的数据,然后进行覆盖操作。步骤为:先从旧文档中检索、修改、删除旧文档、索引新文档。如下,通过_update标识局部更新数据: 通过DELETE可以删除文档数据,文档删除后并不会立即从磁盘移除,而是将状态标记为已删除,Elasticsearch会在满足特定条件后自动进行已删除内容的清理。如下返回信息中result:deleted即已删除,同时_version也+1了。 DSL(Domain Specific Language)是Elasticsearch提供的查询语言,支持复杂、强大的查询,DSL以JSON请求体的形式进行查询。 全文搜索,查询firstname为Blake或Vera的员工。 Elasticsearch也支持聚合操作,类似SQL中的group by操作。如下对age字段进行聚合操作,31岁的员工有61位,39岁的员工有60位。
1. routing -- 当文档在集群中保存时,文档应该存储在哪个节点呢?随机还是轮询?Elasticsearch采用如下计算方式来确定文档应该存储到的节点位置。计算公式:Shard = hash(routing) % number_of_primary_shardsRouting值可以是任意字符串,默认是_id,也可以自定义。Routing字符串通过hash函数生成一个数字,然后除以主分片的数量得到一个余数,余数的范围是0到number_of_primary_shards-1,这个数字就是文档所存储的节点位置。2. 写操作 -- 索引的新建、删除都是写操作,必须在主分片上成功执行才可复制到副分片上。下图展示了在主副分片上新建索引和删除文档的必要步骤:1)客户端向NODE1节点发送新建索引或删除文档的请求。2)NODE1节点使用文档的_id确定文档属于分片0,分片0存放在NODE3节点,于是将请求转发到NODE3节点上。NODE3在主分片上执行请求,执行成功后就转发请求到NODE1和NODE2的副节点上。当所有的副节点执行成功,NODE3返回执行成功到请求节点,请求节点在返回给客户端。客户端收到执行成功后,文档的修改已应用于所有的主分片,即修改生效。3. 搜索单个文档 -- 文档可以从主副分片中检索,读请求时,为了负载的均衡,请求节点会将请求发送到不同的分片,即循环遍历所有的分片副本。当一个文档已在主分片上保存,但同步到副分片还未完成,此时搜索该文档时,副分片返回文档未找到,主分片成功返回文档。 2)NODE1节点通过_id确定文档属于分片0,分片0在三个节点上都存在,将请求转发到NODE2节点。 3)NODE2节点返回文档给NODE1节点,NODE1节点返回文档给客户端。4. 全文搜索 -- 文档通常分散在各个节点上,如何在分布式的情况下进行全文搜索。通常分为两个阶段:搜索和取回。
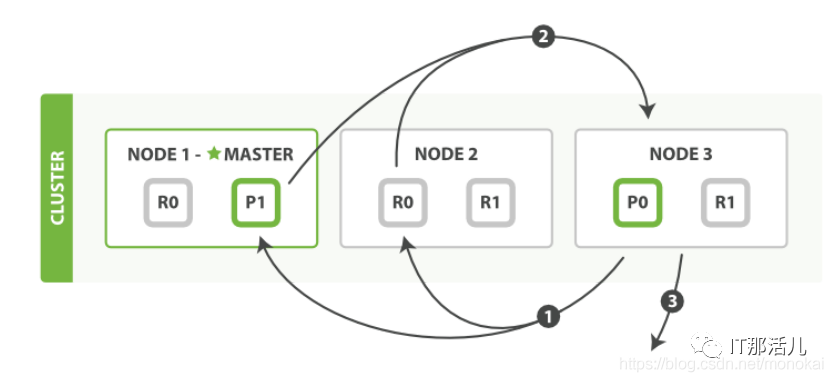
4.1 搜索过程:
1)客户端发送搜索请求到NODE3,NODE3创建长度为from+size的空优先级队列。
2)转发搜索请求到索引中每个主副分片,每个分片在本地执行查询,并将查询结果放到from+size的有序本地优先级队列中。
3)每个分片向NODE3节点返回文档的id和优先级队列中所有文档的排序值,NODE3把这些排序值合并到自己的优先级队列中并产生全局的排序结果。
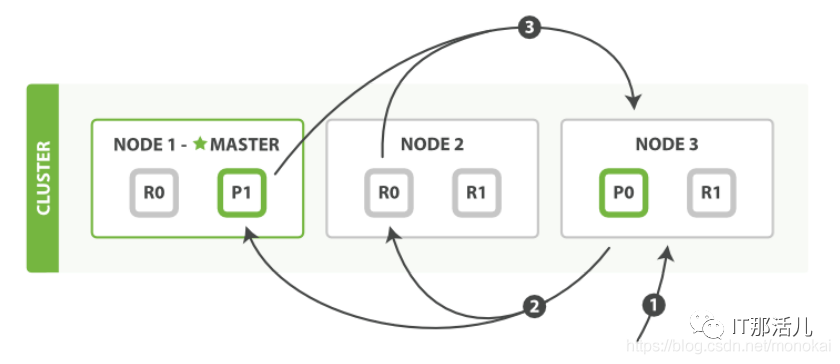
4.2 取回过程:
1)协调节点识别出需要取回的文档,并且向相关分片发出get请求。
2)每个分片加载文档并返回给协调节点。
3)直到所有的文档都被取回,协调节点将结果返回给客户端。
1. 元数据 -- 文档中不仅有数据,还有关于文档信息的元数据,元数据包括三个节点信息,分别是 _index、_type、_id。_index:即文档存储的位置。
实际上,数据是存储和索引在分片上,索引是把分片组织在一起的逻辑空间。
_type:即文档类型。
可以使用对象来表示一些事物,每个对象都属于一个类,类定义了属性或与对象关联的数据。Elasticsearch使用相同类型的文档表示相同的事物,因为其数据结构是相同的。
每个类型都有自己的映射或结果定义,所有类型下的文档被存储在同一个索引下。
_id:即文档唯一标识。
_id仅仅是一个字符串,与_index、_type组合时,就可以在elasticsearch中唯一标识一个文档。创建文档时,可以自定义_id,也可以有Elasticsearch自动生成一个32位长度的_id。
2.1 pretty -- 在查询url中使用pretty参数,返回的json格式的内容更易查看。2.2 指定响应字段 -- 如果不需要全部的字段,可以指定返回的字段。3. 判断文档是否存在 -- 可以使用head命令。4.1 批量查询,如果文档存在,则found值为true,否则为false。 批量请求时需要占用较多的内存,请求量越大,其他请求可用的内存就越小。一般会存在一个最佳的bulk请求值,超过这个值,性能可能不会提升,反而会降低。Bulk请求的最佳值并非固定值,取决于硬件性能、文档的大小和复杂度、索引和搜索的负载。当然,这个最佳值是可以被找到的。批量搜索文档时,随着文档大小或数量的增长,性能随之降低。一般建议在1000~5000个文档之间,若文档是在太大,可使用较小的批次。
创建索引和插入数据,Elasticsearch都会自动进行类型判断,当然也可以指定字段的类型,否则自动判断的类型和实际需求可能是不符的。| JSON type | Field type |
|---|
| Boolean: true or false | boolean |
| Whole number: 123 | long |
| Floating point: 123.45 | double |
| String, valid date: 2014-09-15 | date |
String: foo bar
| string
|
5.2 Elasticsearch支持的类型如下:| Task Details | Vital Task |
|---|
| Boolean | boolean |
Whole number
| byte , short , integer , long |
Floating point
| float , double |
Date
| date |
String
| string , text , keyword |
- String -- 最新版本不再支持string,使用text和keyword。
- text -- 全文搜索一个字段时,如Email内容、小说文本、产品描述,使用text类型。text类型的字段内容会被分析,在生成倒排索引以前,字符串会被分析器分成各个词项。
- keyword -- 适用于结构化的字段,如Email地址、IP地址、状态码等。需要对字段进行过滤、排序、聚合时,只能通过精确值搜索到keyword类型的字段。
6.1 term查询,用于精确匹配指定的值,如日期、数字、布尔值、字符串等。 6.2 terms查询,允许字段指定多个匹配值,类似于SQL中的in条件。 6.3 range查询,指定范围查询数据,gt:大于、gte:大于等于、lt:小于、lte:小于等于。6.4 exist查询,查询文档中是否包含指定字段。6.5 match查询,适用于全文本查询或精确查询。match查询一个全文本的字段时,会在查询前使用分析器对被查询的字符进行分析。若使用match查询一个指定的值,如数字、日期、字符串或布尔值,则将查询出指定的值。
7. 分词 -- 将文本转化为一系列的单词。如:太阳从东方升起-->太阳/从/东方/升起。可以指定分词器进行分词,也可以指定索引分词。中文分词与英文分词是有区别的,在英文中空格可以作为分隔符,而中文没有明显的词汇分界点。中文分词器有IK、jieba、thulac,但常用的是IK分词器。IK Aanlyzer是开源的,基于java开发的轻量级的中文分词工具包。它采用了特有的“正向迭代最细粒度切分算法”,高速处理能力可达到每秒80万字,采用多子处理器分析模式,支持数字(日期、数量词、科学计数法)、字母(URL、Email)、中文词汇(地名、姓名)的分词处理。需要多带带安装IK分词器插件,插件下载后解压到/elasticsearch/plugins/ik目录,重启elasticsearch即可。a. 新建索引student,增加字段name、age、address、hobby。8.3 逻辑”or”多词搜索并高亮显示,默认”or”搜索。8.5 通过mininum_should_match指定匹配度来搜索。8.6 组合搜索,must--必须包含,must_not--不能包含,should--如果包含。8.7 权重,在查询时可以增加权重来影响结果数据的得分,权重越大排序越靠前。

文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/129636.html



