
摘要:最后在谷歌上找到一篇相关文章,大意是说这个是无解的,可能是系统安全的问题,对于这个解释我还是比较认可的,所以在上就不会提示。
背景
最近在使用selenium进行自动文件下载时,突然出现了一个报错:
下载进行不下去了。
思路经过各种谷歌、百度,均告诉我在要增加params,关闭浏览器安全选项,配置如下:
chromeOptions = webdriver.ChromeOptions()
prefs = {"profile.default_content_settings.popups": 0,
"download.default_directory": path,
"download.prompt_for_download": False,
# "download.directory_upgrade": "true",
"safebrowsing.enabled": True}
chromeOptions.add_experimental_option("prefs", prefs)
事实证明,可能以前的版本是可行的,现在的真心不行。
上面配置重点是"safebrowsing.enabled": True。在MacOS的环境下,哪怕不配也是没有问题的,Windows就不行了。
最后在谷歌上找到一篇相关文章,大意是说这个是无解的,可能是windows系统安全的问题,
对于这个解释我还是比较认可的,所以在mac上就不会提示。
Let’s start frankly: you can’t disable this feature. You can merely tweak the download settings in order to avoid it.https://windowsreport.com/typ...
那么问题来了,既然这样,有什么曲线救国的办法呢?
当chromedriver弹出这个提示的时候,其实文件已经下载完成,如下图:
我们只需要将文件名修改为正确的名字和后缀即可(比如test.txt),直接无视警告提醒。思路如下:
找到最新下载的文件:通过对下载目录的文件按照创建时间排序,找到最新的
判断是否该文件是否已下载完成:通过判断时间间隔前后该文件是否有大小的变化
结论根据上面思路,实现的关键代码如下:
def sort_file():
global path
dir_lists = os.listdir(path)
dir_lists.sort(key=lambda fn: os.path.getmtime(os.path.join(path, fn)))
return dir_lists[-1]
def changeName(path, oldname, newname):
old_path = os.path.join(path, oldname)
new_path = os.path.join(path, newname + ".txt")
if os.path.exists(old_path):
if os.path.exists(new_path):
os.remove(new_path)
os.rename(old_path, new_path)
print ("rename done!" + newname)
else:
print ("no file found!")
def download():
...
temp_filename = sort_file()
if u"未确认" in temp_filename:
temp_filesize_old = os.path.getsize(os.path.join(path, temp_filename))
while True:
time.sleep(1)
temp_filesize_new = os.path.getsize(os.path.join(path, temp_filename))
if temp_filesize_old == temp_filesize_new:
changeName(path, temp_filename, ip)
return
else:
temp_filesize_old = temp_filesize_new
else:
print(u"下载失败")
需要注意的是,在文件重命名的时候,先检查下文件是否已经存在,先删除,在创建。
以上。
如果有更好的思路,欢迎分享。
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/43401.html
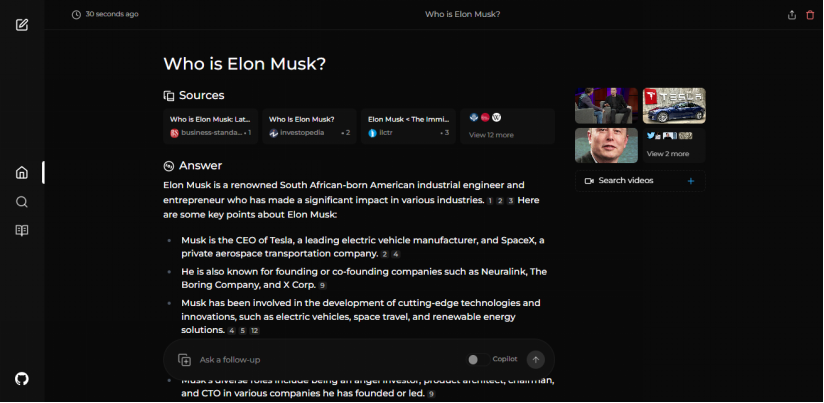
Perplexica是一个开源的人工智能搜索工具,也可以说是一款人工智能搜索引擎,它深入互联网以找到答案。受Perplexity AI启发,它是一个开源选择,不仅可以搜索网络,还能理解您的问题。它使用先进的机器学习算法,如相似性搜索和嵌入式技术,以精细化结果,并提供附有来源的清晰答案。利用SearxNG保持最新和完全开源,Perplexica确保您始终获取最新的信息,而不会损害您的隐私。特点本地L...
摘要:部署地域分布客户在业务部署区域的选择上也有不同,从客户业务部署地域分布来看,主要集中在国内的北京和上海,客户通常会选择购买业务部署区域的,也有客户采用多地域部署以提高业务的可用性,总体来看客户的需求集中在防御攻击防攻击以及满足合规需求。2021年UWAF累积为各个行业的客户提供了1117个域名的高质量访问服务,并提供安全防护,有效的保护了客户的数据信息与资产安全。2021年Web安全形势依然...

检查内容是否用了ChatGPT,准确率高达99.9%!OpenAI又左右互搏上了,给AI生成的文本打水印,高达99.9%准确率抓「AI枪手」作弊代写。其能够精准识别出论文或研究报告是否由ChatGPT撰写,甚至能追溯其使用的具体时间点。它能专门用来检测是否用ChatGPT水了论文/作业。早在2022年11月(ChatGPT发布同月)就已经提出想法了。但是!这么好用的东西,却被内部雪藏了2年,现在都...
小编这篇文章,就给大家传授一招技术,python+selenium实现扫码免密登录,第一步是扫码登录,获取cookies,然后保存到本地,为后面的免密登录做准备,那么具体操作步骤是什么呢?请各位读者继续往下看。 一、需求描述 web自动化测试/python爬虫往往会遇到扫码登录的情况,不是所有的网站都支持用户密码登录,遇到这种扫码登录的情况会阻碍我们自动化测试/爬虫的进行,所有为了可以...
小编写这篇文章的一个主要目的,主要是来给大家做一个解答,解答的内容是Python+Selenium,具体的一个内容解释是什么呢?比如,我们可以实现Geoserver批量发布Mongo矢量数据,具体的一个内容,下面就给大家详细解答下。 首先,声明一下,这里我完成的脚步属于半自动化的,我戏称它为有监督的半自动化脚本。具体原因后面会详细说明。 一、安装Selenium和ChromeDriver ...

阅读 3206·2023-04-26 00:53
阅读 3668·2021-11-19 09:58
阅读 1801·2021-09-29 09:35
阅读 3425·2021-09-28 09:46
阅读 4072·2021-09-22 15:38
阅读 2773·2019-08-30 15:55
阅读 3107·2019-08-23 14:10
阅读 3926·2019-08-22 18:17



