
摘要:导读工程师可用使用很多工具库来进行自然语言处理,比如等等,在这么多选择中,也许是所有人的推荐。版的终于发布了,它是世界上最快的自然语言处理库。在本文中,我们将使用,因为它是更受欢迎的深度学习库。
导读:工程师可用使用很多工具库来进行自然语言处理,比如 NLTK/CoreNLP/OpenNLP/Rosette/OpenIE 等等,在这么多选择中,spaCy 也许是所有人的推荐。
1.0 版的 spaCy 终于发布了,它是世界上最快的自然语言处理 NLP 库。 到目前为止,1.0 版的较好的特性是将定制化的模型集成到 spaCy 新系统中。 本文将向您介绍这些新特性,并向您展示如何使用新的自定义管道功能将 Keras 提供的 LSTM 情感分析模型添加到 spaCy 管道中。
之前的 spaCy 用户调查已经收到了很多对程序库的反馈。 最显而易见的是 spaCy 需要更多教程文档。 我们目前正在为该网站制作一个新的并改进的教程。 同时优先考虑新的 1.0 功能的教程,比如新的规则,实体感知匹配器,模型训练 API 和自定义管道。
自定义管道是特别令人兴奋的,因为他们你整合自己的深度学习模型进 spaCy。 所以,这里将说明如何使用 Keras 来训练 LSTM 情感分析模型,怎样使用 spaCy 的结果的注解。
如何在 spacy 中使用 Keras LSTM 模型来进行情感分析
有许多伟大的开源库用于研究,训练和评估神经网络。然而,这些库关注的问题通常止步于评估得分和模型文件。spaCy 一直被设计为协调多个文本注释模型,并帮助您在应用程序中一起使用它们。 spaCy 1.0 现在使用自己的自定义模型更容易计算这些注释。
在本文中,我们将使用 Keras,因为它是 Python 更受欢迎的深度学习库。让我们假设你写了一个自定义情感分析模型来预测文档是正面还是负面情绪。现在,您想要找到哪些实体通常与正面情绪文档或负面情绪文档相关联。这里有一个快速示例,可以看到运行时。

你需要做的是传递一个create_pipeline 回调函数到 spacy.load()。 该函数应该使用 spacy.language.Language 对象作为其的参数,并返回一系列可调用对象。 每个可调用对象都应该接受一个 Doc 对象,对其进行修改,并返回None。
对单个文档的操作是低效的,特别是对于深度学习模型。通常我们要注释许多文本,并且我们想要并行处理它们。因此,您应该确保模型组件还支持.pipe()方法。.pipe()方法应该是一个良好的生成器函数,可以对任意大的序列进行操作。 pipe函数使用小文档缓冲区,并行处理它们,并一个一个地产生它们。

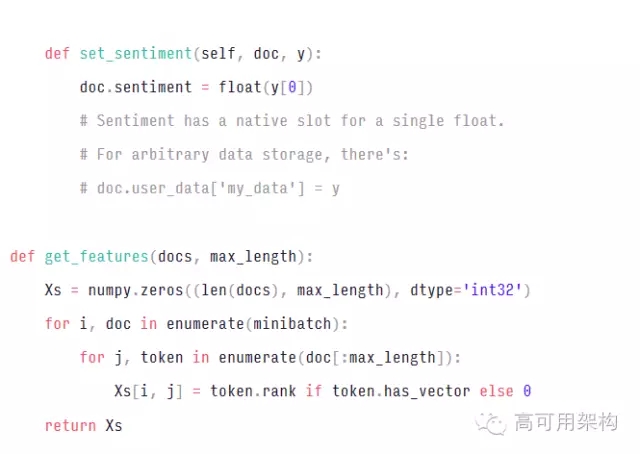
默认情况下,spaCy 1.0下载并使用 300 维 GloVe(Global Vectors for Word Representation 词表达全局向量)common crawl 向量。 也很容易用你自己训练的向量替换这些向量,或者完全禁用词向量(word vectors)。 如果你已经将你的词向量安装到 spaCy 的 Vocab 对象中,下面介绍如何在 Keras 模型中使用它们:

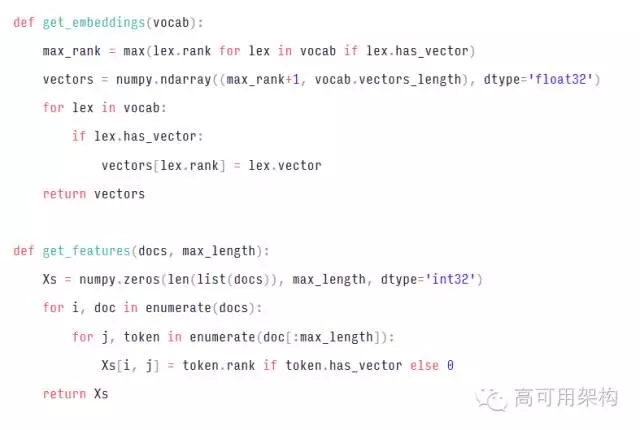
对于大多数应用程序,我建议使用预先训练的词嵌入(word embeddings,给出一个文档,文档就是一个单词序列比如 “A B A C B F G”, 希望对文档中每个不同的单词都得到一个对应的向量(往往是低维向量)表示)而不进行“微调”。 这意味着您将在不同的模型中使用相同的embeddings,并避免learning过程对您的训练数据进行调整。embeddings 表是大表,并且由预训练向量提供的值已经相当好。因此,微调嵌入表是浪费您的“参数预算”。通常较好使用其他方式扩大您的网络,例如通过添加另一个 LSTM 层,使用注意机制,使用字符特征等。
属性钩子(实验性质)
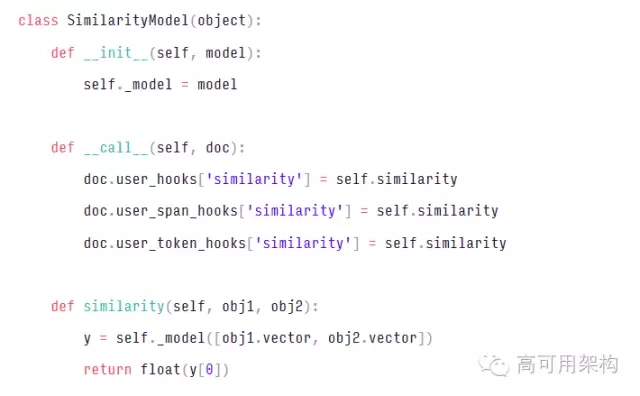
早些时候,我们看到了如何在新的通用user_data dict中存储数据。这可以接受,但不令人满意。理想情况下,我们希望让自定义数据驱动更多的“本地”行为。例如,考虑由spaCy的Doc,Token和Span对象提供的.similarity()方法:

默认情况下,这只是平均每个文档的向量,并计算其余弦。一般说来,spaCy 使你很容易安装自己的相似模型。这引入了棘手的设计挑战。当前的解决方案是向 Doc 对象添加三个 diction:

总而言之,这里是一个在自定义 .similarity() 方法中挂钩的例子:
下一步
属性钩子很可能会略微演变,并且肯定需要一些调整来达到完全一致。我也期待为标记器,解析器和实体识别器改进模型。在过去的十二个月中,研究表明,双向 LSTM 模型是这些任务的简单和有效的方法。结果模型耗费的内存也明显更小。
参考代码:
https://github.com/explosion/spaCy/blob/master/examples/deep_learning_keras.py
英文原文:
https://explosion.ai/blog/spacy-deep-learning-keras
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4432.html
摘要:在本节中,我们将看到一些最流行和最常用的库,用于机器学习和深度学习是用于数据挖掘,分析和机器学习的最流行的库。愿码提示网址是一个基于的框架,用于使用多个或进行有效的机器学习和深度学习。 showImg(https://segmentfault.com/img/remote/1460000018961827?w=999&h=562); 来源 | 愿码(ChainDesk.CN)内容编辑...
摘要:问深度学习社区现在面临的主要挑战是什么答打击炒作发展伦理意识获得科学严谨性。深度学习简直是科学的重灾区。 Keras之父、谷歌大脑人工智能和深度学习研究员François Chollet撰写了一本深度学习Python教程实战书籍《Python深度学习》,书中介绍了深度学习使用Python语言和强大Keras库,详实新颖。近日,François Chollet接受了采访,就深度学习到底是什么、...
摘要:我们对种用于数据科学的开源深度学习库作了排名。于年月发布了第名,已经跻身于深度学习库的上半部分。是最流行的深度学习前端第位是排名较高的非框架库。颇受对数据集使用深度学习的数据科学家的青睐。深度学习库的完整列表来自几个来源。 我们对23种用于数据科学的开源深度学习库作了排名。这番排名基于权重一样大小的三个指标:Github上的活动、Stack Overflow上的活动以及谷歌搜索结果。排名结果...
摘要:是你学习从入门到专家必备的学习路线和优质学习资源。的数学基础最主要是高等数学线性代数概率论与数理统计三门课程,这三门课程是本科必修的。其作为机器学习的入门和进阶资料非常适合。书籍介绍深度学习通常又被称为花书,深度学习领域最经典的畅销书。 showImg(https://segmentfault.com/img/remote/1460000019011569); 【导读】本文由知名开源平...

阅读 3835·2021-10-13 09:40
阅读 3292·2021-10-09 09:53
阅读 3672·2021-09-26 09:46
阅读 1981·2021-09-08 09:36
阅读 4408·2021-09-02 09:46
阅读 1389·2019-08-30 15:54
阅读 3261·2019-08-30 15:44
阅读 1107·2019-08-30 11:06





