
摘要:当和类似的服务诞生后,对于很多初创的互联网公司,简直是久旱逢甘霖,的持久性,和的可用性爽的不能再爽,于是纷纷把自个的存储架构布在了上。所以,当今早主要是宕机时,整个北美的互联网呈现一片哀魂遍野的景象。
事件回顾
美西太平洋时间早上 10 点(北京时间凌晨 2 点),AWS S3 开始出现异常。很多创业公司的技术人员发现他们的服务无法正常上传或者下载文件。有人在 hacker news 上问:Is S3 down? 然后迅速得到大伙的确认。
然而,AWS 自己的 status page (https://status.aws.amazon.com) 却后知后觉,放眼望去,一片让人喜滋滋的绿油油。就在大伙儿以为自己神经过敏,一切都是虚妄的猜测时,AWS 的工程师惊悚地发现,由于这个页面依赖于 S3,所以它实际上也挂了,于是赶紧放了个 banner 上去说明状况,然后在 twitter 上昭告天下绿油油是假象:
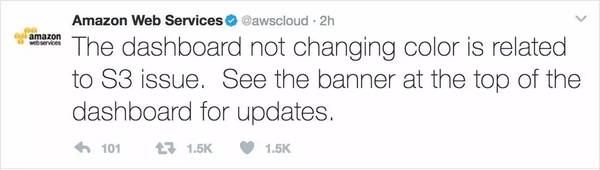
11:35am,经过一番努力,这个页面总算显示正常的状态了:

可以看到,重灾区是 North Virginia 的 S3。由于 S3 不工作,那些高度依赖 S3 的服务,比如 Elastic Map Reduce(需要 S3 存储中间过程和结果),以及去年 re:invent 刚发布的 Athena(查询的数据要放在 S3 上),也完全挂掉。依赖 S3 不那么重的服务,状态也不是太好。
S3 是 AWS 最早发布的云服务,simple storage service,解决存储的问题。存储是任何互联网服务的基石 —— 只要有大的数据对象,无论是图片,视频还是文本,我们都需要一个合适的存储方案保存它们。在没有云的日子里,这些内容要么存储在无比昂贵的 SAN (Storage Area Network) 中,要么存储在大量 PC 服务器的磁盘阵列中,通过一些特殊的文件系统,如 HDFS 来访问。为了维护这些数据的持久性和可用性,互联网公司需要在这样的基础设施上花费巨大的人力物力,无法集中所有的工程能力处理业务。当 S3 和类似 S3 的服务诞生后,对于很多初创的互联网公司,简直是久旱逢甘霖,99.99999% 的持久性(durability),和 99.9% 的可用性(availability)爽的不能再爽,于是纷纷把自个的存储架构布在了 S3 上。时至今日,使用 S3 的网站,已经多达 148, 213 个(数据来自 techrunch)。
所以,当今早 S3(主要是 North Virginia)宕机时,整个北美的互联网呈现一片哀魂遍野的景象。
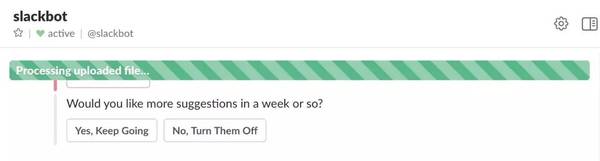
Slack 无法上传文件,进度条永远在走:
Trello 表示老子都被收购了,休息,休息一会也无妨:

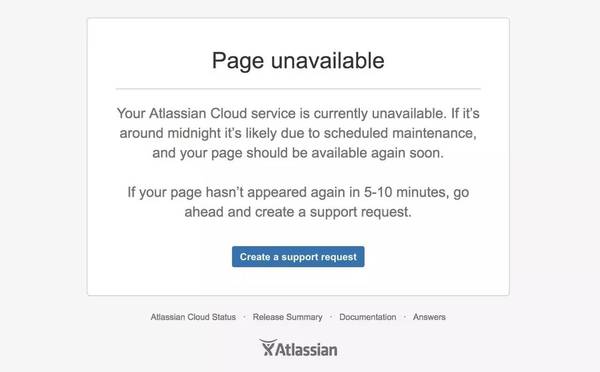
收购了 Trello 的 Atlassian 也不遑多让,文案好一本正经扑克脸(我都怀疑他们的工程师发现问题了么):
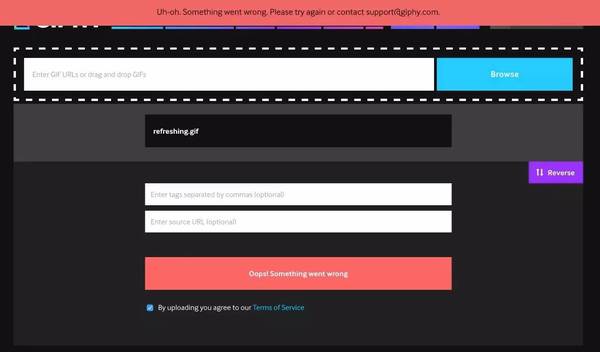
最近 VC 的宠儿 giffy,表面上一切正常(CDN 扛起了 gif 的下载),但如果你要上传 gif,对不起,偶们也不知道发生了神马事情:
至于高冷的 quora,干脆连个暖心的页面都不给,直接说,老子不玩了:
。。。
照理来说像 quora 这样的服务,面向用户阅读的部分本不该高度依赖 S3,要挂也不该全站挂,顶多是挂用户撰写答案的部分,不知道为何死的这么彻底。
我们看看当问题出现时,一个普通的 S3 GET 返回什么:
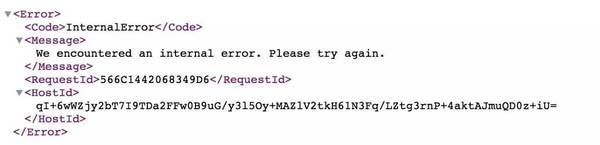
AWS 赤果果地告诉你,Internal Error 了。从 error handling 的角度,我们在写代码的时候都应该捕捉这个异常,然后做合适的错误处理。很遗憾的是,S3 这样的服务是如此基础,就像互联网的水和电一样,大家默认为它永远不会出错。因此,好多工程师干脆不做错误处理,像 slack 那样,任由进度条一直傻乎乎地跑;或者,让错误一路冒泡,直到把整个服务挂掉了事,像 quora / trello 那样。这样对用户都不太友好。
Murphy 定律告诉我们,凡事可能发生,就将要发生。所以比较好的处理方法是,捕捉到异常,让错误只局限在特定的页面,如:atlassian / giffy。或者,有个 plan B 应对突发事件。
使用 S3 的用户如何自救?
类似的事情发生在任何公司上都是不幸的,尤其是给客户以 SLA 保障的 SAAS 公司。大家能做得就是:
当云服务商的宕机发生时,尽量控制它影响面。像 trello 这样连 landing page 都一并挂掉实在不可取,起码 S3 影响不到的页面,如 landing page,用户注册 / 登录页面,应该还保持正常服务;而像 quora 这样的服务,其实是可以准备一个静态化的镜像,一旦出问题,起码让读者可以无障碍地阅读。
尽可能地把动态内容缓存起来,甚至静态化。Redis cache,nginx cache,HA proxy,CDN 都是把内容缓存甚至静态化的一些手段。尽管多级缓存维护起来是个麻烦,但当底层服务出现问题时,它们就是难得的战略缓冲区。cache 为你争取到的半个小时到几个小时几乎是续命的灵芝,它能帮你撑过最艰难的时刻(这次 S3 宕机前后大概 4 小时,最严重的时候是 11点到1点),相对从容地寻找解决方案,紧急发布新的页面,或者迁移服务,把损失降到较低。否则,只能像这次事件中的诸多公司一样,听天由命,双手合十祈祷 aws 的工程师给力些解决问题。
使用 simian army 在平日里操练系统的容错性。这个适合大一些的,工程团队有余力的公司。netflix 重度使用 aws,却在历次 aws 的宕机中毫发无损,是因为他们之前也深深地被云的「不稳定性」刺痛过。他们的 chaos monkey(之后发展为 simian army)服务,会随时随地模拟各种宕机情况,扰乱生产环境。比如说对于此次事件的演练,你可以配置 simian army 去扰乱 S3:simianarmy.chaos.fails3.enabled = true。这样,这群讨厌的猴子就会在你不知情的情况下随机把你的服务器的 /etc/hosts 改掉,让所有的 S3 API 不可用。这样你就可以体验平时很难遇到的 S3 不可访问的场景,进而找到相应的对策(注意:请在 staging 环境下谨慎尝试,否则老板把你开了不要赖程序君)。
如果 AWS 真的发生大规模宕机,而你又没有采取任何措施,天也不一定就塌下来了。此时此刻,你的投资人,你的客户,你的合作伙伴也许都忙着解决他们各自的宕机问题呢,hacker news 上(https://news.ycombinator.com/item?id=13755673)有个笑话这么说:
Why do we host on AWS?
Because if it goes down then our customers are so busy worried about themselves being down that they don"t even notice that we"re down!
看,这就是 CIO / CTO 们的狡黠之处(自建的出了问题都得自己擦屁股)。
如何利用这样的宕机机会?
Google 的工程师忙不迭地过来补刀加教育用户:

你看,这个社会就是这么群狼环饲。你别说不努力了,你努力着,但只要摔上一跤,就有猛兽过来蹭肉吃。对于甲方来说,狼越多选择越多,开心都来不及;作为乙方,则欲哭无泪。这次事故,我们作为乙方,看看热闹。但要知道,每家公司,甚至每个人,都在不同的上下文中扮演不同的角色,一会是甲方,一会是乙方。看热闹娃哈哈时,不要忘了有一天自己也可能遇到相同的境地,被自己的客户放在火上烤。
什么?你问 Tubi TV 宕没宕机?虽然我们有我们操蛋的烦恼,但是托 CDN 的福,在过去的几个小时,我们好好的。
欢迎加入本站公开兴趣群软件开发技术群
兴趣范围包括:Java,C/C++,Python,PHP,Ruby,shell等各种语言开发经验交流,各种框架使用,外包项目机会,学习、培训、跳槽等交流
QQ群:26931708
Hadoop源代码研究群
兴趣范围包括:Hadoop源代码解读,改进,优化,分布式系统场景定制,与Hadoop有关的各种开源项目,总之就是玩转Hadoop
QQ群:288410967
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4200.html
摘要:最近在学习各大互联网公司是如何处理数据一致性的。目前已知的有这么几种数据库做到情况下的强一致性淘宝淘宝顶级科学家阳振坤微博号阿里正祥,发出一则消息。然后因为数据库是的,内部把改动到了北美,君就可以看到消息了。 最近在学习各大互联网公司是如何处理数据一致性的。因为之前从事的不是这个方向的工作,所以并非什么经验之谈,只是一些学习笔记。所有资料来自互联网。 Consistent => Ev...
摘要:最近在学习各大互联网公司是如何处理数据一致性的。目前已知的有这么几种数据库做到情况下的强一致性淘宝淘宝顶级科学家阳振坤微博号阿里正祥,发出一则消息。然后因为数据库是的,内部把改动到了北美,君就可以看到消息了。 最近在学习各大互联网公司是如何处理数据一致性的。因为之前从事的不是这个方向的工作,所以并非什么经验之谈,只是一些学习笔记。所有资料来自互联网。 Consistent => Ev...
摘要:打错一个字母瘫痪半个互联网是怎样的感受在今天亚马逊披露了这起事故背后的原因后,很多人心里都会有一个疑问这个倒霉的程序员会被开除吗关于这一点,虽然主页君肯定没法做出准确的判断,但还是愿意给出我们的猜测不会。 2月28号,号称「亚马逊AWS最稳定」的云存储服务S3出现超高错误率的宕机事件。接着,半个互联网都跟着瘫痪了。一个字母造成的血案AWS 最近给出了确切的解释:一名程序员在调试系统的时候,运...

阅读 4178·2021-09-22 10:02
阅读 3455·2019-08-30 15:52
阅读 3141·2019-08-30 12:51
阅读 846·2019-08-30 11:08
阅读 2154·2019-08-29 15:18
阅读 3187·2019-08-29 12:13
阅读 3710·2019-08-29 11:29
阅读 1979·2019-08-29 11:13




