
摘要:项目可以让你使用在驱动的你的浏览器上运行训练好的模型。内核卷积本地连接噪声备注及其限制可以与主线程分开多带带运行在中。所以在多带带的线程中运行的好处被必须运行在模式中的要求抵消了。所有的测试都会自动运行。
项目可以让你使用 WebGL 在 GPU 驱动的、你的浏览器上运行训练好的 Keras 模型。模型直接根据 Keras JSON 格式配置文件和关联的 HDF5 权重而序列化(serialized)。
项目地址:https://github.com/transcranial/keras-js
互动演示
用于 MNIST 的基本卷积网络
在 MNIST 上训练的卷积变自编码器(Convolutional Variational Autoencoder)
在 ImageNet 上训练的 50 层的残差网络(Residual Network)
在 ImageNet 上训练的 Inception V3
用于 IMDB 情绪分类的双向 LSTM
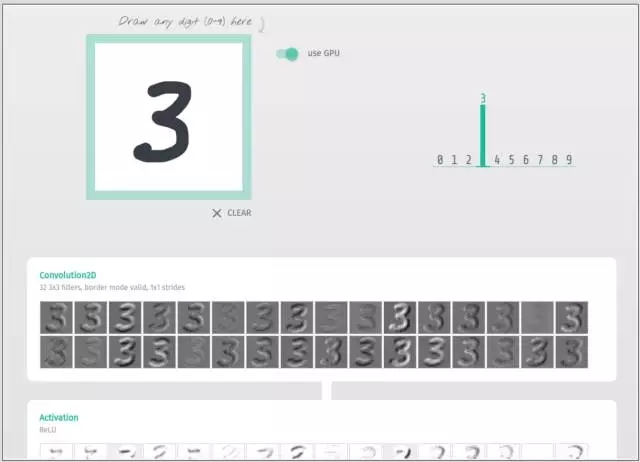

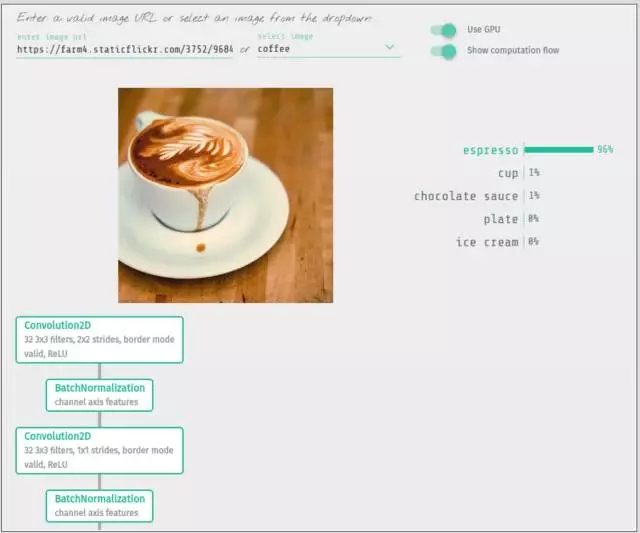
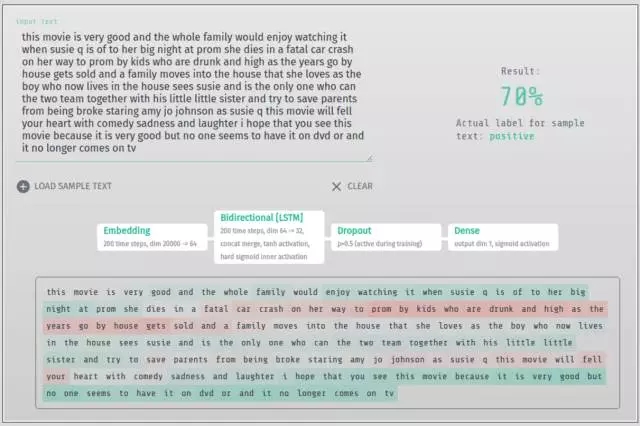
为什么要做这个项目?
消除对后端基础设施或 API 调用的需求
完全将计算卸载到客户端浏览器
互动应用程序
使用方法
查看 demos/src/ 获取真实案例的源代码。
1. 对 Model 和 Sequential 都适用
model = Sequential()
model.add(...)
...
...
model = Model(input=..., output=...)
一旦训练完成,保存权重和导出模型架构配置:
model.save_weights("model.hdf5")
with open("model.json", "w") as f:
f.write(model.to_json())
参见演示的 jupyter notebooks 了解详情:demos/notebooks/
2. 在 HDF5 权重文件上运行编码器脚本:
$ python encoder.py /path/to/model.hdf5
这将在同一个文件夹中产生两个用作 HDF5 权重的文件:model_weights.buf 和 model_metadata.json
3.Keras.js 所需的三个文件:
模型文件:model.json
权重文件:model_weights.buf
权重元数据文件:model_metadata.json
4.GPU 支持由 weblas(https://github.com/waylonflinn/weblas) 驱动。将 Keras.js 和 Weblas 库包含进去:
5. 创建新模型
实例化时,数据通过 XHR(相同域或要求 CORS)加载,层被初始化为有向无环图。当这些步骤完成之后,类方法 ready() 返回一个解决问题的 Promise。然后,使用 perdict() 让数据通过模型,这也会返回一个 Promise。
const model = new KerasJS.Model({
filepaths: {
model: "url/path/to/model.json",
weights: "url/path/to/model_weights.buf",
metadata: "url/path/to/model_metadata.json"
}
gpu: true
})
model.ready().then(() => {
// input data object keyed by names of the input layers
// or `input` for Sequential models
// values are the flattened Float32Array data
// (input tensor shapes are specified in the model config)
const inputData = {
"input_1": new Float32Array(data)
}
// make predictions
// outputData is an object keyed by names of the output layers
// or `output` for Sequential models
model.predict(inputData).then(outputData => {
// e.g.,
// outputData["fc1000"]
})
})
可用的层
高级激活: LeakyReLU, PReLU, ELU, ParametricSoftplus, ThresholdedReLU, SReLU
卷积: Convolution1D, Convolution2D, AtrousConvolution2D, SeparableConvolution2D, Deconvolution2D, Convolution3D, UpSampling1D, UpSampling2D, UpSampling3D, ZeroPadding1D, ZeroPadding2D, ZeroPadding3D
内核: Dense, Activation, Dropout, SpatialDropout2D, SpatialDropout3D, Flatten, Reshape, Permute, RepeatVector, Merge, Highway, MaxoutDense
嵌入: Embedding
归一化: BatchNormalization
池化: MaxPooling1D, MaxPooling2D, MaxPooling3D, AveragePooling1D, AveragePooling2D, AveragePooling3D, GlobalMaxPooling1D, GlobalAveragePooling1D, GlobalMaxPooling2D, GlobalAveragePooling2D
循环: SimpleRNN, LSTM, GRU
包装器: Bidirectional, TimeDistributed
还没有实现的层
目前还不能直接实现 Lambda,但最终会创建一个通过 JavaScript 定义计算逻辑的机制。
内核: Lambda
卷积: Cropping1D, Cropping2D, Cropping3D
本地连接: LocallyConnected1D, LocallyConnected2D
噪声:GaussianNoise, GaussianDropout
备注
WebWorker 及其限制
Keras.js 可以与主线程分开多带带运行在 WebWorker 中。因为 Keras.js 会执行大量同步计算,这可以防止该 UI 受到影响。但是,WebWorker 的较大限制之一是缺乏
WebGL MAX_TEXTURE_SIZE
在 GPU 模式中,张量对象被编码成了计算之前的 WebGL textures。这些张量的大小由 gl.getParameter(gl.MAX_TEXTURE_SIZE) 限定,这会根据硬件或平台的状况而有所不同。参考 http://webglstats.com/ 了解典型的预期值。在 im2col 之后,卷积层中可能会有一个问题。比如在 Inception V3 网络演示中,第一层卷积层中 im2col 创造了一个 22201 x 27 的矩阵,并在第二层和第三层卷积层中创造 21609 x 288 的矩阵。第一个维度上的大小超过了 MAX_TEXTURE_SIZE 的较大值 16384,所以必须被分割开。根据权重为每一个分割开的张量执行矩阵乘法,然后再组合起来。在这个案例中,当 createWeblasTensor() 被调用时,Tensor 对象上会提供一个 weblasTensorsSplit 属性。了解其使用的例子可查看 src/layers/convolutional/Convolution2D.js
开发/测试
对于每一个实现的层都存在广泛的测试。查看 notebooks/ 获取为所有这些测试生成数据的 jupyter notebooks。
$ npm install
要运行所有测试,执行 npm run server 并访问 http://localhost:3000/test/。所有的测试都会自动运行。打开你的浏览器的开发工具获取额外的测试数据信息。
对于开发,请运行:
$ npm run watch
编辑 src/ 中的任意文件都会触发 webpack 来更新 dist/keras.js。
要创建生产型的 UMD webpack 版本,输出到 dist/keras.js,运行:
$ npm run build
证书
MIT:https://github.com/transcranial/keras-js/blob/master/LICENSE
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4410.html
摘要:第一个深度学习框架该怎么选对于初学者而言一直是个头疼的问题。简介和是颇受数据科学家欢迎的深度学习开源框架。就训练速度而言,胜过对比总结和都是深度学习框架初学者非常棒的选择。 「第一个深度学习框架该怎么选」对于初学者而言一直是个头疼的问题。本文中,来自 deepsense.ai 的研究员给出了他们在高级框架上的答案。在 Keras 与 PyTorch 的对比中,作者还给出了相同神经网络在不同框...
摘要:增强现实以下简称浪潮正滚滚而来,浏览器作为人们最唾手可得的人机交互终端,正在大力发展技术。目前年底前端要想实现,都是靠的视频透视式技术。但这两个都是移动的,于是谷歌的团队提供了和两个库,以便开发者能用技术来基于和开发,从而实现。 本文作者 GeekPlux,博客地址:http://geekplux.com/2018/01/18/augmented-reality-development...
摘要:在年月首次推出,现在用户数量已经突破了万。其中有数百人为代码库做出了贡献,更有数千人为社区做出了贡献。现在我们推出,它带有一个更易使用的新,实现了与的直接整合。类似的,正在用实现份额部分规范,如。大量的传统度量和损失函数已被移除。 Keras 在 2015 年 3 月首次推出,现在用户数量已经突破了 10 万。其中有数百人为 Keras 代码库做出了贡献,更有数千人为 Keras 社区做出了...
摘要:前言作为一名在本科期间做过前端,研究生期间研究了深度学习,目前是一名前端开发工程师的我,应该说一下我作为前端开发工程师在人工智能浪潮里该做些什么。 前言 作为一名在本科期间做过前端,研究生期间研究了深度学习,目前是一名前端开发工程师的我,应该说一下我作为前端开发工程师在人工智能浪潮里该做些什么。 如何看待人工智能 本人是深度学习方向探索过三年的研究生,在老师的洗脑下对深度学习和整个人工...

阅读 3349·2023-04-25 20:22
阅读 3523·2019-08-30 11:14
阅读 2804·2019-08-29 13:03
阅读 3402·2019-08-26 13:47
阅读 3490·2019-08-26 10:22
阅读 1456·2019-08-23 18:26
阅读 848·2019-08-23 17:16
阅读 2109·2019-08-23 17:01





