
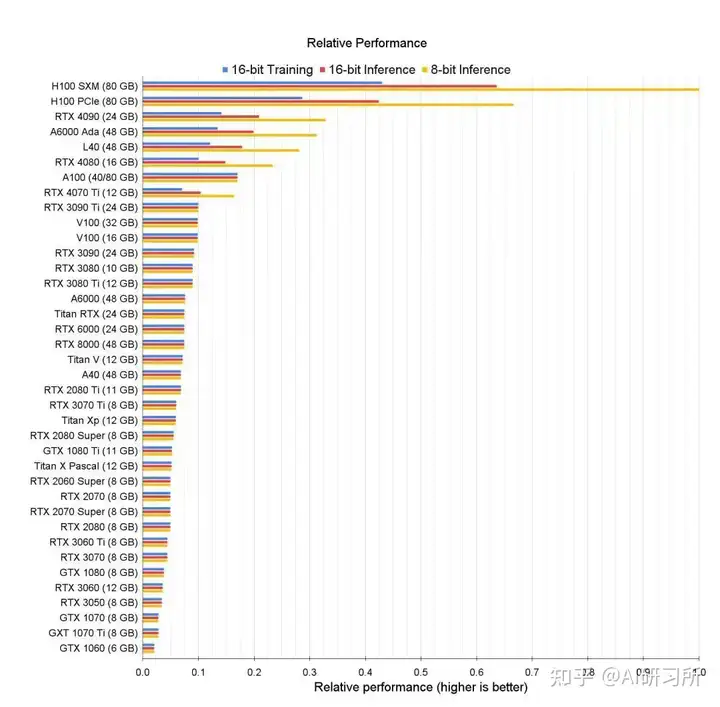
大模型的训练用4090是不合适的,但推理(inference/serving)用4090不能说合适,而是非常香!直接上图!
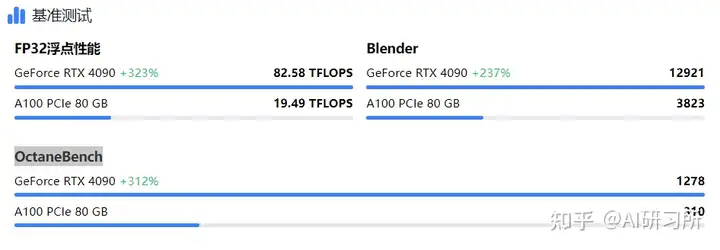
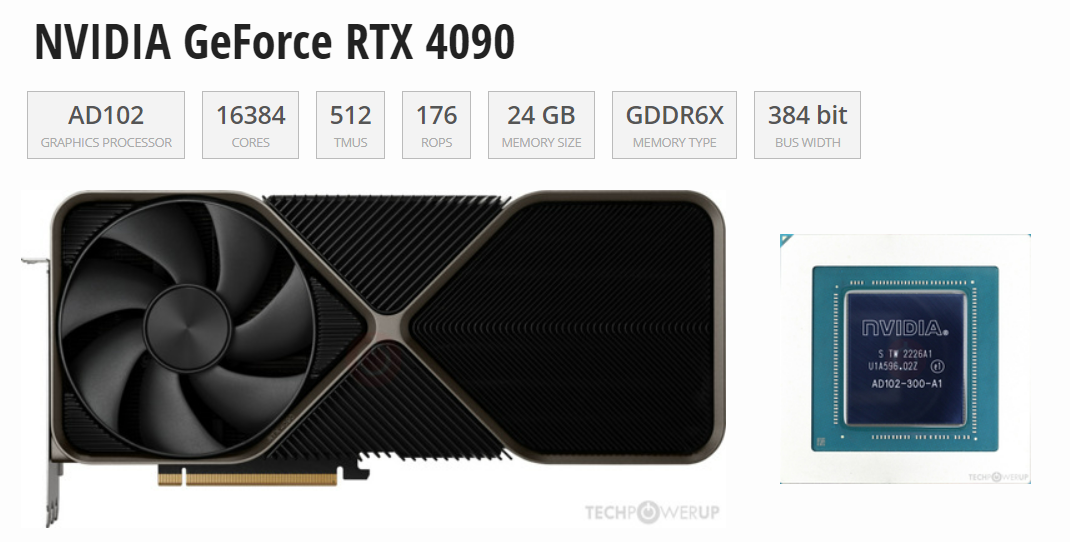
通过Tensor FP32(TF32)的数据来看,H100性能是全方面碾压4090,但是顶不住H100价格太贵,推理上使用性价比极低。但在和A100的PK中,4090与A100除了在显存和通信上有差异,算力差异与显存相比并不大,而4090是A100价格的1/10,因此如果用在模型推理场景下,4090性价比完胜!(尾部附参数源文件)

从推理性能层面看,4090在推理方面的性能是比A100更强的,没开混合精度的情况下,A100的FP32向量只有19.5T远低于4090的83T。同时在渲染场景Blender和OctaneBench基准测试中,4090性能也遥遥领先。从推理性能层面看,4090在推理方面的性能是比A100更强的,没开混合精度的情况下,A100的FP32向量只有19.5T远低于4090的83T。同时在渲染场景Blender和OctaneBench基准测试中,4090性能也遥遥领先。
推理性能排行:
首先我们需要计算一下推理需要多少计算量,根据公式:2 * 输出 token 数量 * 参数数量 flops
总的存储容量很好算,推理的时候最主要占内存的就是参数、KV Cache 和当前层的中间结果。当 batch size = 8 时,中间结果所需的大小是 batch size * token length * embedding size = 8 * 4096 * 8192 * 2B = 0.5 GB,相对来说是很小的。
70B 模型的参数是 140 GB,不管 A100/H100 还是 4090 都是单卡放不下的。那么 2 张 H100 够吗?看起来 160 GB 是够了,但是剩下的 20 GB 如果用来放 KV Cache,要么把 batch size 压缩一半,要么把 token 最大长度压缩一半,听起来是不太明智。因此,至少需要 3 张 H100。
对于 4090,140 GB 参数 + 40 GB KV Cache = 180 GB,每张卡 24 GB,8 张卡刚好可以放下。要知道H100的价格是4090的20倍左右。这个时候4090就非常香了!
首先,软件用的是StableDiffusion,模型使用的是SDXL,出图尺寸是888x1280,迭代步数50。A100出一张图花费11.5秒,而4090则略快,只需11.4秒,两者差异较小,但A100表现稍显颓势。
在绘制八张图的情况下,A100耗时87秒,而4090仅用80秒,4090表现出色,领先A100约8%。
总体来说,虽然RTX 4090可能不适合超大规模的AI训练任务,它的强大推理能力使其在大模型的推理应用中显得更为合适。尽管在数据中心和专业级AI训练任务中,Tesla A100和H100提供了更高的专业性和适应性,但考虑到成本和可接受的性能输出,RTX 4090为研究人员和技术企业提供了一种高效且经济的解决方案。对于那些寻求在预算内实现高效AI推理的用户,RTX 4090提供了一个既实用又前瞻的选择。
附高性能NVIDIA RTX 40 系列云服务器购买:
https://www.ucloud.cn/site/active/gpu.html?ytag=seo
https://www.compshare.cn/?ytag=seo
附H100、A100、4090官网参数文档:
4090: https://images.nvidia.com/aem-dam/Solutions/geforce/ada/nvidia-ada-gpu-architecture.pdf
H100:https://resources.nvidia.com/en
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/131081.html
图示为GPU性能排行榜,我们可以看到所有GPU的原始相关性能图表。同时根据训练、推理能力由高到低做了排名。我们可以看到,H100 GPU的8位性能与16位性能的优化与其他GPU存在巨大差距。针对大模型训练来说,H100和A100有绝对的优势首先,从架构角度来看,A100采用了NVIDIA的Ampere架构,而H100则是基于Hopper架构。Ampere架构以其高效的图形处理性能和多任务处理能力而...

DeepSeek-R1-671b动态量化版,由unsloth.ai发布,推荐使用多卡进行部署,具体操作如下。本镜像还附带32b的无限制版蒸馏模型,使用open-webui和ollama以及llama.cpp进行部署,内置所有环境,即拉即用。第一步:登录「优云智算」算力共享平台并进入「镜像社区」,新用户免费体验10小时4090地址:https://www.compshare.cn/?ytag=seo...

2023年12月28日 英伟达宣布正式发布GeForce RTX 4090D,对比于一年前上市的4090芯片,两者的区别与差异在哪?而在当前比较火热的大模型推理、AI绘画场景方面 两者各自的表现又如何呢?规格与参数信息对比现在先来看看GeForce RTX 4090D到底与之前的GeForce RTX 4090显卡有何区别。(左为4090 右为4090D)从简单的规格来看,GeForce RTX ...

随着大型模型技术的持续发展,视频生成技术正逐步走向成熟。以Sora、Gen-3等闭源视频生成模型为代表的技术,正在重新定义行业的未来格局。而近几个月,国产的AI视频生成模型也是层出不穷,像是快手可灵、字节即梦、智谱清影、Vidu、PixVerse V2 等。就在近日,智谱AI秉承以先进技术,服务全球开发者的理念,宣布将与清影同源的视频生成模型——CogVideoX开源,以期让每一位开发者、每一家企...

Llama3 中文聊天项目综合资源库,该文档集合了与Lama3 模型相关的各种中文资料,包括微调版本、有趣的权重、训练、推理、评测和部署的教程视频与文档。1. 多版本支持与创新:该仓库提供了多个版本的Lama3 模型,包括基于不同技术和偏好的微调版本,如直接中文SFT版、Instruct偏好强化学习版、趣味版等。此外,还有Phi3模型中文资料仓库的链接,和性能超越了8b版本的Llama3。2. 部...

阅读 11113·2025-12-17 13:33
阅读 12051·2025-12-16 16:27
阅读 3480·2025-05-12 19:38
阅读 4321·2025-04-29 17:46
阅读 14979·2025-03-21 11:44
阅读 2236·2025-02-19 18:27
阅读 2160·2025-02-19 18:21
阅读 2241·2025-02-19 13:50

