
摘要:中有一个微软团队的分享。微软有一套服务化的数据管道,作为云产品售卖。结尾微软用主要目的还是为了更容易使用流计算等开源软件,从安全性使用上而言,在收集端消费端监控等仍有非常多的点需要提高。
Kafka Summit 2016中有一个微软MS/Bing团队的分享。看了数据给大家分析下。微软有一套服务化的数据管道EventHub,作为云产品售卖。但在Bing、Ads、Office等场景上仍在使用Kafka,在整个公司规模上大概是一半 vs 一半。主要使用Kafka考虑是Kafka与开源流处理系统结合得更好(spark、Storm等)。
一些数据
先来看一些基础的数据:

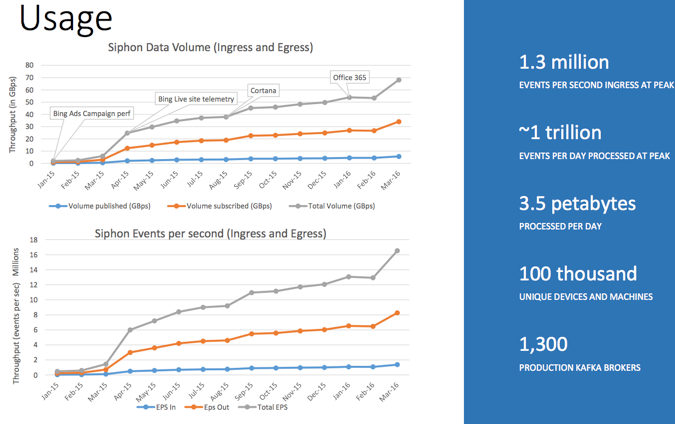
一天500GB,如果协议中带了压缩,一天的数据量为2.5 PB左右,并不是非常大。
大约1300台机器,每台机器处理384GB 数据。平均每台机器4MB/S写入流量,峰值约为6-7MB/S。说明效率并不是很高。3份拷贝计算,写入流量平均每台机器峰值20MB左右。
Incoming vs outcoming大约是1:3左右,说明数据有3-4个消费者。
1.3 Million/S 输入,一天500TB,一个包大小为4.4KB。
从一年的变化量上来看,增长还是挺快的,说明微软从15年1月份开始投入开源的拥抱。
架构
微软在Kafka上包了Collector收集器,和消费API,类似LogHub Client Lib (Consumer Group)。
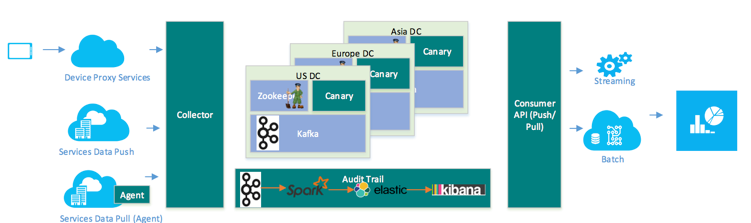
在消费端做除了拖以外、还提供了推的模式。类似AWS Kinesis Firehose,LogHub 的Shipper。目标是Kafka 另外Topic,COSMOS(数仓)以及Hadooop。

数据
做了一层Restful API
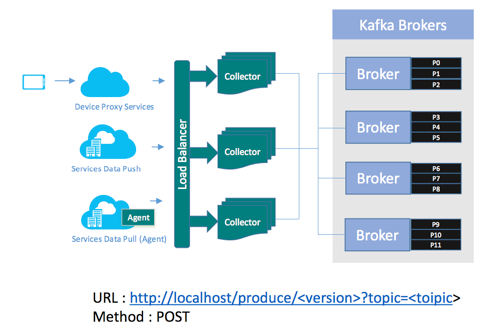
为了能够使得数据有语义,没有采用Confluent的Schema Center,而是采用了在数据上加了一个Header,通过自描述语义构建了包的类型和版本等。

为了能够支持微软的编程习惯,做了一套Kafka C# SDK,还是蛮拼的
Storm with C# - SCP.NET (http://www.nuget.org/packages/Microsoft.SCP.Net.SDK/)
Spark with C# - Mobius (https://github.com/Microsoft/Mobius)
Kafka with C# - C# Client for Kafka (https://github.com/Microsoft/Kafkanet)
BOND (https://github.com/Microsoft/bond)
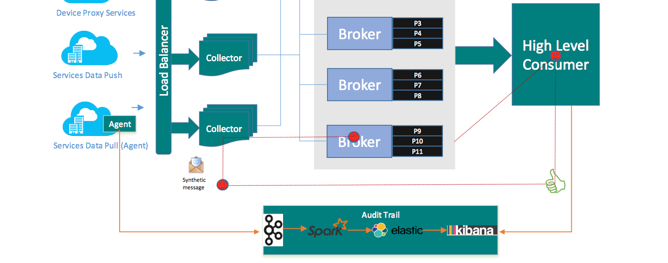
监控
在监控E2E消费时,用了一个挺重的方法来测量延时。既把数据到达时间,消费时间通过Spark Streaming做了Join,显示在ELK上。这个其实大可不必这样,只要能够知道ConsumerGroup 消费的CheckPoint是否是的,就能够知道了,何必大费周折。
结尾
微软用Kafka主要目的还是为了更容易使用流计算、ELK等开源软件,从安全性、使用上而言,Kafka在收集端、消费端、监控等仍有非常多的点需要提高。
欢迎加入本站公开兴趣群软件开发技术群
兴趣范围包括:Java,C/C++,Python,PHP,Ruby,shell等各种语言开发经验交流,各种框架使用,外包项目机会,学习、培训、跳槽等交流
QQ群:26931708
Hadoop源代码研究群
兴趣范围包括:Hadoop源代码解读,改进,优化,分布式系统场景定制,与Hadoop有关的各种开源项目,总之就是玩转Hadoop
QQ群:288410967
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4192.html
摘要:一些观念的修正从版本开始,的标语已经从一个高吞吐量,分布式的消息系统改为一个分布式流平台。不仅用在吞吐量高的大数据场景,也可以用在有事务要求的业务系统上,但性能较低。消息系统的作用削峰用于承接超出业务系统处理能力的请求,使业务平稳运行。 我们在《360度测试:KAFKA会丢数据么?其高可用是否满足需求?》这篇文章中,详细说明了KAFKA是否适合用在业务系统中。但有些朋友,还不知道KAF...
摘要:如果大家想了解更多关于的知识,那么就参加本月日,由和高可用共同举办的全球互联网架构大会吧和的成员和翟佳将出席深圳站,作为中间件专场讲师分享下一代分布式消息系统的话题。参加年深圳站,可以了解业界动态,和业界专家近距离接触。 showImg(https://segmentfault.com/img/bVbtW2z?w=750&h=199); 导读:在传统消息系统中,存在一些问题。一方面,消...

阅读 3215·2023-04-26 00:40
阅读 2540·2021-09-27 13:47
阅读 4698·2021-09-07 10:22
阅读 3094·2021-09-06 15:02
阅读 3424·2021-09-04 16:45
阅读 2673·2021-08-11 10:23
阅读 3720·2021-07-26 23:38
阅读 3014·2019-08-30 15:54



