
当炒作出了「泼天的流量」,已经没人关心产品厉不厉害了。
近日,OpenAI 的秘密项目「Q*」引起了业内人士的广泛关注。上个月,代号为「草莓(Strawberry)」的项目曝光,据说它是「Q*」的延续,并可能具备高级推理能力。
而就在最近几天,关于这个项目,网络上又来了几波「鸽死人不偿命」的传播。尤其是一个「草莓哥」的账号,不间断地宣传,给人期望又让人失望。

网友们对Agent Q背后的技术充满了好奇。有人猜测,这背后可能有OpenAI的Q*项目加持。MultiOn公司不仅给Agent Q开设了独立的推特账号,而且账号的背景图片和基本信息都与草莓有关,这无疑增加了人们对其背后技术的好奇。
没想到,这个 Sam Altman 出现在哪里,它就在哪里跟帖的「营销号」,皮下竟然是个智能体?
当地时间8月14日,一家 AI 智能体初创公司「MultiOn」的创始人直接出来认领:虽然没等来 OpenAI 发布「Q*」,但我们发了操控「草莓哥」账号的全新智能体 Agent Q,快来和我们在线玩耍吧!
OpenAI 这一波营销操作让很多人都感到困惑,仿佛是在为自己铺路却又让人摸不着头脑。毕竟,最近不少人熬夜等待 OpenAI 的「大新闻」。事情的起因要追溯到 Sam Altman 与「草莓哥」的互动——在 Sam Altman 晒出的草莓照片下,他回复「草莓哥」说:惊喜马上就来。

不过,「MultiOn」的创始人 Div Garg 已悄悄删除了他认领 Agent Q 就是「草莓哥」的帖子。
这次,「MultiOn」宣布推出了突破性的 AI 智能体 Agent Q。该智能体的训练方法结合了蒙特卡洛树搜索(MCTS)和自我批评,并通过一种名为直接偏好优化(DPO)的算法学习人类反馈。
Agent Q 是什么
Agent Q是MultiOn公司联合斯坦福大学推出的自监督代理推理和搜索框架。Agent Q融合了引导式蒙特卡洛树搜索(MCTS)、AI自我批评和直接偏好优化(DPO)等技术,使A1模型能通过迭代微调和基于人类反馈的强化学习进行自我改进。Agent Q在网页导航和多步任务执行中展现出色性能,在OpenTable真实预订任务中,将成功率从18.6%提升至95.4%,标志着A在自主性和复杂决策能力上的重大突破。
作为具有规划和 AI 自我修复功能的下一代智能体,Agent Q 的性能是 LLaMA 3 基线零样本性能的 3.4 倍。在真实场景任务的评估中,Agent Q 的成功率高达 95.4%。
Agent Q结合了搜索、自我反思和强化学习,能够进行规划和自我修复。它通过引入一种新的学习和推理框架,解决了之前LLM训练技术的局限性,使其能够实现自主网页导航。
它能够为你预定某个时间某家餐厅的座位。

然后为你执行网页操作,比如查询空位情况。最终成功预定。

此外还能预定航班(比如本周六从纽约飞往旧金山,单程、靠窗和经济舱)。

在模拟网上商店的任务中,Agent Q展现了强大的搜索能力。而在Open Table的真实预订任务中,Agent Q更是将LLaMa-3的零样本成功率从18.6%提升至81.7%,分数提高比例达340%,而且仅经过了一天的自主数据收集。

不过,网友似乎对 Agent Q 并不买账。大家关心更多的还是他们是否真的借「草莓哥」账号炒作的事情,甚至有些人称他们为无耻的骗子。
重要组件和方法概览
目前,Agent Q 的相关论文已经放出,由 MultiOn 和斯坦福大学的研究者联合撰写。这项研究的成果将在今年晚些时候向开发人员和使用 MultiOn 的普通用户开放。

论文地址:
https://multion-research.s3.us-east-2.amazonaws.com/AgentQ.pdf
总结一下:Agent Q 能够自主地在网页上进行规划,并具备自我纠错的能力。它能够从成功和失败的经验中学习,不断提升在复杂任务中的表现。最终,这款智能体能够更好地规划如何在互联网上操作,以适应现实世界中的复杂情况。
从技术角度来看,Agent Q 的主要组件包括以下几点:
引导式蒙特卡洛树搜索(MCTS):Agent Q使用MCTS算法来指导代理在网页环境中的探索。通过模拟可能的行动路径,算法能够评估和选择最优的行动,从而平衡探索新信息和用已知信息。
AI自我批评:AgentQ在每个节点上生成可能的行动,并用基础的大型语言模型(LLM)对这些行动进行自我评估,提供中间的反馈作为中间奖励来指导搜索步骤。
直接偏好优化(DPO):一种离线强化学习方法,用于优化策略,使AgentQ能从成功的和不成功的轨迹中学习。DPO算法通过直接优化偏好对来微调模型,不依赖于传统的奖励信号。
策略迭代优化:Agent Q通过迭代微调,结合MCTS生成的数据和AI自我批评的反馈,构建偏好对,从而优化模型性能。

Agent Q的应用场景
电子商务:在模拟WebShop环境中,Agent Q可自动化浏览和购买流程,帮助用户快速找到所需商品并完成交易。
在线预订服务:Agent Q能在OpenTable等在线预订平台上为用户预订餐厅、酒店服务,处理所有相关的步骤。
软件开发:Agent Q可以辅助软件开发,从代码生成、测试到文档编写,提高开发效率并减少人为错误。
客户服务:作为智能客服代理,Agent Q能处理客户咨询,提供即时反馈,并解决常见问题。
数据分析:Agent Q能分析大量数据,为企业提供洞察和建议,帮助做出更加数据驱动的决策。
个性化推荐:AgentQ可以根据用户的历史行为和偏好,提供个性化的内容或产品推荐。
虽然Agent Q在评估实验中表现出色,但目前所用的方法仍存在许多讨论和改进的空间。例如,推理算法的设计、搜索策略的选择以及在线安全与交互等方面都需要进一步研究和优化。
Agent Q的出现无疑是AI智能体领域的一大进步,但它是否能够成为AI界的新贵,还是仅仅是一次高明的炒作,还有待时间的检验。无论如何,Agent Q的发布都为AI的发展带来了新的可能性和启示。
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/131152.html
摘要:近日,一篇在上成为了网友热议的话题。在这种结构改变几个月后,微软宣布注资亿美元。与微软的合作关系是基于一个重要的前提,即微软有权将的部分技术商业化。网友纷纷称早已应该更名为。 编译 | 禾木木 出品 | AI科技大本营(ID:rgznai100) OpenAI 如何以 10 亿美元的价...
摘要:摘要本文主要是讲解了机器学习中的增强学习方法的基本原理,常用算法及应用场景,最后给出了学习资源,对于初学者而言可以将其作为入门指南。下图表示了强化学习模型中涉及的基本思想和要素。 摘要: 本文主要是讲解了机器学习中的增强学习方法的基本原理,常用算法及应用场景,最后给出了学习资源,对于初学者而言可以将其作为入门指南。 强化学习(Reinforcement Learning)是当前最热门的...
摘要:月,卡耐基梅隆大学的程序在一对一不限注的扑克比赛中,击败了一组的德州扑克职业选手。概述击败人类冠军的三件事的深蓝,由卡内基梅隆大学开饭,在年的复赛中击败国际象棋世界冠军卡斯帕罗夫。年,奥克兰大学发布。 2017年是AI在扑克上取得突破的一年,在AI的发展历史上,具有里程碑的意义。1月,卡耐基梅隆大学的 AI 程序在一对一不限注的扑克比赛中,击败了一组的德州扑克职业选手。出乎所有人的意外,这一...
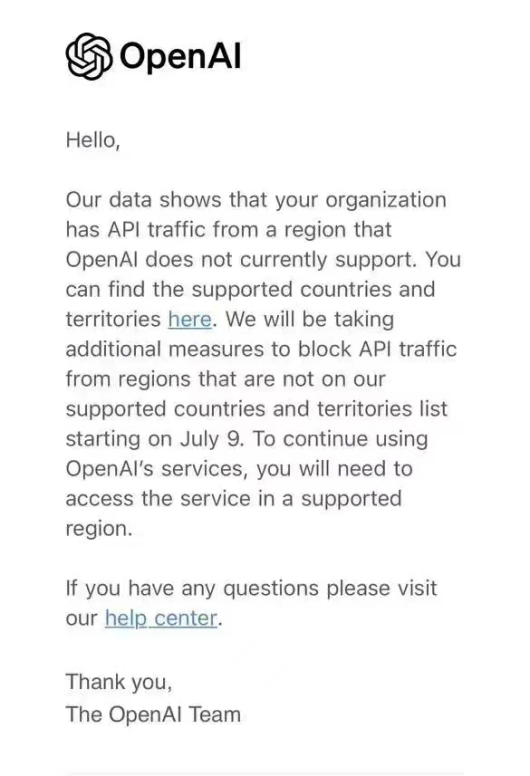
6月25日凌晨,陆续有包括中国大陆在内的各国和相关地区API开发者在社交媒体上表示,他们收到了来自一封来自OpenAI的警告信。其内容是:我们的数据显示,贵组织的 APl 流量来自OpenAl目前不支持的地区。您可以在此处找到受支持的国家和地区。我们将从7月9日开始采取额外措施,阻止来自不在我们支持的国家和地区列表中的地区的 APl 流量。要继续使用OpenAl的服务,您需要在受支持的地区访问服务...

阅读 11149·2025-12-17 13:33
阅读 12135·2025-12-16 16:27
阅读 3592·2025-05-12 19:38
阅读 4427·2025-04-29 17:46
阅读 15047·2025-03-21 11:44
阅读 2265·2025-02-19 18:27
阅读 2217·2025-02-19 18:21
阅读 2286·2025-02-19 13:50





