
摘要:在运算集群架构中,先分解任务,分工处理再汇总结果这些服务器依据用途可分成节点和节点,负责分配任务,而负责执行任务,如负责分派任务的操作,角色就像是节点。架构服务器角色分工运算集群中的服务器依用途分成节点和节点。
Hadoop架构服务器角色分工
Hadoop运算集群中的服务器依用途分成Master节点和Worker节点。Master节点中安装了JobTracker、NameNode、TaskTracker和DataNode程序,但Worker节点只安装TaskTracker和DataNode。
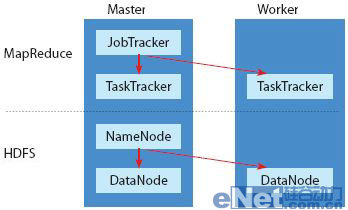
另外在系统的运行架构上,最简单的Hadoop架构,可以分成上层的MapReduce运算层以及下层的HDFS数据层。
在Master节点的服务器中会执行两套程序,一个是负责安排MapReduce运算层任务的JobTracker,以及负责管理HDFS数据层的NameNode程序。而在Worker节点的服务器中也有两套程序,接受JobTracker指挥,负责执行运算层任务的是TaskTracker程序,而与NameNode对应的则是DataNode程序,负责执行数据读写动作,以及执行NameNode的副本策略。
在MapReduce运算层上,担任Master节点的服务器负责分配运算任务, Master节点上的JobTracker程序会将 Map和Reduce程序的执行工作,指派给Worker服务器上的TaskTracker程序,由TaskTracker负责执行Map和Reduce工作,并将运算结果回复给Master节点上的JobTracker。
在HDFS数据层上,NameNode负责管理和维护HDFS的名称空间、并且控制文件的任何读写操作,同时NameNode会将要处理的数据切割成一个个文件区块(Block),每个区块是64MB,例如1GB的数据就会切割成16个文件区块。NameNode还会决定每一份文件区块要建立几个副本,一般来说,一个文件区块总共会复制成3份,并且会分散储存到3个不同Worker服务器的DataNode程序中管理,只要其中任何一份文件区块遗失或损坏,NameNode会自动寻找位于其他DataNode上的副本来回复,维持3份的副本策略。
在一套Hadoop集群中,分配MapReduce任务的JobTracker只有1个,而TaskTracker可以有很多个。同样地,负责管理HDFS文件系统的NameNode也只有一个,和JobTracker同样位于Master节点中,而DataNode可以有很多个。
不过,Master节点中除了有JobTracker和NameNode以外,也会有TaskTracker和DataNode程序,也就是说Master节点的服务器,也可以在本地端扮演Worker角色的工作。
在部署上,因为Hadoop采用Java开发,所以Master服务器除了安装操作系统如Linux之外,还要安装Java运行环境,然后再安装Master需要的程序,包括了NameNode、JobTracker和DataNode与TaskTracker。而在Worker服务器上,则只需安装Linux、Java环境、DataNode和TaskTracker。
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/3751.html
摘要:框架成为当今大数据处理背后的最具影响力的发动机。机器学习各类组织需求的不同导致相关的数据形形色色,对这些数据的分析也需要多样化的方法。提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。 Hadoop带来了廉价的处理大数据(大数据的数据容量通常是10-100GB或更多,同时数据种类多种多样,包括结构化、非结构化等)的能力。但这与之前有什么不同?现今企业...
摘要:为了履行这一承诺,优步依赖于在每个层面做出数据驱动的决策。完整性和延迟之间的权衡在计算时,随着我们在流式处理增量处理和批处理之间变换,我们面临着相同的根本权衡。 优步的任务是提供对每个人来说,在任何地方都可以获得像自来水一样可靠的出行服务。为了履行这一承诺,优步依赖于在每个层面做出数据驱动的决策。大部分的决策都得益于更快的数据处理。例如,使用数据来理解一个地区以便于增加业务,或城市运营团队对...
摘要:,腾讯分布式数据仓库基于开源软件和进行构建,打破了传统数据仓库不能线性扩展可控性差的局限,并且根据腾讯数据量大计算复杂等特定情况进行了大量优化和改造。经过四年多的持续投入和建设,已经成为腾讯较大的离线数据处理平台。 TDW(Tencent distributed Data Warehouse,腾讯分布式数据仓库)基于开源软件Hadoop和Hive进行构建,打破了传统数据仓库不能线性扩展、可控...
摘要:因此数据中台必须具备智能化能力,能够为业务提供一定的智能数据分析能力。宜信作为一家金融科技公司,更多面对的是金融领域的智能业务需求。 showImg(https://segmentfault.com/img/bVbqQM0?w=1155&h=492); 内容来源:宜信技术学院第1期技术沙龙-线上直播|AI中台:一种敏捷的智能业务支持方案 主讲人介绍:井玉欣 宜信技术研发中心AI应用团队...
摘要:大数据或者说的上升不会带来数据仓库或数据库市场的下降。事实上,随着大数据时代的到来,越来越多的传统数据仓库选择了与进行合作来满足用户的数据分析需求。 大数据热引发了人们对Hadoop的极大兴趣,同时也引来一些误解,认为既然Hadoop能帮助解决数据的处理和分析问题,它就可以替代传统的数据仓库。 数据仓库(数据库)与Hadoop(MapReduce)其实是两类有着很大区别的...

阅读 3221·2021-11-15 11:38
阅读 2643·2021-11-11 16:54
阅读 3971·2021-09-30 09:46
阅读 1493·2019-08-30 13:04
阅读 2068·2019-08-30 12:59
阅读 1670·2019-08-29 18:34
阅读 1738·2019-08-29 17:31
阅读 1115·2019-08-29 15:42

















