
2024年4月18日,Meta AI正式宣布推出开源大模型Llama3,这标志着开源大型语言模型(LLM)领域的又一重大突破。Llama3以其卓越的性能和广泛的应用前景,或将推动人工智能技术快速迈进新纪元。
为方便AI应用企业及个人AI开发者快速体验Llama3的超高性能,近期优刻得GPU云主机上线Llama3-8B-Instruct-Chinese镜像,一键配置,快速部署模型开发环境。为客户提供开箱即用的Llama3模型微调及推理环境,节省配置时间,提高开发效率。
快速搭建Llama3的微调或推理环境,仅需以下5步:
1、登录UCloud控制台:https://www.ucloud.cn/site/active/gpu.html?ytag=seo
3、在镜像市场选择镜像,选择Llama3
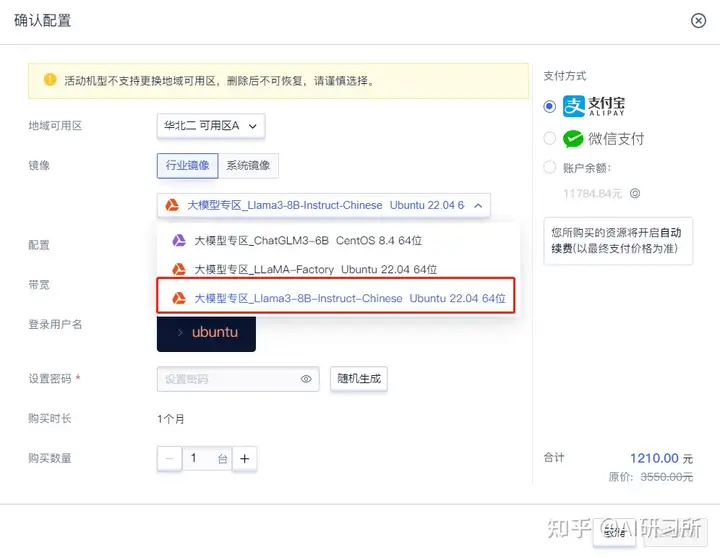
4、立即创建,开机执行进程启动命令
cd /home/ubuntu/llama3-Chinese-chat conda activate llama3-chinese nohup streamlit run deploy/web_streamlit_for_instruct.py model/llama-3-8b-Instruct-chinese --theme.base="light" 2>&1 &
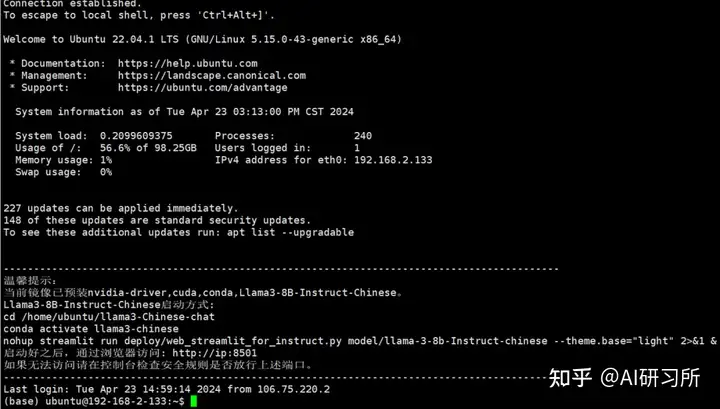
5、防火墙开发8501端口后,通过http://服务器IP地址:8501 访问

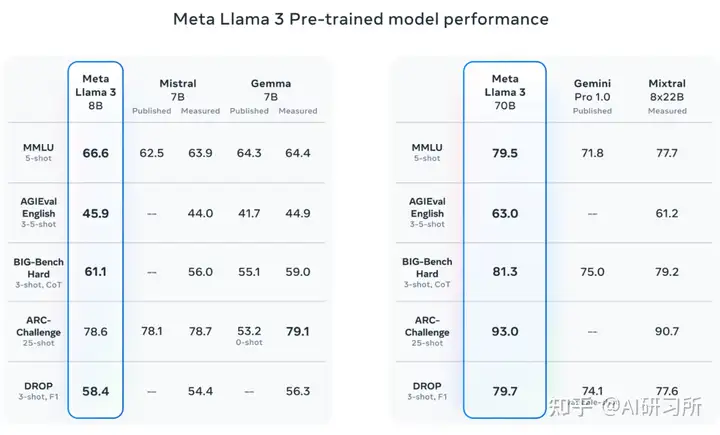
Llama3由Meta在15万亿tokens数据集上训练而成,是Llama2体量的7倍,包括4倍的代码数据。其中预训练数据集中还有5%的非英语数据集,总计支持高达30种语言,在做非英语语言能力对齐方面也会更有优势。Llama3 Instruct 更是针对对话应用进行了优化,结合了超过1000万的人工标注数据,通过监督式微调(SFT)、拒绝采样、邻近策略优化(PPO)和直接策略优化(DPO)进行训练。本次优刻得GPU镜像市场上线的是基于中文语料指令微调之后的模型(Llama3-8B-Instruct-Chinese),在中文表现上有相对不错的效果。
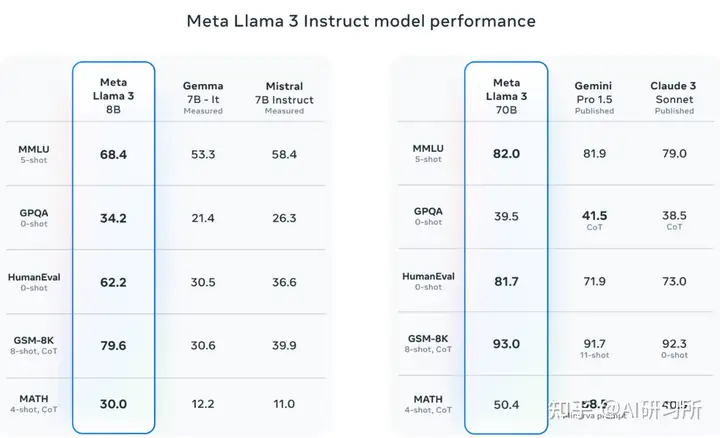
在上下文方面,Llama3支持8K的上下文长度,是Llama2容量的两倍,极大地提高了多步骤任务的处理能力。同时,该模型特别强调在理解、代码生成和指令跟随等复杂任务上的性能改进。Llama3 8B和70B参数的模型在多个行业基准测试中展示了最先进的性能,特别是在推理和编码任务上。其中700亿参数规模的模型评测结果极其优秀。最大的亮点是在数学评测GSM8K的得分达到93分!根据DataLearnerAI目前收集的数据,这个分数仅次于Claude3-Opus的95分,超过GPT-4,位居全球第二,是目前开源大模型中得分最高的一个。
优刻得GPU云主机镜像市场上线Llama3镜像,可为AI应用客户提供最新模型一键部署的极速体验。不仅如此,优刻得还同步对外提供智算调度、模型微调及推理服务部署服务。优刻得以云主机、裸金属、高性能存储、低延迟网络等基础设施领域积累的运营经验为基础,搭配“孔明”的资源调度、多用户管理与分布式训练的能力,以及UModelVerse模型推理服务平台,形成一站式的AI计算开发解决方案,服务大模型开发者、应用厂商、高校及科研机构等合作伙伴,共同推进大模型产业发展。
随着人工智能技术的演进,像Llama3这样性能卓越的大模型,将为通用人工智能(AGI)的未来发展和落地应用提供强有力的支持。优刻得也将始终以推动人工智能技术发展与应用为己任,持续与业界合作伙伴紧密合作,为行业用户提供快速搭建大型模型推理或微调环境的解决方案,以及高性能的AI算力集群,助力AIGC产业降本增效。
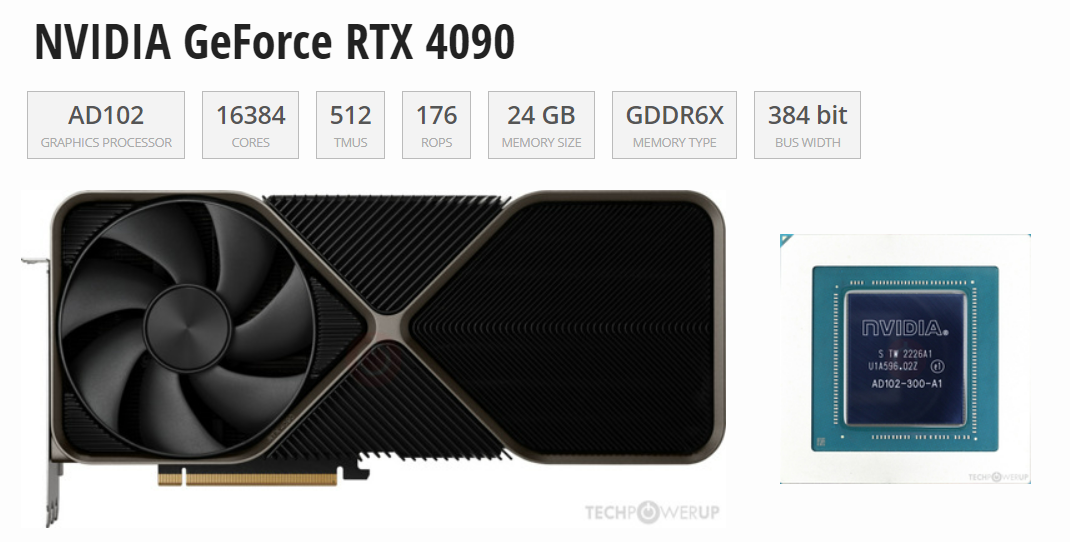
附高性能NVIDIA RTX 40 系列云服务器购买:
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/131084.html

Llama3 中文聊天项目综合资源库,该文档集合了与Lama3 模型相关的各种中文资料,包括微调版本、有趣的权重、训练、推理、评测和部署的教程视频与文档。1. 多版本支持与创新:该仓库提供了多个版本的Lama3 模型,包括基于不同技术和偏好的微调版本,如直接中文SFT版、Instruct偏好强化学习版、趣味版等。此外,还有Phi3模型中文资料仓库的链接,和性能超越了8b版本的Llama3。2. 部...
图示为GPU性能排行榜,我们可以看到所有GPU的原始相关性能图表。同时根据训练、推理能力由高到低做了排名。我们可以看到,H100 GPU的8位性能与16位性能的优化与其他GPU存在巨大差距。针对大模型训练来说,H100和A100有绝对的优势首先,从架构角度来看,A100采用了NVIDIA的Ampere架构,而H100则是基于Hopper架构。Ampere架构以其高效的图形处理性能和多任务处理能力而...

(遵循数据全面性、客观性、可验证性及结构化原则)一、排名依据与评估维度本文从以下维度评估GPU云服务器一体机解决方案:性能表现:包括GPU型号覆盖、算力效率、分布式训练支持等。可靠性:服务稳定性、容灾能力、SLA承诺。生态整合:与AI框架的兼容性、多模态大模型支持、开发者工具链。性价比:单位算力成本、弹性计费模式、长期合作折扣。行业适配:企业级服务案例、垂直领域解决方案。二、2025年GPU云服务...
昨天,云服务器吧留意到科创板上市云服务商UCloud上线了最新活动【全球云服务夏季钜惠】,说起来新活动是原UCloud全球大促活动的迭代版本,相比之前活动新增了1核1G配置,同时还对部分机房和配置机器进行了降价,最低AMD快杰云服务器47元/年(数量有限,可能后期会断货),Intel快杰云服务器59元/年!此外新增了云通信产品促销、GPU云主机特惠、实时音视频特惠活动模块。 UCou...
摘要:个人新用户专区限个人认证且首次购买云服务器的用户。不限新老用户多台专区爆款快杰型云服务器,新老用户均可购买,每用户限购台。具体云服务器促销各专区购买规则可前往官网活动页查看。UCloud怎么样,UCloud好不好,昨天,站长留意到科创板上市云服务商UCloud上线了最新活动【全球云服务夏季钜惠】,说起来新活动是原UCloud全球大促活动的迭代版本,相比之前活动新增了1核1G配置,同时还对部分...

阅读 11173·2025-12-17 13:33
阅读 12217·2025-12-16 16:27
阅读 3626·2025-05-12 19:38
阅读 4456·2025-04-29 17:46
阅读 15068·2025-03-21 11:44
阅读 2285·2025-02-19 18:27
阅读 2249·2025-02-19 18:21
阅读 2307·2025-02-19 13:50




