
摘要:深度学习近年来在中广泛使用,在机器阅读理解领域也是如此,深度学习技术的引入使得机器阅读理解能力在最近一年内有了大幅提高,本文对深度学习在机器阅读理解领域的技术应用及其进展进行了归纳梳理。目前的各种阅读理解任务中完形填空式任务是最常见的类型。
关于阅读理解,相信大家都不陌生,我们接受的传统语文教育中阅读理解是非常常规的考试内容,一般形式就是给你一篇文章,然后针对这些文章提出一些问题,学生回答这些问题来证明自己确实理解了文章所要传达的主旨内容,理解地越透彻,学生越能考出好的成绩。
如果有一天机器能够做类似于我们人类做阅读理解任务,那会发生什么呢?很明显教会机器学会阅读理解是自然语言处理(NLP)中的核心任务之一。如果哪一天机器真能具备相当高水准的阅读理解能力,那么很多应用便会体现出真正的智能。比如搜索引擎会在真正理解文章内容基础上去回答用户的问题,而不是目前这种以关键词匹配的方式去响应用户,这对于搜索引擎来说应该是个技术革命,其技术革新对产品带来的巨大变化,远非在关键词匹配之上加上链接分析这种技术进化所能比拟的。而众所周知,谷歌其实就是依赖链接分析技术起家的,所以如果机器阅读理解技术能够实用化,对搜索引擎领域带来的巨变很可能是颠覆性的。对话机器人如果换个角度看的话,其实也可以看做是一种特殊的阅读理解问题,其他很多领域也是如此,所以机器阅读理解是个非常值得关注的技术方向。
深度学习近年来在NLP中广泛使用,在机器阅读理解领域也是如此,深度学习技术的引入使得机器阅读理解能力在最近一年内有了大幅提高,本文对深度学习在机器阅读理解领域的技术应用及其进展进行了归纳梳理。
什么是机器阅读理解
机器阅读理解其实和人阅读理解面临的问题是类似的,不过为了降低任务难度,很多目前研究的机器阅读理解都将世界知识排除在外,采用人工构造的比较简单的数据集,以及回答一些相对简单的问题。给定需要机器理解的文章以及对应的问题,比较常见的任务形式包括人工合成问答、Cloze-style queries和选择题等方式。
人工合成问答是由人工构造的由若干简单事实形成的文章以及给出对应问题,要求机器阅读理解文章内容并作出一定的推理,从而得出正确答案,正确答案往往是文章中的某个关键词或者实体。比如图1展示了人工合成阅读理解任务的示例。图1示例中前四句陈述句是人工合成的文章内容,Q是问题,而A是标准答案。

图1. 人工合成阅读理解任务示例
Cloze-style queries是类似于“完形填空”的任务,就是让计算机阅读并理解一篇文章内容后,对机器发出问题,问题往往是抽掉某个单词或者实体词的一个句子,而机器回答问题的过程就是将问题句子中被抽掉的单词或者实体词预测补全出来,一般要求这个被抽掉的单词或者实体词是在文章中出现过的。图2展示了完形填空式阅读理解任务的示例。图中表明了文章内容、问题及其对应的答案。这个例子是将真实的新闻数据中的实体词比如人名、地名等隐去,用实体标记符号替换掉实体词具体名称,问题中一般包含个占位符placeholder,这个占位符代表文章中的某个实体标记,机器阅读理解就是在文章中找出能够回答问题的某个真实答案的实体标记。目前的各种阅读理解任务中“完形填空式”任务是最常见的类型。

图2.完形填空式阅读理解
还有一种任务类型是选择题,就是阅读完一篇文章后,给出问题,正确答案是从几个选项中选择出来的,典型的任务比如托福的听力测试,目前也有研究使用机器来回答托福的听力测试,这本质上也是一种阅读理解任务。

图3.托福听力测试题示例
如果形式化地对阅读理解任务和数据集进行描述的话,可以将该任务看作是四元组:

其中,代表一篇文章,代表针对文章内容提出的一个问题,是问题的正确答案候选集合而代表正确答案。对于选择题类型来说,就是明确提供的答案候选集合而是其中的正确选项。对于人工合成任务以及完形填空任务来说,一般要求:
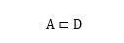
也就是说,要求候选答案是在文章中出现过的词汇或者实体词。
深度学习技术进展
本节内容对目前机器阅读理解领域中出现的技术方案进行归纳梳理,正像本文标题所述,我们只对深度学习相关的技术方案进行分析,传统技术方案不在讨论之列。
1.文章和问题的表示方法
用神经网络处理机器阅读理解问题,首先面临的问题就是如何表示文章和问题这两个最重要的研究对象。我们可以从现有机器阅读理解相关文献中归纳总结出常用的表示方法,当然这些表示方法不仅仅局限于阅读理解问题,也经常见于NLP其他子领域中。
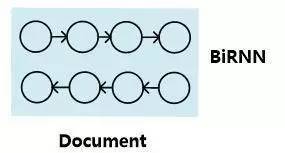
图4.文档表示方法:模型一
首先,对于机器阅读理解中的文章来说,有两种常见的文章内容表达方式。最常见的一种即是将一篇文章看成有序的单词流序列(参考图4的模型一,图中每个圆即代表某个单词的神经网络语义表达,图中的BiRNN代表双向RNN模型),在这个有序序列上使用RNN来对文章进行建模表达,每个单词对应RNN序列中的一个时间步t的输入,RNN的隐层状态代表融合了本身词义以及其上下文语义的语言编码。这种表示方法并不对文章整体语义进行编码,而是对每个单词及其上下文语义进行编码,在实际使用的时候是使用每个单词的RNN隐层状态来进行相关计算。至于具体的RNN模型,常见的有标准RNN、LSTM、GRU及其对应的双向版本等。对于机器阅读理解来说双向RNN是最常用的表示方法,一般每个单词的语义表示由正向RNN隐层状态和反向RNN隐层状态拼接来表示,即:
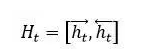
模型一往往在机器阅读理解系统的原始输入部分对文章进行表征,因为对于很多阅读理解任务来说,本质上是从文章中推导出某个概率较大的单词作为问题的答案,所以对文章以单词的形式来表征非常自然。
另外一种常见的文章内容表达方式则是从每个单词的语义表达推导出文章整体的Document Embedding表达,这种形式往往是在对问题和文章进行推理的内部过程中使用的表达方式。典型的表达过程如图5所示的模型二所示。
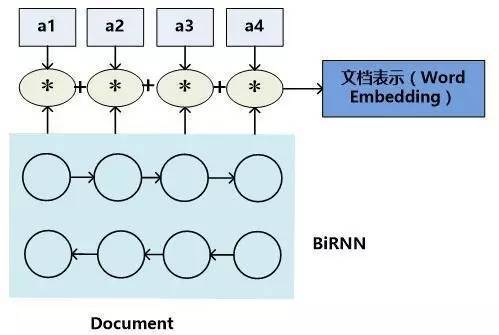
图5. 文档表示方法:模型二
模型二的含义是:首先类似于模型一,用双向RNN来对每个单词及其上下文进行语义表征,形成隐层状态表示,然后对于向量的每一维数值,乘以某个系数,这个系数代表了单词对于整个文章最终语义表达的重要程度,将每个单词的系数调整后的隐层状态累加即可得到文章的Word Embedding语义表达。而每个单词的权重系数通常用Attention计算机制来计算获得,也有不使用权重系数直接累加的方式,这等价于每个单词的权重系数都是1的情形,所以可以看作加权平均方法的特殊版本。以公式表达的话,文章的语义表达公式如下:
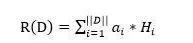
对于机器阅读理解中的问题来说,有三种常见的语义表达方式。如果将查询看作一种特殊的文章的话,很明显文章的语义表达方式同样可以用来表征问题的语义,也就是类似于文档表示方法的模型一和模型二。问题的表示方法模型一如图6所示,模型二如图7所示,其代表的含义与文章表征方式相似,所以此处不赘述。
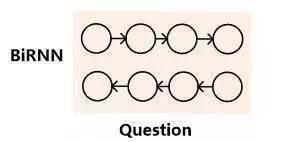
图6.问题表示方式:模型一
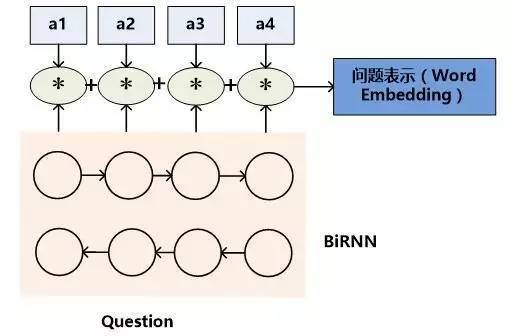
图7.问题表示方法:模型二
问题表示方法的另外一种表示如图8所示,我们可以称之为模型三。

图8.问题表示方法:模型三
模型三也是在模型一的基础之上的改进模型,也是NLP任务中表达句子语义的最常见的表达方式。首先类似于模型一,使用双向RNN来表征每个单词及其上下文的语义信息。对于正向RNN来说,其尾部单词(句尾词)RNN隐层节点代表了融合了整个句子语义的信息;而反向RNN的尾部单词(句首词)则逆向融合了整个句子的语义信息,将这两个时刻RNN节点的隐层状态拼接起来则可以表征问题的整体语义:
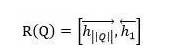
理论上模型三也可以用来表征文章的语义信息,但是一般不会这么用,主要原因是文章往往都比较长,RNN对于太长的内容表征能力不足,所以类似模型三的方法会存在大量的信息丢失,而“问题”一般来说都是比较短的一句话,所以用模型三表征是比较合适的。
以上介绍的几个模型是在机器阅读理解领域里常用的表征文章和问题的表示方法。下面我们从机器阅读理解神经网络结构的角度来进行常用模型的介绍。
2、机器阅读理解的深度学习模型
目前机器阅读理解研究领域出现了非常多的具体模型,如果对这些模型进行技术思路梳理的话,会发现本质上大多数模型都是论文“Teaching Machines to Read and Comprehend”提出的两个基础模型”Attentive Reader”和“Impatient Reader”的变体(参考文献1),当然很多后续模型在结构上看上去有了很大的变化,但是如果仔细推敲的话会发现根源和基础思路并未发生颠覆性的改变。
我们将主流模型技术思路进行归纳梳理以及某些技术点进行剥离组合,将其归类为“一维匹配模型”、“二维匹配模型”、“推理模型”等三类模型,其中“一维匹配模型”和“二维匹配模型”是基础模型,“推理模型”则是在基础模型上重点研究如何对文本内容进行推理的机制。当然,还有个别模型在结构上有其特殊性,所以最后会对这些模型做些简介。
2.1 一维匹配模型
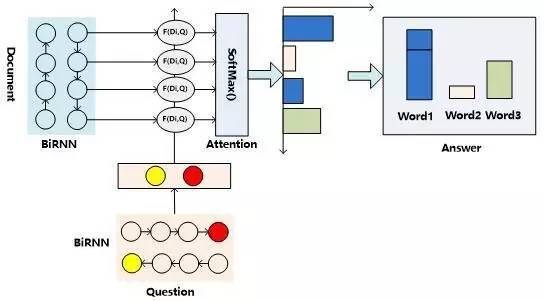
图9. 机器阅读理解的一维匹配结构
目前机器阅读理解任务的解决方案中,有相当多的模型可以被归类到“一维匹配模型”这种技术范型中,这类模型本质上是“Attentive Reader”的变体。我们首先介绍这种技术思路的总体流程结构,然后说明下主流方法在这个框架下的一些区别。
图9所示是“一维匹配模型”的技术流程示意图:首先,对文章内容使用“文章表示方法:模型一”的方式对文章语义内容进行编码,对于问题来说,则一般会使用“问题表示方法:模型三”的方式对问题进行语义编码,即使用双向RNN的头尾部节点RNN隐层状态拼接作为问题的语义表示。然后,通过某种匹配函数来计算文章中每个单词Di(编码中包括单词语义及其上下文单词的语义)语义和问题Q整体语义的匹配程度,从含义上可以理解为F是计算某个单词Di是问题Q的答案的可能性映射函数。接下来,对每个单词的匹配函数值通过SoftMax函数进行归一化,整个过程可以理解为Attention操作,意即凸显出哪些单词是问题答案的可能性。最后,因为一篇文章中,某个单词可能在多处出现,而在不同位置出现的同一个单词都会有相应的Attention计算结果,这代表了单词在其具体上下文中是问题答案的概率,将相同单词的Attention计算出的概率值进行累加,即可作为该单词是问题Q答案的可能性,选择可能性较大的那个单词作为问题的答案输出。在最后相同单词概率值累加这一步,一般容易质疑其方式:如果这样,那么意味着这个方法隐含一个假设,即出现次数越多的单词越可能成为问题的答案,这样是否合理呢?实验数据表明,这个假设基本是成立的,所以这种累加的方式目前是非常主流的技术方案,后文所述的AS Reader和GA Reader采取了这种累加模式,而Stanford AR和Attentive Reader则采取非累加的模式。之所以将这个结构称为“一维匹配模型”,主要是其在计算问题Q和文章中单词序列的匹配过程形成了一维线性结构。
上述内容是“一维匹配模型”的基本思路,很多主流的模型基本都符合上述架构,模型之间的较大区别主要是匹配函数的定义不同。具体而言,“Attention Sum Reader”,(后文简称AS Reader,参考文献2)、“Stanford Attentive Reader”(后文简称 Stanford AR,参考文献3)、“Gated-Attention Reader”(后文简称GA Reader,参考文献4)、“Attentive Reader”(参考文献1)、AMRNN(参考文献5)等模型都基本遵循这个网络结构。
AS Reader可以看作是一维匹配结构的典型示例,其匹配函数定义为Di和Q向量的点积:
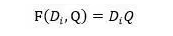
Attentive Reader是最早提出的模型之一,所以在整体结构上和一维匹配结构有些差异,模型性能相对差些,不过这些结构上的差异点并非性能差异的关键,而匹配函数能够解释其和效果好的模型性能差异的主要原因,其采用了前向神经网络的形式:

Stanford AR的匹配函数则采用了双线性(Bilinear)函数:

这里需要说明的是,Stanford AR的效果已经是目前所有机器阅读理解模型中性能较好的之一,同时其一维匹配模型相对简单,且没有采用深层的推理机制,所以这个模型是值得关注的。而其相对Attentive Reader来说,对提升性能最主要的区别就在于采用了双线性函数,而这个改变对性能提升带来了极大的帮助;相对AS Reader来说,其性能也有明显提升,很明显双线性函数在其中起了主要作用。由此可见,目前的实验结果支持双线性函数效果明显优于很多其它匹配模型的结论。
AMRNN是用来让机器做TOFEL听力题的阅读理解系统采用的技术方案,类似于GA Reader的整体结构,其是由一维匹配模型加深层网络组合而成的方案,同样的,深层网络是为了进行推理,如果摘除深层网络结构,其结构与AS Reader也是基本同构的。其采用的匹配函数则使用Di和Q的Cosine相似性,类似于AS Reader向量点积的思路。AMRNN解决的是选择题而非完形填空任务,所以在输出阶段不是预测文中哪个单词或实体是问题的答案,而是对几个候选答案选项进行评估,从中选择正确答案。
由上述模型对比可以看出,一维匹配模型是个结构简洁效果整体而言也不错的模型范式,目前相当多的具体模型可以映射到这个范式中,而其中的关键点在于匹配函数如何设计,这一点是导致具体模型性能差异的相当重要的影响因素。可以预见,后续的研究中必然会把重心放在如何改进设计出更好地匹配函数中来。
2.2 二维匹配模型
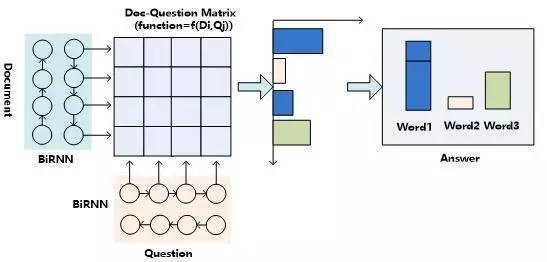
图10. 机器阅读理解的二维匹配结构
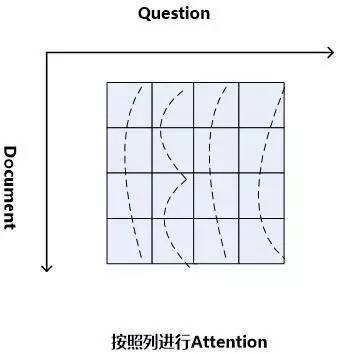
顾名思义,“二维匹配模型”是相对“一维匹配模型”而言的,其最初的思想其实体现在”Impatient Reader”的思路中。图10是机器阅读理解中二维匹配模型的整体流程示意图,从中可以看出,其整体结构与一维匹配模型是类似的,最主要的区别体现在如何计算文章和问题的匹配这个层面上。与一维匹配模型不同的是:二维匹配模型的问题表征方式采用“问题表示方法:模型一”,就是说不是将问题的语义表达为一个整体,而是问题中的每个单词都多带带用Word Embedding向量来表示。这样,假设文档长度为||D||,问题长度为||Q||,那么在计算问题和文章匹配的步骤中,就形成了||D||*||Q||的二维矩阵,就是说文章中任意单词Di和问题中的任意单词Qj都应用匹配函数来形成矩阵的位置的值。
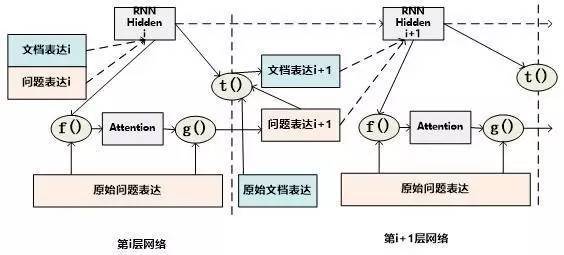
当二维矩阵的值根据匹配函数填充完毕后,就可以考虑进行Attention计算。因为是二维矩阵,所以可以有很多种不同的Attention计算机制。比如可以如图11这样按照二维矩阵的行来进行Attention计算,因为矩阵的一行代表文档中某个单词Di相对问题中每个单词Qj(1 图11.二维结构按行进行Attention 图12. 二维结构按列进行Attention Consensus Attention 模型(后文简称CA Reader,参考文献6)、Attention-over-Attention模型(后文简称AOA Reader,参考文献7)和Match-LSTM模型(参考文献8)基本都符合二维匹配结构的范式,其主要区别在于Attention计算机制的差异上。CA Reader按照列的方式进行Attention计算,然后对每一行文档单词对应的针对问题中每个单词的Attention向量,采取一些启发规则的方式比如取行向量中较大值或者平均值等方式获得文档每个单词对应的概率值。AOA Reader则对CA Reader进行了改进,同时结合了按照列和按照行的方式进行Attention计算,核心思想是把启发规则改为由按行计算的Attention值转换成的系数,然后用对按列计算出的Attention加权平均的计算方式获得文档每个单词对应的概率值。Match-LSTM模型则是按行进行Attention计算,同样地把这些Attention值转换成列的系数,不过与AOA不同的是,这些系数用来和问题中每个单词的Word Embedding相乘并对Word Embedding向量加权求和,拟合出整个问题的综合语义Word Embedding(类似于“问题表示方法:模型二”思路),并和文章中每个单词的Word Embedding进行合并,构造出另外一个LSTM结构,在这个LSTM结构基础上去预测哪个或者那些单词应该是正确答案。 由于二维匹配模型将问题由整体表达语义的一维结构转换成为按照问题中每个单词及其上下文的语义的二维结构,明确引入了更多细节信息,所以整体而言模型效果要稍优于一维匹配模型。 从上面的具体模型介绍可以看出,目前二维匹配模型相关工作还不多,而且都集中在二维结构的Attention计算机制上,由于模型的复杂性比较高,还有很多很明显的值得改进的思路可以引入。最直观的改进就是探索新的匹配函数,比如可以摸索双线性函数在二维结构下的效果等;再比如可以引入多层网络结构,这样将推理模型加入到阅读理解解决方案中等。可以预见,类似的思路很快会被探索。 2.3 机器阅读理解中的推理过程 人在理解阅读文章内容的时候,推理过程几乎是无处不在的,没有推理几乎可以断定人是无法完全理解内容的,对于机器也是如此。比如对于图1中所展示的人工合成任务的例子,所提的问题是问苹果在什么地方,而文章表达内容中,刚开始苹果在厨房,Sam将其拿到了卧室,所以不做推理的话,很可能会得出“苹果在厨房”的错误结论。 乍一看“推理过程”是个很玄妙而且说不太清楚的过程,因为自然语言文本不像一阶逻辑那样,已经明确地定义出符号以及表达出符号之间的逻辑关系,可以在明确的符号及其关系上进行推理,自然语言表达有相当大的模糊性,所以其推理过程一直是很难处理好的问题。 现有的工作中,记忆网络(Memory Networks,参考文献9)、GA Reader、Iterative Alternating神经网络(后文简称IA Reader,参考文献10)以及AMRNN都直接在网络结构中体现了这种推理策略。一般而言,机器阅读理解过程网络结构中的深层网络都是为了进行文本推理而设计的,就是说,通过加深网络层数来模拟不断增加的推理步骤。 图13. 记忆网络的推理过程 记忆网络是最早提出推理过程的模型,对后续其它模型有重要的影响。对于记忆网络模型来说,其第一层网络的推理过程(Layer-Wise RNN模式)如下(参考图13):首先根据原始问题的Word Embedding表达方式以及文档的原始表达,通过f函数计算文档单词的Attention概率,然后g函数利用文章原始表达和Attention信息,计算文档新的表达方式,这里一般g函数是加权求和函数。而t函数则根据文档新的表达方式以及原始问题表达方式,推理出问题和文档最终的新表达方式,这里t函数实际上就是通过两者Word Embedding的逐位相加实现的。t函数的输出更新下一层网络问题的表达方式。这样就通过隐式地内部更新文档和显示地更新问题的表达方式实现了一次推理过程,后续每层网络推理过程就是反复重复这个过程,通过多层网络,就实现了不断通过推理更改文档和问题的表达方式。 图14. AMRNN的推理过程 AMRNN模型的推理过程明显受到了记忆网络的影响,图14通过摒除论文中与记忆网络不同的表面表述方式,抽象出了其推理过程,可以看出,其基本结构与记忆网络的Layer-Wise RNN模式是完全相同的,的区别是:记忆网络在拟合文档或者问题表示的时候是通过单词的Word Embedding简单叠加的方式,而AMRNN则是采用了RNN结构来推导文章和问题的表示。所以AMRNN模型可以近似理解为AS Reader的基础网络结构加上记忆网络的推理过程。 图15.GA Reader的推理过程 GA Reader的推理过程相对简洁,其示意图如图15所示。它的第一层网络推理过程如下:其每层推理网络的问题表达都是原始问题表达方式,在推理过程中不变。而f函数结合原始问题表达和文档表达来更新文档表达到新的形式,具体而言,f函数就是上文所述的被称为Gated-Attention模型的匹配函数,其计算过程为Di和Q两个向量对应维度数值逐位相乘,这样形成新的文档表达。其它层的推理过程与此相同。 图16. IA Reader的推理过程 IA Reader的推理结构相对复杂,其不同网络层是由RNN串接起来的,图16中展示了从第i层神经网络到第i+1层神经网络的推理过程,其中虚线部分是RNN的组织结构,每一层RNN结构是由新的文档表达和问题表达作为RNN的输入数据。其推理过程如下:对于第i层网络来说,首先根据RNN输入信息,就是第i层的文档表达和问题表达,更新隐层状态信息;然后f函数根据更新后的隐层状态信息以及原始的问题表达,计算问题中词汇的新的attention信息;g函数根据新的attention信息更新原始问题的表达形式,形成第i+1层网络的新的问题表达,g函数一般采取加权求和的计算方式;在获得了第i+1层新的问题表达后,t函数根据第i层RNN隐层神经元信息以及第i+1层网络新的问题表达形式,更新原始文档表达形成第i+1层文档的新表达形式。这样,第i+1层的问题表达和文档表达都获得了更新,完成了一次推理过程。后面的推理过程都遵循如此步骤来完成多步推理。 从上述推理机制可以看出,尽管不同模型都有差异,但是其中也有很多共性的部分。一种常见的推理策略往往是通过多轮迭代,不断更新注意力模型的注意焦点来更新问题和文档的Document Embedding表达方式,即通过注意力的不断转换来实现所谓的“推理过程”。 推理过程对于有一定难度的问题来说具有很明显的帮助作用,对于简单问题则作用不明显。当然,这与数据集难度有一定关系,比如研究证明(参考文献10),CNN数据集整体偏容易,所以正确回答问题不需要复杂的推理步骤也能做得很好。而在CBT数据集上,加上推理过程和不加推理过程进行效果对比,在评价指标上会增加2.5%到5%个百分点的提升。 2.4 其它模型 上文对目前主流的技术思路进行了归纳及抽象并进行了技术归类,除了上述的三种技术思路外,还有一些比较重要的工作在模型思路上不能归于上述分类中,本节对这些模型进行简述,具体模型主要包括EpiReader(参考文献11)和动态实体表示模型(Dynamic Entity Representation,后文简称DER模型,参考文献12)。 EpiReader是目前机器阅读理解模型中效果较好的模型之一,其思路相当于使用AS Reader的模型先提供若干候选答案,然后再对候选答案用假设检验的验证方式再次确认来获得正确答案。假设检验采用了将候选答案替换掉问题中的PlaceHolder占位符,即假设某个候选答案就是正确答案,形成完整的问题句子,然后通过判断问题句和文章中每个句子多大程度上是语义蕴含(Entailment)的关系来做综合判断,找出经过检验最合理的候选答案作为正确答案。这从技术思路上其实是采用了多模型融合的思路,本质上和多Reader进行模型Ensemble起到了异曲同工的作用,可以将其归为多模型Ensemble的集成方案,但是其假设检验过程模型相对复杂,而效果相比模型集成来说也不占优势,实际使用中其实不如直接采取某个模型Ensemble的方案更实用。 DER模型在阅读理解时,首先将文章中同一实体在文章中不同的出现位置标记出来,每个位置提取这一实体及其一定窗口大小对应的上下文内容,用双向RNN对这段信息进行编码,每个位置的包含这个实体的片段都编码完成后,根据这些编码信息与问题的相似性计算这个实体不同语言片段的Attention信息,并根据Attention信息综合出整篇文章中这个实体不同上下文的总的表示,然后根据这个表示和问题的语义相近程度选出最可能是答案的那个实体。DER模型尽管看上去和一维匹配模型差异很大,其实两者并没有本质区别,一维匹配模型在最后步骤相同单词的Attention概率合并过程其实和DER的做法是类似的。 3、问题与展望 用深度学习解决机器阅读理解问题探索历史时间并不长,经过最近一年的探索,应该说很多模型相对最初的技术方案来说,在性能提升方面进展明显,在很多数据集上性能都有大幅度的提高,甚至在一些数据集(bAbi,CNN,Daily Mail等)性能已经达到性能上限。但是总体而言,这距离让机器像人一样能够理解文本并回答问题还有非常遥远的距离。最后我们对这个研究领域目前面临的问题进行简述并对一些发展趋势进行展望。 1. 需要构建更具备难度的大规模阅读理解数据集 手工构建大规模的阅读理解训练数据需要花费极大成本,因此目前的不少数据集都存在一定问题。某些数据集比如MCTest经过人的精心构建,但是规模过小,很难用来有效训练复杂模型。另外一类是采用一定的启发规则自动构建的数据集,这类数据集数据规模可以做得足够大,但是很多数据集失之于太过简单。不少实验以及对应的数据分析结果证明常用的大规模数据集比如CNN和Daily Mail 相对简单,正确回答问题所需要的上下文很短(5个单词窗口大小范围)(参考文献3),只要采取相对简单的模型就可以达到较好的性能,复杂技术发挥不出优势,这从某种角度说明数据集难度偏小,这也极大限制了新技术的探索。 为了能够促进领域技术的进一步快速发展,需要一些大规模的人工构建的阅读理解数据集合,这样既能满足规模要求,又能具备相当难度。类似SQuAD数据集(参考文献13)这种采用众包的方式制作数据集合是个比较有前途的方向,也期待更多高质量的数据集尤其是更多中文数据集的出现(哈工大在16年7月份公布了第一份中文阅读理解数据集)。 2. 神经网络模型偏单一 从上述相关工作介绍可以看出,目前在机器阅读理解任务中,解决方案的神经网络结构还比较单一,后续需要探索更多种多样的新型网络结构及新式模型,以促进这个研究领域的快速发展。 3. 二维匹配模型需要做更深入的探索 二维匹配模型由于引入了更多的细节信息,所以在模型性能上具备一定优势。但是目前相关的工作还不多,而且大多集中在Attention机制的改造上。这个模型需要做更多的探索,比如匹配函数的创新、多层推理机制的引入等,我相信短期内在这块会有很多新技术会被提出。 4. 世界知识(World Knowledge)的引入 对于人来说,如果需要真正理解一篇新的文章,除了文章本身提供的上下文外,往往需要结合世界知识,也就是一些常识或者文章相关的背景知识,才能真正理解内容。目前机器阅读理解任务为了降低任务难度,往往将世界知识排除在任务之外,使得阅读理解任务更单纯,这在该领域研究初期毫无疑问是正确的思路,但是随着技术发展越来越完善,会逐渐引入世界知识来增强阅读理解任务的难度,也和人类的阅读理解过程越来越相似。 5. 发展更为完善的推理机制 在阅读一篇文章后,为了能够回答复杂的问题,设计合理的推理机制是阅读理解能力进行突破的关键技术,如上文所述,目前的推理机制大多数还是采用注意力焦点转移的机制来实现,随着复杂数据集的逐渐出现,推理机制会在阅读理解中起到越来越重要的作用,而今后需要提出更加丰富的推理机制。 参考文献 [1] Karl Moritz Hermann, Tomas Kocisky, Edward Grefenstette, Lasse Espeholt, Will Kay, Mustafa Suleyman,and Phil Blunsom. 2015. Teaching machines to read and comprehend. In Proc. of NIPS, pages 1684–1692. [2] Rudolf Kadlec, Martin Schmid, Ondrej Bajgar, andJan Kleindienst. 2016. Text understanding with the attention sum reader network. tarXiv:1603.01547. [3] Danqi Chen, Jason Bolton, and Christopher D. Manning.2016. A thorough examination of the cnn / daily mail reading comprehension task. In Proc. of ACL. [4] Bhuwan Dhingra, Hanxiao Liu, William W Cohen, and Ruslan Salakhutdinov. 2016. Gated-attention readers for text comprehension. arXiv preprint arXiv:1606.01549 [5] Bo-Hsiang Tseng, Sheng-Syun Shen, Hung-Yi Lee and Lin-Shan Lee,2016. Towards Machine Comprehension of Spoken Content:Initial TOEFL Listening Comprehension Test by Machine. arXiv preprint arXiv: 1608.06378 [6] Yiming Cui, Ting Liu, Zhipeng Chen, Shijin Wang, and Guoping Hu. 2016. Consensus attention-based neural networks for chinese reading comprehension. arXiv preprint arXiv:1607.02250. [7] Yiming Cui, Zhipeng Chen, Si Wei, Shijin Wang, Ting Liu and Guoping Hu.2016. Attention-over-Attention Neural Networks for Reading Comprehension. arXiv preprint arXiv: 1607.04423v3. [8] Shuohang Wang and Jing Jiang.2016. Machine Comprehension Using Match-LSTM and Answer Pointer. arXiv preprint arXiv: 1608.07905 [9] Sainbayar Sukhbaatar, Jason Weston, Rob Fergus, et al.2015. End-to-end memory networks. In Proc. of NIPS,pages 2431–2439. [10] Alessandro Sordoni, Phillip Bachman, and Yoshua Bengio. 2016. Iterative alternating neural attention for machine reading. arXiv preprint arXiv:1606.02245. [11] Adam Trischler, Zheng Ye, Xingdi Yuan, and Kaheer Suleman. 2016. Natural language comprehension with theepireader. arXiv preprint arXiv:1606.02270 [12] Sosuke Kobayashi, Ran Tian,Naoaki Okazaki, and Kentaro Inui. 2016. Dynamic entity representations with max-pooling improves machine reading. In NAACL-HLT. [13] Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. SQuAD: 100,000+ questionsfor machine comprehension of text. In Proceedings of the Conference on Empirical Methods inNatural Language Processing, 2016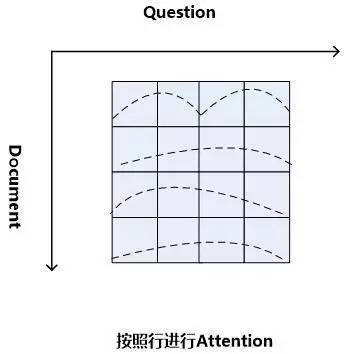
商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4419.html
摘要:本文着重以人脸识别为例介绍深度学习技术在其中的应用,以及优图团队经过近五年的积累对人脸识别技术乃至整个人工智能领域的一些认识和分享。从年左右,受深度学习在整个机器视觉领域迅猛发展的影响,人脸识别的深时代正式拉开序幕。 腾讯优图隶属于腾讯社交网络事业群(SNG),团队整体立足于腾讯社交网络大平台,专注于图像处理、模式识别、机器学习、数据挖掘、深度学习、音频语音分析等领域开展技术研发和业务落地。...
摘要:深度学习自动找到对分类重要的特征,而在机器学习,我们必须手工地给出这些特征。数据依赖深度学习和传统机器学习最重要的区别在于数据量增长下的表现差异。这是深度学习一个特别的部分,也是传统机器学习主要的步骤。 前言 机器学习和深度学习现在很火!突然间每个人都在讨论它们-不管大家明不明白它们的不同! 不管你是否积极紧贴数据分析,你都应该听说过它们。 正好展示给你要关注它们的点,这里...

阅读 896·2021-11-23 09:51
阅读 3839·2021-11-15 11:38
阅读 1329·2021-10-14 09:42
阅读 3574·2021-09-29 09:35
阅读 2528·2021-09-03 10:33
阅读 936·2021-07-30 16:33
阅读 1729·2019-08-30 15:55
阅读 2007·2019-08-30 14:04



