
摘要:自从年深秋,他开始在上撰写并公开分享他感兴趣的机器学习论文。本文选取了上篇阅读注释的机器学习论文笔记。希望知名专家注释的深度学习论文能使一些很复杂的概念更易于理解。主要讲述的是奥德赛因为激怒了海神波赛多而招致灾祸。
Hugo Larochelle博士是一名谢布克大学机器学习的教授,社交媒体研究科学家、知名的神经网络研究人员以及深度学习狂热爱好者。自从2015年深秋,他开始在arXiv上撰写并公开分享他感兴趣的机器学习论文。在这篇文章发布之前,他已经分享了10篇论文笔记。

本文选取了arXiv上5篇Hugo阅读注释的机器学习论文笔记。为使我们更好地理解这些内容,每篇论文介绍了摘要并附上了Hugo的笔记。希望知名专家注释的深度学习论文能使一些很复杂的概念更易于理解。
1.非回溯递归网络训练
Training recurrent networks online without backtracking
作者:Yann Ollivier、Guillaume Charpiat
arXiv上发布日期:2015年7月28日
摘要(摘录):我们引入「非回溯」算法来训练类似递归神经网络这样的动态系统的参数。这个算法在线上、无内存的条件下运行,因此不需要反向时间传播,有可拓展性,避免了保持当前状态参数的全向梯度所需要的大量的计算和内存成本。[…]先前在简单任务上的测试表明,相对于保持全向梯度,引入梯度随机近似算法后,似乎并没有给轨迹引入过多噪声,可以确认具有优良性能和保证在卡尔曼版本的非回溯算法上的可拓展性。
Hugo的注释(摘录):
RNN线上训练是一个宏大而未解决的问题。
人们现今使用的方法是把回溯截断为几个过去的步长,这更多是一种探索性的做法。
这篇论文在原则方法基础上更近了一步。我很欣赏方程式7的「秩一技巧」,很精致可爱!这也是这个方法的中心,把这些点联系到了一起,干得真好!
作者介绍这项工作只是初步的,他们确实并没有和截断回溯比较。我迫切希望他们在未来的工作中做下比较,并且,我不赞同『随机梯度下降理论在此处可以应用到』这个论点。
2.基于梯形网络的半监督学习
Semi-Supervised Learning with Ladder Network
作者:Antti Rasmus、Harri Valpola、Mikko Honkala、Mathias Berglund,、Tapani Raiko
arXiv上发布日期:2015年7月9日
摘要:在深度神经网络中,我们把监督学习和无监督学习结合到一起。我们首先训练提出的模型在使用反向传播后可以同时最小化监督和无监督消耗函数,从而省去了逐层预先训练步骤的必要。我们的工作建立在Valpola2015年提出的梯形网络基础上,我们把这个模型和监督结合起来进行了拓展。我们展示了拓展模型在各种任务中:半监督条件下MNIST和CIFAR-10分类,半监督和全标签条件下的定量MNIST的排列过程,都达到艺术级性能。
Hugo的注释(摘录):
我认为,性能是这篇论文最令人兴奋的。在MNIST上,仅仅通过100个标签样本,它达到1.13%的错误率。这与训练集上训练的堆叠去噪自编码的性能相媲美(尽管它出现在这篇文章使用的ReLUs和批标准化之前)!尽管应用到许多标签的数据集的深度学习进展并不依赖任何无监督学习(不像在2000-2010年中期深度学习刚开始时),这篇论文确认了深度学习中一个当前思路,即无监督学习可能对半监督条件下低标签数据的成功起着关键作用。
不幸的是,作者披露实验中存在一个很小的问题:虽然他们使用很少的标签样本来训练,在验证集中模型选择的确使用了1万个标签。这的确很不现实。
3.面向基于神经网络的分析
Towards Neural Network-based Reasoning
作者:Baolin Peng,、Zhengdong Lu、 Hang Li、Kam-Fai Wong
arXiv上发布日期:2015年8月22日
摘要(摘录):我们建议推出神经推理器,这是一个基于神经网络的推理自然语言的框架。只要给定一个问题,神经推理器能根据多种支持的事实进行推断并以特殊的方式找到答案。神经推理器具备:1)一个特别的互动池机制,允许它检验多重事实,2)一个深度架构,允许它在推理作业中模化复杂的逻辑关系。假定问题和事实并不存在特殊的结构,神经推断器能够容纳不同类型的推断和不同的语言表达形式。[…]经验研究表明,在两种不同人工作业上(定位和寻路),神经推断器能在很大程度上超越现有神经推断系统。
Hugo的注释(摘录):
在我看来,这篇论文最有趣的方面可能是证明通过使用一些从属任务,比如无监督的“起点”,可以显著提高在寻路任务上的表现。对我来说最令人兴奋的莫过于这篇论文中强调的,未来可能极其光明的研究方向。
我也欣赏文中模型展示的方式。理解模型并没有花费我太多的时间,实际上我发现他比记忆网络模型更易于消化,尽管这两个模型很相似。我认为这个模型确实比记忆模型更简单点,这很好。论文还提出这个问题的另一种解决办法,这个方法里不仅问题表征会随着正向传播更新,事实表征也会更新。
4.基于递归神经网络的定时采样序列预测
Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks
作者:Samy Bengio、Oriol Vinyals、Navdeep Jaitly、Noam Shazeer
arXiv上发布日期:2015年6月9日
摘要(摘录):我们可以训练周期神经网络,使它在给予一定输入时产生符号序列,正如机器翻译和图像识别的结果例证的一样。当前训练它们的方法包括,在给定当前(递归)状态和先前符号时,较大化每个符号序列的相似性,。在推导上,未知的先前符号被模型产生的符号代替。训练和推导的内容不符会产生误差,误差会随着产生的序列迅速累积。我们提出了一个课程学习策略,从一个完全引导的方案,柔和过度到不完全引导方案,前者完全使用正确的前符号,后者主要使用系统自己生成的符号。一些序列预测作业试验显示这个方法可带来很大改善。
Hugo的注释(摘录):
超爱这篇论文。它甄别到目前序列预测训练方法的一个重要缺点,最重要的是,同时提出了一个简单有效的解决方案。我也相信这个方法在谷歌图像识别生成赢家系统以及微软COCO竞赛中起着不可忽视的作用。
关于定时采样有助的原因,我的另一个理解是:ML训练并不会告知模型自己产生的误差的相对质量。就ML而言,把高概率放在一个仅有一个错误令牌的输出序列和把相同概率放在一个有全部错误令牌的序列上同样糟糕。然而就图像识别来说,输出仅有一个错字的语句明显比有许多错字的语句(某种也反映在性能矩阵的东西,比如BLEU)更为可取。
通过训练模型在面对自身错误的系统稳定性,定时采样可确保误差不会累积,并且(帮助系统)做出八九不离十的预测。
5.LSTM:一个空间搜索奥德赛
LSTM_ A Search Space Odyssey
作者:Klaus Treff、Rupesh Kumar Srivastava、Jan Koutník、Bas R. Steunebrink、 Jürgen Schmidhuber
arXiv上发布日期:2015年5月13日
译者按:奥德赛是古希腊史诗中重要一部。主要讲述的是奥德赛因为激怒了海神波赛多而招致灾祸。最后利用智慧历经重重磨难得以回家的故事。文中指富有伟大意义却艰辛的科学探索之旅。
摘要(摘录):本文在3个代表性任务测试:语音识别,手写字体识别和复调音乐建模上,首次大规模使用8LSTM变量分析。使用随机搜索,多带带优化每个作业的所有LSTM变量的超参数,并且使用强大的fANOVA结构评估它们的重要性。我们一共总结了5400次试验运行结果(CPU时间大概15年),这使我们的研究成为同类LSTM网络研究中规模较大的。我们的结果表明,在标准LSTM架构上没有一种变量能显著提高,并且可以证明忘记门和激励函数的输出结果是它最重要的部分。我们进一步观察到这些被研究的超参数是实质上是独立的,并在为它们的有效调整制定了指导方针。
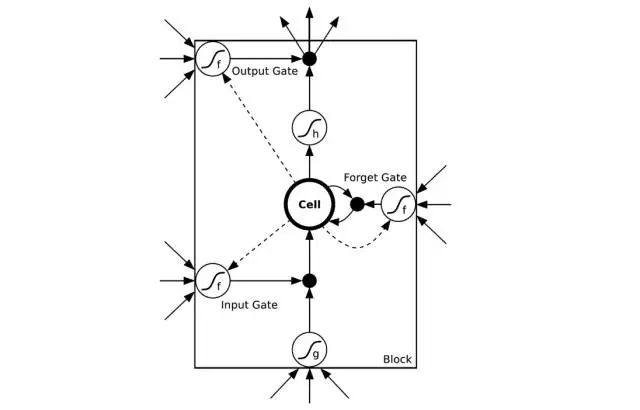
译者注:如图所示是一个LSTM简易版模型。其中input gate输入门/output gate输出门负责管理输入及输出数值。forget gate忘记门负责选择性删除一些系统以前记住的数值来确保可以更好记住近期数值。图片来自CSDN
Hugo的注释(摘录):
这是一篇很有用的(帮你)热身准备的文章。对任何想要学习LSTMs的人,我都会推荐这篇文章必读。首先,我发现它对LSTMs最初的发展史的描述很有趣并且很明了。但是,最重要的是,它展现了LSTMs一个很实用的图景,这不仅可以为初次使用LSTMs的奠定优良基础,还可以作为一个对LSTM每一部分重要性的很有见地的(数据支撑的)观点阐述。
基于fANONA的分析(目前我还不了解)很精炼。可能最让我震惊的发现是,势头的帮助实际上看起来并不大。研究超参数之间的二阶互动构思很巧妙(通过表明同时调整学习频率和隐藏层 可能并不重要,这很有见地)。图4中的描述陈列出学习频率/隐藏层大小/输入噪声变量和性能/训练时间之间可能存在的关系(带有不确定性)也是很有用的信息。
前向传播
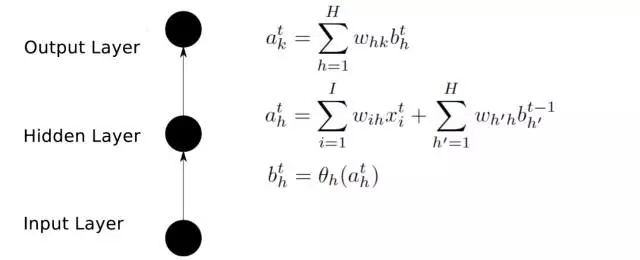
后向传播

译者注:
输入层(Input layer),众多神经元(Neuron)接受大量非线形输入信息。输入的信息称为输入向量。
输出层(Output layer),信息在神经元链接中传输、分析、权衡,形成输出结果。输出的信息称为输出向量。
隐藏层(Hidden layer),简称“隐层”,是输入层和输出层之间众多神经元和链接组成的各个层面。隐层可以有多层,习惯上会用一层。隐层的节点(神经元)数目不定,但数目越多神经网络的非线性越显著,从而神经网络的强健性
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4323.html
摘要:昨天,研究院开源了,业内较佳水平的目标检测平台。项目地址是实现顶尖目标检测算法包括的软件系统。因此基本上已经是最目前包含最全与最多目标检测算法的代码库了。 昨天,Facebook AI 研究院(FAIR)开源了 Detectron,业内较佳水平的目标检测平台。据介绍,该项目自 2016 年 7 月启动,构建于 Caffe2 之上,目前支持大量机器学习算法,其中包括 Mask R-CNN(何恺...
摘要:团队昨天发布的一个模型学会一切论文背后,有一个用来训练模型的模块化多任务训练库。模块化的多任务训练库利用工具来开发,定义了一个深度学习系统中需要的多个部分数据集模型架构优化工具学习速率衰减计划,以及超参数等等。 Google Brain团队昨天发布的一个模型学会一切论文背后,有一个用来训练MultiModel模型的模块化多任务训练库:Tensor2Tensor。今天,Google Brain...
摘要:对于大多数想上手深度学习的小伙伴来说,我应当从那篇论文开始读起这是一个亘古不变的话题。接下来的论文将带你深入理解深度学习方法深度学习在前沿领域的不同应用。 对于大多数想上手深度学习的小伙伴来说,我应当从那篇论文开始读起?这是一个亘古不变的话题。而对那些已经入门的同学来说,了解一下不同方向的论文,也是不时之需。有没有一份完整的深度学习论文导引,让所有人都可以在里面找到想要的内容呢?有!今天就给...
摘要:深度学习架构清单现在我们明白了什么是高级架构,并探讨了计算机视觉的任务分类,现在让我们列举并描述一下最重要的深度学习架构吧。是较早的深度架构,它由深度学习先驱及其同僚共同引入。这种巨大的差距由一种名为的特殊结构引起。 时刻跟上深度学习领域的进展变的越来越难,几乎每一天都有创新或新应用。但是,大多数进展隐藏在大量发表的 ArXiv / Springer 研究论文中。为了时刻了解动态,我们创建了...
摘要:我的核心观点是尽管我提出了这么多问题,但我不认为我们需要放弃深度学习。对于层级特征,深度学习是非常好,也许是有史以来效果较好的。认为有问题的是监督学习,并非深度学习。但是,其他监督学习技术同病相连,无法真正帮助深度学习。 所有真理必经过三个阶段:第一,被嘲笑;第二,被激烈反对;第三,被不证自明地接受。——叔本华(德国哲学家,1788-1860)在上篇文章中(参见:打响新年第一炮,Gary M...

阅读 3623·2023-04-26 01:40
阅读 3363·2021-11-24 09:39
阅读 1648·2021-10-27 14:19
阅读 2878·2021-10-12 10:11
阅读 1548·2021-09-26 09:47
阅读 2117·2021-09-22 15:21
阅读 3479·2021-09-06 15:00
阅读 1127·2021-08-10 09:44






