
摘要:接上文深度学习和的联合综述上卷积神经网络卷积神经网络被设计用来处理到多维数组数据的,比如一个有个包含了像素值图像组合成的一个具有个颜色通道的彩色图像。近年来,卷积神经网络的一个重大成功应用是人脸识别。
三大牛Yann LeCun、Yoshua Bengio和Geoffrey Hinton在深度学习领域的地位无人不知。为纪念人工智能提出60周年,的《Nature》杂志专门开辟了一个“人工智能 + 机器人”专题 ,发表多篇相关论文,其中包括了Yann LeCun、Yoshua Bengio和Geoffrey Hinton首次合作的这篇综述文章“Deep Learning”。本文为该综述文章中文译文的下半部分,详细介绍了CNN、分布式特征表示、RNN及其不同的应用,并对深度学习技术的未来发展进行了展望。
接上文:深度学习-LeCun、Bengio和Hinton的联合综述(上)
卷积神经网络
卷积神经网络被设计用来处理到多维数组数据的,比如一个有3个包含了像素值2-D图像组合成的一个具有3个颜色通道的彩色图像。很多数据形态都是这种多维数组的:1D用来表示信号和序列包括语言,2D用来表示图像或者声音,3D用来表示视频或者有声音的图像。卷积神经网络使用4个关键的想法来利用自然信号的属性:局部连接、权值共享、池化以及多网络层的使用。
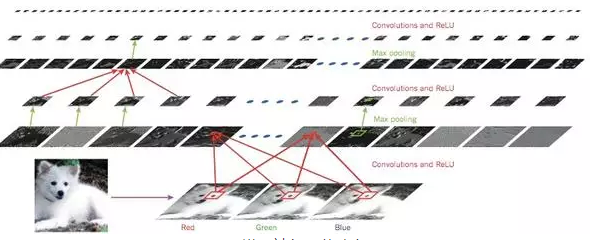
图2 卷积神经网络内部
一个典型的卷积神经网络结构(如图2)是由一系列的过程组成的。最初的几个阶段是由卷积层和池化层组成,卷积层的单元被组织在特征图中,在特征图中,每一个单元通过一组叫做滤波器的权值被连接到上一层的特征图的一个局部块,然后这个局部加权和被传给一个非线性函数,比如ReLU。在一个特征图中的全部单元享用相同的过滤器,不同层的特征图使用不同的过滤器。使用这种结构处于两方面的原因。首先,在数组数据中,比如图像数据,一个值的附近的值经常是高度相关的,可以形成比较容易被探测到的有区分性的局部特征。其次,不同位置局部统计特征不太相关的,也就是说,在一个地方出现的某个特征,也可能出现在别的地方,所以不同位置的单元可以共享权值以及可以探测相同的样本。在数学上,这种由一个特征图执行的过滤操作是一个离线的卷积,卷积神经网络也是这么得名来的。
卷积层的作用是探测上一层特征的局部连接,然而池化层的作用是在语义上把相似的特征合并起来,这是因为形成一个主题的特征的相对位置不太一样。一般地,池化单元计算特征图中的一个局部块的较大值,相邻的池化单元通过移动一行或者一列来从小块上读取数据,因为这样做就减少的表达的维度以及对数据的平移不变性。两三个这种的卷积、非线性变换以及池化被串起来,后面再加上一个更多卷积和全连接层。在卷积神经网络上进行反向传播算法和在一般的深度网络上是一样的,可以让所有的在过滤器中的权值得到训练。
深度神经网络利用的很多自然信号是层级组成的属性,在这种属性中高级的特征是通过对低级特征的组合来实现的。在图像中,局部边缘的组合形成基本图案,这些图案形成物体的局部,然后再形成物体。这种层级结构也存在于语音数据以及文本数据中,如电话中的声音,因素,音节,文档中的单词和句子。当输入数据在前一层中的位置有变化的时候,池化操作让这些特征表示对这些变化具有鲁棒性。
卷积神经网络中的卷积和池化层灵感直接来源于视觉神经科学中的简单细胞和复杂细胞。这种细胞的是以LNG-V1-V2-V4-IT这种层级结构形成视觉回路的。当给一个卷积神经网络和猴子一副相同的图片的时候,卷积神经网络展示了猴子下颞叶皮质中随机160个神经元的变化。卷积神经网络有神经认知的根源,他们的架构有点相似,但是在神经认知中是没有类似反向传播算法这种端到端的监督学习算法的。一个比较原始的1D卷积神经网络被称为时延神经网络,可以被用来识别语音以及简单的单词。
20世纪90年代以来,基于卷积神经网络出现了大量的应用。最开始是用时延神经网络来做语音识别以及文档阅读。这个文档阅读系统使用一个被训练好的卷积神经网络和一个概率模型,这个概率模型实现了语言方面的一些约束。20世纪90年代末,这个系统被用来美国超过10%的支票阅读上。后来,微软开发了基于卷积神经网络的字符识别系统以及手写体识别系统。20世纪90年代早期,卷积神经网络也被用来自然图形中的物体识别,比如脸、手以及人脸识别(face recognition )。
使用深度卷积网络进行图像理解
21世纪开始,卷积神经网络就被成功的大量用于检测、分割、物体识别以及图像的各个领域。这些应用都是使用了大量的有标签的数据,比如交通信号识别,生物信息分割,面部探测,文本、行人以及自然图形中的人的身体部分的探测。近年来,卷积神经网络的一个重大成功应用是人脸识别。
值得一提的是,图像可以在像素级别进行打标签,这样就可以应用在比如自动电话接听机器人、自动驾驶汽车等技术中。像Mobileye以及NVIDIA公司正在把基于卷积神经网络的方法用于汽车中的视觉系统中。其它的应用涉及到自然语言的理解以及语音识别中。

图3 从图像到文字
尽管卷积神经网络应用的很成功,但是它被计算机视觉以及机器学习团队开始重视是在2012年的ImageNet竞赛。在该竞赛中,深度卷积神经网络被用在上百万张网络图片数据集,这个数据集包含了1000个不同的类。该结果达到了前所未有的好,几乎比当时较好的方法降低了一半的错误率。这个成功来自有效地利用了GPU、ReLU、一个新的被称为dropout的正则技术,以及通过分解现有样本产生更多训练样本的技术。这个成功给计算机视觉带来一个革命。如今,卷积神经网络用于几乎全部的识别和探测任务中。最近一个更好的成果是,利用卷积神经网络结合回馈神经网络用来产生图像标题。
如今的卷积神经网络架构有10-20层采用ReLU激活函数、上百万个权值以及几十亿个连接。然而训练如此大的网络两年前就只需要几周了,现在硬件、软件以及算法并行的进步,又把训练时间压缩到了几小时。
基于卷积神经网络的视觉系统的性能已经引起了大型技术公司的注意,比如Google、Facebook、Microsoft、IBM,yahoo!、Twitter和Adobe等,一些快速增长的创业公司也同样如是。
卷积神经网络很容易在芯片或者现场可编程门阵列(FPGA)中高效实现,许多公司比如NVIDIA、Mobileye、Intel、Qualcomm以及Samsung,正在开发卷积神经网络芯片,以使智能机、相机、机器人以及自动驾驶汽车中的实时视觉系统成为可能。
分布式特征表示与语言处理
与不使用分布式特征表示(distributed representations )的经典学习算法相比,深度学习理论表明深度网络具有两个不同的巨大的优势。这些优势来源于网络中各节点的权值,并取决于具有合理结构的底层生成数据的分布。首先,学习分布式特征表示能够泛化适应新学习到的特征值的组合(比如,n元特征就有2n种可能的组合)。其次,深度网络中组合表示层带来了另一个指数级的优势潜能(指数级的深度)。
多层神经网络中的隐层利用网络中输入的数据进行特征学习,使之更加容易预测目标输出。下面是一个很好的示范例子,比如将本地文本的内容作为输入,训练多层神经网络来预测句子中下一个单词。内容中的每个单词表示为网络中的N分之一的向量,也就是说,每个组成部分中有一个值为1其余的全为0。在第一层中,每个单词创建不同的激活状态,或单词向量(如图4)。在语言模型中,网络中其余层学习并转化输入的单词向量为输出单词向量来预测句子中下一个单词,可以通过预测词汇表中的单词作为文本句子中下一个单词出现的概率。网络学习了包含许多激活节点的、并且可以解释为词的独立特征的单词向量,正如第一次示范的文本学习分层表征文字符号的例子。这些语义特征在输入中并没有明确的表征。而是在利用“微规则”(‘micro-rules’,本文中直译为:微规则)学习过程中被发掘,并作为一个分解输入与输出符号之间关系结构的好的方式。当句子是来自大量的真实文本并且个别的微规则不可靠的情况下,学习单词向量也一样能表现得很好。利用训练好的模型预测新的事例时,一些概念比较相似的词容易混淆,比如星期二(Tuesday)和星期三(Wednesday),瑞典(Sweden)和挪威(Norway)。这样的表示方式被称为分布式特征表示,因为他们的元素之间并不互相排斥,并且他们的构造信息对应于观测到的数据的变化。这些单词向量是通过学习得到的特征构造的,这些特征不是由专家决定的,而是由神经网络自动发掘的。从文本中学习得单词向量表示现在广泛应用于自然语言中。
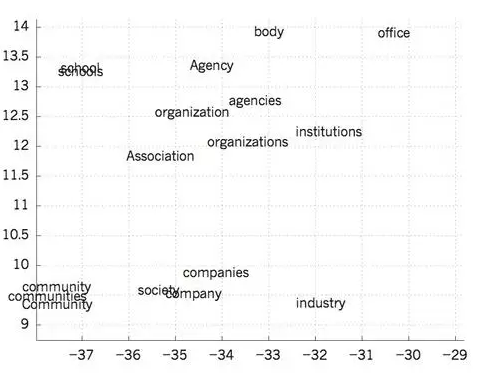

图4 可视化学习词向量
特征表示问题争论的中心介于对基于逻辑启发和基于神经网络的认识。在逻辑启发的范式中,一个符号实体表示某一事物,因为其的属性与其他符号实体相同或者不同。该符号实例没有内部结构,并且结构与使用是相关的,至于理解符号的语义,就必须与变化的推理规则合理对应。相反地,神经网络利用了大量活动载体、权值矩阵和标量非线性化,来实现能够支撑简单容易的、具有常识推理的快速“直觉”功能。
在介绍神经语言模型前,简述下标准方法,其是基于统计的语言模型,该模型没有使用分布式特征表示。而是基于统计简短符号序列出现的频率增长到N(N-grams,N元文法)。可能的N-grams的数字接近于VN,其中V是词汇表的大小,考虑到文本内容包含成千上万个单词,所以需要一个非常大的语料库。N-grams将每个单词看成一个原子单元,因此不能在语义相关的单词序列中一概而论,然而神经网络语言模型可以,是因为他们关联每个词与真是特征值的向量,并且在向量空间中语义相关的词彼此靠近(图4)。
递归神经网络
首次引入反向传播算法时,最令人兴奋的便是使用递归神经网络(recurrent neural networks,下文简称RNNs)训练。对于涉及到序列输入的任务,比如语音和语言,利用RNNs能获得更好的效果。RNNs一次处理一个输入序列元素,同时维护网络中隐式单元中隐式的包含过去时刻序列元素的历史信息的“状态向量”。如果是深度多层网络不同神经元的输出,我们就会考虑这种在不同离散时间步长的隐式单元的输出,这将会使我们更加清晰怎么利用反向传播来训练RNNs(如图5,右)。
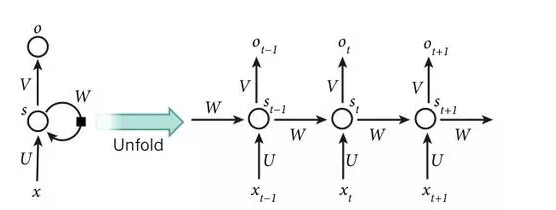
图5 递归神经网络
RNNs是非常强大的动态系统,但是训练它们被证实存在问题的,因为反向传播的梯度在每个时间间隔内是增长或下降的,所以经过一段时间后将导致结果的激增或者降为零。
由于先进的架构和训练方式,RNNs被发现可以很好的预测文本中下一个字符或者句子中下一个单词,并且可以应用于更加复杂的任务。例如在某时刻阅读英语句子中的单词后,将会训练一个英语的“编码器”网络,使得隐式单元的最终状态向量能够很好地表征句子所要表达的意思或思想。这种“思想向量”(thought vector)可以作为联合训练一个法语“编码器”网络的初始化隐式状态(或者额外的输入),其输出为法语翻译首单词的概率分布。如果从分布中选择一个特殊的首单词作为编码网络的输入,将会输出翻译的句子中第二个单词的概率分布,并直到停止选择为止。总体而言,这一过程是根据英语句子的概率分布而产生的法语词汇序列。这种简单的机器翻译方法的表现甚至可以和较先进的(state-of-the-art)的方法相媲美,同时也引起了人们对于理解句子是否需要像使用推理规则操作内部符号表示质疑。这与日常推理中同时涉及到根据合理结论类推的观点是匹配的。
类比于将法语句子的意思翻译成英语句子,同样可以学习将图片内容“翻译”为英语句子(如图3)。这种编码器是可以在最后的隐层将像素转换为活动向量的深度卷积网络(ConvNet)。解码器与RNNs用于机器翻译和神经网络语言模型的类似。近来,已经掀起了一股深度学习的巨大兴趣热潮(参见文献[86]提到的例子)。
RNNs一旦展开(如图5),可以将之视为一个所有层共享同样权值的深度前馈神经网络。虽然它们的目的是学习长期的依赖性,但理论的和经验的证据表明很难学习并长期保存信息。
为了解决这个问题,一个增大网络存储的想法随之产生。采用了特殊隐式单元的LSTM(long short-termmemory networks)被首先提出,其自然行为便是长期的保存输入。一种称作记忆细胞的特殊单元类似累加器和门控神经元:它在下一个时间步长将拥有一个权值并联接到自身,拷贝自身状态的真实值和累积的外部信号,但这种自联接是由另一个单元学习并决定何时清除记忆内容的乘法门控制的。
LSTM网络随后被证明比传统的RNNs更加有效,尤其当每一个时间步长内有若干层时,整个语音识别系统能够完全一致的将声学转录为字符序列。目前LSTM网络或者相关的门控单元同样用于编码和解码网络,并且在机器翻译中表现良好。
过去几年中,几位学者提出了不同的提案用于增强RNNs的记忆模块。提案中包括神经图灵机,其中通过加入RNNs可读可写的“类似磁带”的存储来增强网络,而记忆网络中的常规网络通过联想记忆来增强。记忆网络在标准的问答基准测试中表现良好,记忆是用来记住稍后要求回答问题的事例。
除了简单的记忆化,神经图灵机和记忆网络正在被用于那些通常需要推理和符号操作的任务,还可以教神经图灵机“算法”。除此以外,他们可以从未排序的输入符号序列(其中每个符号都有与其在列表中对应的表明优先级的真实值)中,学习输出一个排序的符号序列。可以训练记忆网络用来追踪一个设定与文字冒险游戏和故事的世界的状态,回答一些需要复杂推理的问题。在一个测试例子中,网络能够正确回答15句版的《指环王》中诸如“Frodo现在在哪?”的问题。
深度学习的未来展望
无监督学习对于重新点燃深度学习的热潮起到了促进的作用,但是纯粹的有监督学习的成功盖过了无监督学习。在本篇综述中虽然这不是我们的重点,我们还是期望无监督学习在长期内越来越重要。无监督学习在人类和动物的学习中占据主导地位:我们通过观察能够发现世界的内在结构,而不是被告知每一个客观事物的名称。
人类视觉是一个智能的、基于特定方式的利用小或大分辨率的视网膜中央窝与周围环绕区域对光线采集成像的活跃的过程。我们期望未来在机器视觉方面会有更多的进步,这些进步来自那些端对端的训练系统,并结合ConvNets和RNNs,采用增强学习来决定走向。结合了深度学习和增强学习的系统正处在初期,但已经在分类任务中超过了被动视频系统,并在学习操作视频游戏中产生了令人印象深刻的效果。
在未来几年,自然语言理解将是深度学习做出巨大影响的另一个领域。我们预测那些利用了RNNs的系统将会更好地理解句子或者整个文档,当它们选择性地学习了某时刻部分加入的策略。
最终,在人工智能方面取得的重大进步将来自那些结合了复杂推理表示学习(representation learning )的系统。尽管深度学习和简单推理已经应用于语音和手写字识别很长一段时间了,我们仍需要通过操作大量向量的新范式来代替基于规则的字符表达式操作。
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4312.html
摘要:三大牛和在深度学习领域的地位无人不知。逐渐地,这些应用使用一种叫深度学习的技术。监督学习机器学习中,不论是否是深层,最常见的形式是监督学习。 三大牛Yann LeCun、Yoshua Bengio和Geoffrey Hinton在深度学习领域的地位无人不知。为纪念人工智能提出60周年,的《Nature》杂志专门开辟了一个人工智能 + 机器人专题 ,发表多篇相关论文,其中包括了Yann LeC...
摘要:今年月日收购了基于深度学习的计算机视觉创业公司。这项基于深度学习的计算机视觉技术已经开发完成,正在测试。深度学习的误区及产品化浪潮百度首席科学家表示目前围绕存在着某种程度的夸大,它不单出现于媒体的字里行间,也存在于一些研究者之中。 在过去的三十年,深度学习运动一度被认为是学术界的一个异类,但是现在, Geoff Hinton(如图1)和他的深度学习同事,包括纽约大学Yann LeCun和蒙特...
摘要:毫无疑问,现在深度学习是主流。所以科技巨头们包括百度等纷纷通过收购深度学习领域的初创公司来招揽人才。这项基于深度学习的计算机视觉技术已经开发完成,正在测试。 在过去的三十年,深度学习运动一度被认为是学术界的一个异类,但是现在, Geoff Hinton(如图1)和他的深度学习同事,包括纽约大学Yann LeCun和蒙特利尔大学的Yoshua Bengio,在互联网世界受到前所未有的关注...
摘要:主流机器学习社区对神经网络兴趣寡然。对于深度学习的社区形成有着巨大的影响。然而,至少有两个不同的方法对此都很有效应用于卷积神经网络的简单梯度下降适用于信号和图像,以及近期的逐层非监督式学习之后的梯度下降。 我们终于来到简史的最后一部分。这一部分,我们会来到故事的尾声并一睹神经网络如何在上世纪九十年代末摆脱颓势并找回自己,也会看到自此以后它获得的惊人先进成果。「试问机器学习领域的任何一人,是什...
摘要:的研究兴趣涵盖大多数深度学习主题,特别是生成模型以及机器学习的安全和隐私。与以及教授一起造就了年始的深度学习复兴。目前他是仅存的几个仍然全身心投入在学术界的深度学习教授之一。 Andrej Karpathy特斯拉 AI 主管Andrej Karpathy 拥有斯坦福大学计算机视觉博士学位,读博期间师从现任 Google AI 首席科学家李飞飞,研究卷积神经网络在计算机视觉、自然语言处理上的应...

阅读 781·2021-11-18 10:02
阅读 2311·2021-11-15 18:13
阅读 3339·2021-11-15 11:38
阅读 3096·2021-09-22 15:55
阅读 3752·2021-08-09 13:43
阅读 2534·2021-07-25 14:19
阅读 2530·2019-08-30 14:15
阅读 3519·2019-08-30 14:15






