
摘要:年月日,机器之心曾经推出文章为你的深度学习任务挑选最合适从性能到价格的全方位指南。如果你想要学习深度学习,这也具有心理上的重要性。如果你想快速学习深度学习,多个廉价的也很好。目前还没有适合显卡的深度学习库所以,只能选择英伟达了。
文章作者 Tim Dettmers 系瑞士卢加诺大学信息学硕士,热衷于开发自己的 GPU 集群和算法来加速深度学习。这篇博文最早版本发布于 2014 年 8 月,之后随着相关技术的发展和硬件的更新,Dettmers 也在不断对本文进行修正。2016 年 7 月 18 日,机器之心曾经推出文章为你的深度学习任务挑选最合适 GPU:从性能到价格的全方位指南 。当时,机器之心呈现的文章是其 2016 年 6 月 25 日的更新(之前已经有五次更新)。接着,2016 年 7 月 23 日以及 2017 年 3 月 19 日,作者又分别根据硬件发展情况两度更新博文:2016 年 7 月 23 日主要添加了 Titan X Pascal 以及 GTX 1060 并更新了相应推荐;2017 年 3 月 19 日添加了 GTX 1080 Ti 并对博客进行了较大调整。本文依据的是 3 月 19 日更新后的版本。另外,除了 GPU 之外,深度学习还需要其它一些硬件基础,详情可参阅机器之心之前的文章《深度 | 史上最全面的深度学习硬件指南》。
深度学习是一个计算密集型领域,而 GPU 的选择将从根本上决定你的深度学习实验。没有 GPU,一个实验也许花费数月才能完成,或者实验运行一天却只关闭了被选择的参数;而一个良好稳定的 GPU 可让你在深度学习网络中快速迭代,在数天、数小时、数分钟内完成实验,而不是数月、数天、数小时。所以,购买 GPU 时正确的选择很关键。那么,如何选择一个适合你的 GPU 呢?这正是本篇博文探讨的问题,帮助你做出正确选择。
对于深度学习初学者来说,拥有一个快速 GPU 非常重要,因为它可以使你迅速获得有助于构建专业知识的实践经验,这些专业知识可以帮助你将深度学习应用到新问题上。没有这种迅速反馈,从错误中汲取经验将会花费太多时间,在继续深度学习过程中也会感到受挫和沮丧。在 GPU 的帮助下,我很快就学会了如何在一系列 Kaggle 竞赛中应用深度学习,并且在 Partly Sunny with a Chance of Hashtags Kaggle 竞赛上获得了第二名,竞赛内容是通过一个给定推文预测气象评分。比赛中,我使用了一个相当大的两层深度神经网络(带有两个修正线性单元和 dropout,用于正则化),差点就没办法把这个深度网络塞进我的 6G GPU 内存。
应该使用多个 GPU 吗?
在 GPU 的帮助下,深度学习可以完成很多事情,这让我感到兴奋。我投身到多 GPU 的领域之中,用 InfiniBand 40Gbit/s 互连组装了小型 GPU 集群。我疯狂地想要知道多个 GPU 能否获得更好的结果。我很快发现,不仅很难在多个 GPU 上并行神经网络。而且对普通的密集神经网络来说,加速效果也很一般。小型神经网络可以并行并且有效地利用数据并行性,但对于大一点的神经网络来说,例如我在 Partly Sunny with a Chance of Hashtags Kaggle 比赛中使用的,几乎没有加速效果。
随后,我进一步试验,对比 32 位方法,我开发了带有模型并行性的新型 8 位压缩技术,该技术能更有效地并行处理密集或全连接神经网络层。
然而,我也发现,并行化也会让人沮丧得发狂。针对一系列问题,我天真地优化了并行算法,结果发现:考虑到你投入的精力,即使使用优化过的自定义代码,多个 GPU 上的并行注意的效果也并不好。你需要非常留意你的硬件及其与深度学习算法交互的方式,这样你一开始就能衡量你是否可以受益于并行化。

我的计算机主机设置:你可以看到 3 个 GXT Titan 和一个 InfiniBand 卡。对于深度学习来说,这是一个好的设置吗?
自那时起,GPU 的并行性支持越来越普遍,但距离全面可用和有效还差的很远。目前,在 GPU 和计算机中实现有效算法的深度学习库是 CNTK,它使用微软的 1 比特量子化(有效)和 block momentum(很有效)的特殊并行化算法。通过 CNTK 和一个包含 96 块 GPU 的聚类,你可以拥有一个大约 90x-95x 的新线性速度。Pytorch 也许是跨机器支持有效并行化的库,但是,库目前还不存在。如果你想要在一台机器上做并行,那么,CNTK、Torch 和 Pytorch 是你的主要选择,这些库具备良好的加速(3.6x-3.8x),并在一台包含 4 至 8 块 GPU 的机器之中预定义了并行化算法。也有其他支持并行化的库,但它们不是慢(比如 2x-3x 的 TensorFlow)就是难于用于多 GPU (Theano),或者兼而有之。
如果你重视并行,我建议你使用 Pytorch 或 CNTK。
使用多 GPU 而无并行
使用多 GPU 的另外一个好处是:即使没有并行算法,你也可以分别在每个 GPU 上运行多个算法或实验。速度没有变快,但是你能一次性通过使用不同算法或参数得到更多关于性能信息。如果你的主要目标是尽快获得深度学习经验,这是非常有用的,而且对于想同时尝试新算法不同版本的研究人员来说,这也非常有用。
如果你想要学习深度学习,这也具有心理上的重要性。执行任务的间隔以及得到反馈信息的时间越短,大脑越能将相关记忆片段整合成连贯画面。如果你在小数据集上使用独立的 GPU 训练两个卷积网络,你就能更快地知道什么对于性能优良来说是重要的;你将更容易地检测到交叉验证误差中的模式并正确地解释它们。你也会发现暗示需要添加、移除或调整哪些参数与层的模式。
所以总体而言,几乎对于所有任务来说,一个 GPU 已经足够了,但是加速深度学习模型,多个 GPU 会变得越来越重要。如果你想快速学习深度学习,多个廉价的 GPU 也很好。我个人宁愿使用多个小的 GPU,而不是一个大的 GPU,即使是出于研究实验的没目的。
那么,我该选择哪类加速器呢?英伟达 GPU、AMD GUP 还是英特尔的 Xeon Phi?
英伟达的标准库使得在 CUDA 中建立第一个深度学习库很容易,但没有适合 AMD 的 OpenCL 那样强大的标准库。目前还没有适合 AMD 显卡的深度学习库——所以,只能选择英伟达了。即使未来一些 OpenCL 库可用,我仍会坚持使用英伟达:因为对于 CUDA 来说,GPU 计算或者 GPGPU 社区是很大的,对于 OpenCL 来说,则相对较小。因此,在 CUDA 社区,有现成的好的开源解决方案和为编程提供可靠建议。
此外,英伟达现在为深度学习赌上一切,即使深度学习还只是处于婴儿期。押注获得了回报。尽管现在其他公司也往深度学习投入了钱和精力,但由于开始的晚,目前依然很落后。目前,除了 NVIDIA-CUDA,其他任何用于深度学习的软硬结合的选择都会让你受挫。
至于英特尔的 Xeon Phi,广告宣称你能够使用标准 C 代码,还能将代码轻松转换成加速过的 Xeon Phi 代码。听起来很有趣,因为你可能认为可以依靠庞大的 C 代码资源。但事实上,其只支持非常一小部分 C 代码,因此,这一功能并不真正有用,大部分 C 运行起来会很慢。
我曾研究过 500 多个 Xeon Phi 集群,遭遇了无止尽的挫折。我不能运行我的单元测试(unit test),因为 Xeon Phi 的 MKL(数学核心函数库)并不兼容 NumPy;我不得不重写大部分代码,因为英特尔 Xeon Phi 编译器无法让模板做出适当约简。例如,switch 语句,我不得不改变我的 C 接口,因为英特尔 Xeon Phi 编译器不支持 C++ 11 的一些特性。这一切迫使你在没有单元测试的情况下来执行代码的重构,实在让人沮丧。这花了很长时间。真是地狱啊。
随后,执行我的代码时,一切都运行得很慢。是有 bug(?)或者仅仅是线程调度器(thread scheduler)里的问题?如果作为运行基础的向量大小连续变化,哪个问题会影响性能表现?比如,如果你有大小不同的全连接层,或者 dropout 层,Xeon Phi 会比 CPU 还慢。我在一个独立的矩阵乘法(matrix-matrix multiplication)实例中复制了这一行为,并把它发给了英特尔,但从没收到回信。所以,如果你想做深度学习,远离 Xeon Phi!
给定预算下的最快 GPU
你的第一个问题也许是:用于深度学习的快速 GPU 性能的最重要特征是什么?是 cuda 内核、时钟速度还是 RAM 的大小?
以上都不是。最重要的特征是内存带宽。
简言之,GPU 通过牺牲内存访问时间(延迟)而优化了内存带宽; 而 CPU 的设计恰恰相反。如果只占用了少量内存,例如几个数相乘(3*6*9),CPU 可以做快速计算,但是,对于像矩阵相乘(A*B*C)这样占用大量内存的操作,CPU 运行很慢。由于其内存带宽,GPU 擅长处理占用大量内存的问题。当然 GPU 和 CPU 之间还存在其他更复杂的差异。
如果你想购买一个快速 GPU,第一等重要的就是看看它的带宽。
根据内存带宽评估 GPU
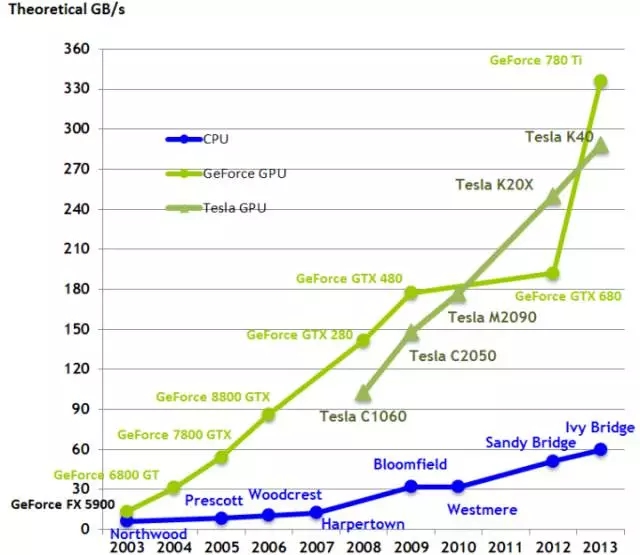
随着时间的推移,比较 CPU 以及 GPU 的带宽。为什么 GPU 计算速度会比 CPU 快?主要原因之一就是带宽。
带宽可直接在一个架构内进行比较,例如, 比较 Pascal 显卡 GTX 1080 与 GTX 1070 的性能;也可通过只查看其内存带宽而直接比较。例如,GTX 1080 (320GB/s) 大约比 GTX 1070 (256 GB/s) 快 25%。然而, 在多个架构之间,例如 Pascal 对于 Maxwell 就像 GTX 1080 对于 GTX Titan X 一样,不能进行直接比较,因为加工过程不同的架构使用了不同的给定内存带宽。这一切看起来有点狡猾,但是,只看总带宽就可对 GPU 的大致速度有一个很好的全局了解。在给定预算的情况下选择一块最快的 GPU,你可以使用这一维基百科页面(List of Nvidia graphics processing units),查看 GB/s 中的带宽;对于更新的显卡(900 和 1000 系列)来说,列表中的价格相当较精确,但是,老旧的显卡相比于列举的价格会便宜很多,尤其是在 eBay 上购买这些显卡时。例如,一个普通的 GTX Titan X 在 eBay 上的价格大约是 550 美元。
然而,另一个需要考虑的重要因素是,并非所有架构都与 cuDNN 兼容。由于几乎所有的深度学习库都使用 cuDNN 做卷积运算,这就限制了对于 Kepler GPU 或更好 GPU 的选择,即 GTX 600 系列或以上版本。最主要的是 Kepler GPU 通常会很慢。因此这意味着你应该选择 900 或 1000 系列 GPU 来获得好的性能。
为了大致搞清楚深度学习任务中的显卡性能比较情况,我创建了一个简单的 GPU 等价表。如何阅读它呢?例如,GTX 980 的速度相当于 0.35 个 Titan X Pascal,或是 Titan X Pascal 的速度几乎三倍快于 GTX 980。
请注意我没有所有这些显卡,也没有在所有这些显卡上跑过深度学习基准。这些对比源于显卡规格以及计算基准(有些加密货币挖掘任务需要比肩深度学习的计算能力)的比较。因此只是粗略的比较。真实数字会有点区别,但是一般说来,误差会是最小的,显卡的排序也没问题。
也请注意,没有充分利用 GPU 的小型网络会让更大 GPU 看起来不那么帅。比如,一个 GTX 1080 Ti 上的小型 LSTM(128 个隐藏单元;batch 大小大于 64)不会比在 GTX 1070 上运行速度明显快很多。为了实现表格中的性能差异,你需要运行更大的网络,比如 带有 1024 个隐藏单元(而且 batch 大小大于 64)的 LSTM。当选择适合自己的 GPU 时,记住这一点很重要。
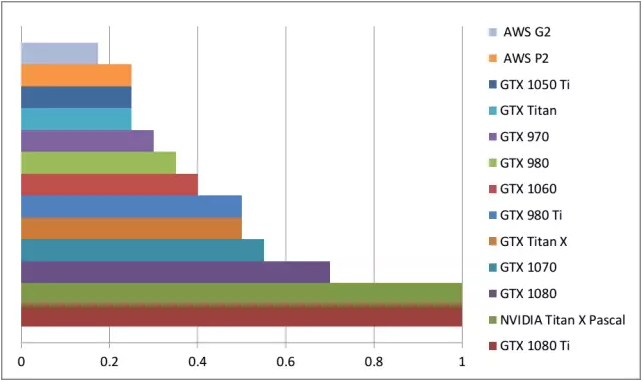
粗略的比较用于大型深度学习网络 的 GPU 性能。
总的来说,我会推荐 GTX 1080 Ti 或者 GTX 1070。它们都是优秀的显卡,如果你有钱买得起 GTX 1080 Ti 那么就入手吧。GTX 1070 更加便宜点,但是仍然比普通的 GTX Titan X (Maxwell) 要快一些。较之 GTX 980 Ti,这两者都是更佳选择,考虑到增加的 11 G 以及 8G 的内存(而不是 6G)。
8G 的内存看起来有点小,但是对于许多任务来说,绰绰有余。比如,Kaggle 比赛,很多图像数据集、深度风格以及自然语言理解任务上,你遇到的麻烦会少很多。
GTX 1060 是较好的入门 GPU,如果你是首次尝试深度学习或者有时想要使用它来参加 Kaggle 比赛。我不会推荐 GTX 1060 带有 3G 内存的变体产品,既然其他 6G 内存产品的能力已经十分有限了。不过,对于很多应用来说,6G 内存足够了。GTX 1060 要比普通版本的 Titan X 慢一些,但是,在性能和价格方面(eBay 上)都可比肩 GTX980。
如果要说物有所值呢,10 系列设计真的很赞。GTX 1060、GTX 1070 和 GTX 1080 Ti 上都很出色。GTX 1060 适合初学者,GTX 1070 是某些产业和研究部门以及创业公司的好选择,GTX 1080 Ti 通杀高端选择。
一般说来,我不会推荐英伟达 Titan X (Pascal),就其性能而言,价格死贵了。继续使用 GTX 1080 Ti 吧。不过,英伟达 Titan X (Pascal) 在计算机视觉研究人员当中,还是有它的地位的,这些研究人员通常要研究大型数据集或者视频集。在这些领域里,每 1G 内存都不会浪费,英伟达 Titan X 比 GTX 1080 Ti 多 1G 的内存也会带来更多的处理优势。不过,就物有所值而言,这里推荐 eBay 上的 GTX Titan X(Maxwell)——有点慢,不过 12G 的内存哦。
不过,绝大多数研究人员使用 GTX 1080 Ti 就可以了。对于绝大多数研究和应用来说,额外 1G 内存其实是不必要的。
我个人会使用多个 GTX 1070 进行研究。我宁可多跑几个测试,哪怕速度比仅跑一个测试(这样速度会快些)慢一些。在自然语言处理任务中,内存限制并不像计算机视觉研究中那么明显。因此,GTX 1070 就够用了。我的研究任务以及运行实验的方式决定了最适合我的选择就是 GTX 1070。
当你挑选自己的 GPU 时,也应该如法炮制,进行甄选。考虑你的任务以及运行实验的方式,然后找个满足所有这些需求的 GPU。
现在,对于那些手头很紧又要买 GPU 的人来说,选择更少了。AWS 的 GPU 实例很贵而且现在也慢,不再是一个好的选择,如果你的预算很少的话。我不推荐 GTX 970,因为速度慢还死贵,即使在 eBay 上入二手(150 刀),而且还有存储及显卡启动问题。相反,多弄点钱买一个 GTX 1060,速度会快得多,存储也更大,还没有这方面的问题。如果你只是买不起 GTX 1060,我推荐 4GB RAM 的 GTX 1050 Ti。4GB 会有限,但是你可以玩转深度学习了,如果你调一下模型,就能获得良好的性能。GTX 1050 适合绝大多数 kaggle 竞赛,尽管可能会在一些比赛中限制你的竞争力。
亚马逊网络服务(AWS)中的 GPU 实例
在这篇博文的前一个版本中,我推荐了 AWS GPU 的现货实例,但现在我不会再推荐它了。目前 AWS 上的 GPU 相当慢(一个 GTX 1080 的速度是 AWS GPU 的 4 倍)并且其价格在过去的几个月里急剧上升。现在看起来购买自己的 GPU 又似乎更为明智了。
总结
运用这篇文章里的所有信息,你应该能通过平衡内存大小的需要、带宽速度 GB/s 以及 GPU 的价格来找到合适的 GPU 了,这些推理在未来许多年中都会是可靠的。但是,现在我所推荐的是 GTX 1080 Ti 或 GTX 1070,只要价格可以接受就行;如果你刚开始涉足深度学习或者手头紧,那么 GTX 1060 或许适合你。如果你的钱不多,就买 GTX 1050 Ti 吧;如果你是一位计算机视觉研究人员,或许该入手 Titan X Pascal(或者就用现有的 GTX Titan Xs)。
总结性建议
总的说来较好的 GPU:Titan X Pascal 以及 GTX 1080 Ti
有成本效益但价格高的:GTX 1080 Ti, GTX 1070
有成本效益而且便宜:GTX 1060
用来处理大于 250G 数据集:常规 GTX Titan X 或者 Titan X Pascal
我钱不多:GTX 1060
我几乎没钱:GTX 1050 Ti
我参加 Kaggle 比赛: 用于任何常规比赛,GTX 1060 , 如果是深度学习比赛,GTX 1080Ti
我是一名有竞争力的计算机视觉研究人员: Titan X Pascal 或常规 GTX Titan X
我是一名研究人员:GTX 1080 Ti. 有些情况下,比如自然语言处理任务,GTX 1070 或许是可靠的选择——看一下你当前模型的存储要求。
想建立一个 GPU 集群:这真的很复杂,你可以从这里得到一些思路:https://timdettmers.wordpress.com/2014/09/21/how-to-build-and-use-a-multi-gpu-system-for-deep-learning/
我刚开始进行深度学习,并且我是认真的:开始用 GTX 1060。根据你下一步的情况(创业?Kaggle 比赛?研究还是应用深度学习)卖掉你的 GTX 1060 然后买更适合使用目的的。
原文地址:http://timdettmers.com/2017/03/19/which-gpu-for-deep-learning/
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4488.html
摘要:文章翻译自深度学习是一个计算需求强烈的领域,的选择将从根本上决定你的深度学习研究过程体验。因此,今天就谈谈如何选择一款合适的来进行深度学习的研究。此外,即使深度学习刚刚起步,仍然在持续深入的发展。例如,一个普通的在上的售价约为美元。 文章翻译自:Which GPU(s) to Get for Deep Learning(http://t.cn/R6sZh27)深度学习是一个计算需求强烈的领域...
摘要:很明显这台机器受到了英伟达的部分启发至少机箱是这样,但价格差不多只有的一半。这篇个文章将帮助你安装英伟达驱动,以及我青睐的一些深度学习工具与库。 本文作者 Roelof Pieters 是瑞典皇家理工学院 Institute of Technology & Consultant for Graph-Technologies 研究深度学习的一位在读博士,他同时也运营着自己的面向客户的深度学习产...
摘要:幸运的是,这些正是深度学习所需的计算类型。几乎可以肯定,英伟达是目前执行深度学习任务较好的选择。今年夏天,发布了平台提供深度学习支持。该工具适用于主流深度学习库如和。因为的简洁和强大的软件包扩展体系,它目前是深度学习中最常见的语言。 深度学习初学者经常会问到这些问题:开发深度学习系统,我们需要什么样的计算机?为什么绝大多数人会推荐英伟达 GPU?对于初学者而言哪种深度学习框架是较好的?如何将...
摘要:在两个平台三个平台下,比较这五个深度学习库在三类流行深度神经网络上的性能表现。深度学习的成功,归因于许多层人工神经元对输入数据的高表征能力。在年月,官方报道了一个基准性能测试结果,针对一个层全连接神经网络,与和对比,速度要快上倍。 在2016年推出深度学习工具评测的褚晓文团队,赶在猴年最后一天,在arXiv.org上发布了的评测版本。这份评测的初版,通过国内AI自媒体的传播,在国内业界影响很...
摘要:在本节中,我们将看到一些最流行和最常用的库,用于机器学习和深度学习是用于数据挖掘,分析和机器学习的最流行的库。愿码提示网址是一个基于的框架,用于使用多个或进行有效的机器学习和深度学习。 showImg(https://segmentfault.com/img/remote/1460000018961827?w=999&h=562); 来源 | 愿码(ChainDesk.CN)内容编辑...
阅读 1579·2021-09-26 09:55
阅读 2091·2019-08-30 12:45
阅读 1257·2019-08-29 11:20
阅读 3706·2019-08-26 11:33
阅读 3602·2019-08-26 10:55
阅读 1849·2019-08-23 17:54
阅读 2560·2019-08-23 15:55
阅读 2497·2019-08-23 14:23






