
摘要:前面我们通过几个数值展示了几个比较经典的网络的一些特性,下面我们就花一点时间来仔细观察网络的变化,首先是在网络结构上的一些思考,其次是对于单层网络内部的扩展,最后我们再来看看对于网络计算的改变。和这类结构主要看中的是模型在局部的拟合能力。
前面我们通过几个数值展示了几个比较经典的网络的一些特性,下面我们就花一点时间来仔细观察CNN网络的变化,首先是VGG在网络结构上的一些思考,其次是Inception Module对于单层网络内部的扩展,最后我们再来看看ResidualNet对于网络计算的改变。当然,我们在介绍这些模型的同时还会聊一些同时代其他的模型。
VGG模型
介绍VGG模型的文章中自夸了VGG模型的几个特点,下面我们来仔细说说,
首先是卷积核变小。实际上在VGG之前已经有一些模型开始尝试小卷积核了,VGG模型只是成功案例之中的一个。
那么小卷积核有什么好处呢?文章中提出了两个好处,首先是参数数量变少,过去一个7*7的卷积核需要49个参数,而现在3个3*3的卷积核有27个参数,看上去参数数量降低了不少;第二是非线性层的增加,过去7*7的卷积层只有1层非线性层与其相配,现在有3个3*3的卷积层有3个非线性层。非线性层的增加会使模型变得更加复杂,因此模型的表现力也有了提高。
同时在文章还提出了VGG的模型收敛速度比之前的AlexNet还要快些,从后来人的角度来看,参数训练的速度和本层参数的数量相关。之前我们分析过CNN模型参数的方差,我们假设对于某一层,这层的输入维度为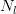 ,输出维度为
,输出维度为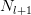 那么该层网络中每个参数的方差应该控制在
那么该层网络中每个参数的方差应该控制在 。如果输入输出层的维度比较大,那么参数的理想方差就需要限定的更小,所以参数可以取值的范围就比较小,那么优化起来就比较费劲;如果输入输出维度比较小,那么每个参数的理想方差就会相对大一些,那么可以取值的范围就比较大,优化起来就相对容易些。从这个角度来看,减小每一层参数的数量对于优化来说是有意义的。
。如果输入输出层的维度比较大,那么参数的理想方差就需要限定的更小,所以参数可以取值的范围就比较小,那么优化起来就比较费劲;如果输入输出维度比较小,那么每个参数的理想方差就会相对大一些,那么可以取值的范围就比较大,优化起来就相对容易些。从这个角度来看,减小每一层参数的数量对于优化来说是有意义的。
其次就是卷积层参数的规律。首先卷积层的操作不会改变输入数据的维度,这里的维度主要指feature map的长和宽。对于3*3的kernel,卷积层都会配一个大小为1的pad。同时stride被设为1。这样经过卷积层变换,长宽没有发生变化。这和之前的卷积层设计有些不同。而且每做一次pooling,feature map的长宽各缩小一倍,channel层就会增加一倍。这样的设计对于不同的feature map维度来说适配起来都比较容易。对于一些通过卷积减小维度的模型来说,对于不同的输入,卷积后的输出各不一样,所以适配起来有可能不太方便,而现在只有pooling层改变长宽维度,整体模型的维度计算就方便了许多。于是在论文中有输入为256和384等维度,模型不需要根据不同的输入维度设计不同的卷积结构,使用同样的结构或者直接加深网络深度就可以了。
此外,模型也提到了1*1的卷积核,这个卷积核我们在后面还会提到。这种卷积核也不会改变feature map的长宽,同时又可以进一步地增加模型的非线性层,也就增加了模型的表现能力。
上面就是VGGNet在架构上做的这些改变,这些改变也被后面一些的模型所接纳。
丰富模型层的内部结构
提到模型的内部结构,我们就来到了GoogLeNet模型(这个英文单词是在致敬LeNet?),模型中最核心的地方就是它的Inception Module。在此之前还有一个研究模型层内部结构的文章,叫做Network In Network,其中的道理也比较相似。
Network in Network和Inception Module这类结构主要看中的是模型在局部的拟合能力。有些模型在结构上是采用“一字长蛇阵”的方法,对于某一个特定的尺度,模型只采用一个特定尺度的卷积核进行处理,而上面两种模型却认为,采用一种尺度处理可能不太够,一张图象通常具有总体特征特征和细节特征这两类特征,我们用小卷积核能够更好地捕捉一些细节特征,而随着小卷积不断地卷下去,慢慢地一些总体特征也就被发现。
可是这里有一个问题,那就是我们在网络前段只有细节特征,后段才慢慢有一些总体特征,而有时候我们想让两方面的特征汇集在一起,同时出现发挥作用。那么采用单一的卷积核恐怕不太容易解决这样的问题。
于是上面两种模型开始考虑,与其把模型加深,不如把模型加厚(其实深度差不多),每一次feature map尺度的变化前后,我都尽可能地多做分析,把想得到的不同来源的信息都尽可能得到,这样的特征应该会更有价值吧!
从乘法模型到加法模型
ResNet的核心思路就是把曾经CNN模型中的乘法关系转变成加法关系,让模型有了点“Additive”的味道。关于这个问题,文章中采用一个极端的例子作说明。
假设我们已经有了一个较浅模型,我们的目标是去训练一个更深的模型。理论上如果我们能够找到一个靠谱的优化算法和足够的数据,那么这个更深的模型理论上应该比那个较浅的模型具有更好的表达能力。如果抛开优化和可能的过拟合问题不管,这个道理还是可以成立的。
就算较深的模型不能够超越较浅的模型,至少它是可以作到和具有较浅的模型同样的表达能力。如果我们把较深模型分成两部分——和较浅模型相同的部分,比较浅模型多出来的部分,那么我们保持和较浅模型相同的部分的参数完全相同,同时让多出来的模型部分“失效”,只原样传递数据而不做任何处理,那么较深模型就和较浅的模型完全一样了。在论文中,这些多出来的模型部分变成了“Identity Mapping”,也就是输入和输出完全一样。
好了,那么对于现在的架构来说,我们如何学习这些“Identity Mapping”呢?过去的学习方法就是按现在的乘法模式进行学习,我们一般的CNN模型都是一层套一层,层与层之间的关系是乘法,下一层的输出是上一层输入和卷积相乘得到的。学习这样的“Identity Mapping”还是有一点困难的,因为只要是想学到一个具体数值,它就具有一定的难度,不论是“Identity Mapping”还是其他。
于是,ResNet对上面的问题做了一些改变。既然是要学习“Identity Mapping”,那么我们能不能把过去的乘法转变为加法?我们假设多出来的层的函数形式是F(x),那么乘法关系学习“Identity Mapping”就变成了 ,由于学习的形式没有变,对于乘法我们学习起来同过去一样,但是对于加法就简单多了——
,由于学习的形式没有变,对于乘法我们学习起来同过去一样,但是对于加法就简单多了——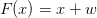 ,只要将参数学习成0就可以了,0和其他数值相比具有很大的优势,这样训练难度就大大降低了。于是,我们也见到即使非常深的网络也可以训练,这也验证了将乘法关系改为加法关系后对模型训练带来的显著提升。
,只要将参数学习成0就可以了,0和其他数值相比具有很大的优势,这样训练难度就大大降低了。于是,我们也见到即使非常深的网络也可以训练,这也验证了将乘法关系改为加法关系后对模型训练带来的显著提升。
在ResNet之前,还有一些网络已经提出了类似的思想,比如Highway-Network。Highway-Network同样具有加法的特点,但是它并不是一个纯粹的加法,所以在优化过程总较ResNet弱一些。
这样我们就回顾完了上次我们提到的几个模型中的闪光点,如果想进一步地研究这些模型以及模型结构中的精妙之处,多多做实验多多分析数据才是王道。
最后一点
为什么GoogLeNet和ResNet的层数很深且参数很少?因为他们的全连接层比较少。为什么呢?
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4406.html
摘要:一时之间,深度学习备受追捧。百度等等公司纷纷开始大量的投入深度学习的应用研究。极验验证就是将深度学习应用于网络安全防御,通过深度学习建模学习人类与机器的行为特征,来区别人与机器,防止恶意程序对网站进行垃圾注册,撞库登录等。 2006年Geoffery Hinton提出了深度学习(多层神经网络),并在2012年的ImageNet竞赛中有非凡的表现,以15.3%的Top-5错误率夺魁,比利用传...
摘要:最后,我们显示了若干张图像中所生成的趣味字幕。图所提出的有趣字幕生成的体系结构。我们将所提出的方法称为神经玩笑机器,它是与预训练模型相结合的。用户对已发布的字幕的趣味性进行评估,并为字幕指定一至三颗星。 可以毫不夸张地说,笑是一种特殊的高阶功能,且只有人类才拥有。那么,是什么引起人类的笑声表达呢?最近,日本东京电机大学(Tokyo Denki University)和日本国家先进工业科学和技...
摘要:分组卷积的思想影响比较深远,当前一些轻量级的网络,都用到了分组卷积的操作,以节省计算量。得到新的通道之后,这时再对这批新的通道进行标准的跨通道卷积操作。 CNN从2012年的AlexNet发展至今,科学家们发明出各种各样的CNN模型,一个比一个深,一个比一个准确,一个比一个轻量。作者对近几年一些具有变革性的工作进行简单盘点,从这些充满革新性的工作中探讨日后的CNN变革方向。本文只介绍其中具有...
摘要:本文详细讨论了自然语言理解的难点,并进一步针对自然语言理解的两个核心问题,详细介绍了规则方法和深度学习的应用。引言自然语言理解是人工智能的核心难题之一,也是目前智能语音交互和人机对话的核心难题。 摘要:自然语言理解是人工智能的核心难题之一,也是目前智能语音交互和人机对话的核心难题。之前写过一篇文章自然语言理解,介绍了当时NLU的系统方案,感兴趣的可以再翻一番,里面介绍过的一些内容不再赘...
摘要:近几年以卷积神经网络有什么问题为主题做了多场报道,提出了他的计划。最初提出就成为了人工智能火热的研究方向。展现了和玻尔兹曼分布间惊人的联系其在论文中多次称,其背后的内涵引人遐想。 Hinton 以深度学习之父 和 神经网络先驱 闻名于世,其对深度学习及神经网络的诸多核心算法和结构(包括深度学习这个名称本身,反向传播算法,受限玻尔兹曼机,深度置信网络,对比散度算法,ReLU激活单元,Dropo...

阅读 2078·2021-11-24 09:38
阅读 3419·2021-11-22 12:07
阅读 2040·2021-09-22 16:03
阅读 2067·2021-09-02 15:41
阅读 2714·2021-07-24 23:28
阅读 2305·2019-08-29 13:17
阅读 1633·2019-08-29 12:25
阅读 2734·2019-08-29 11:10






