
摘要:它使用机器学习来解释用户提出的问题,并用相应的知识库文章来回应。使用一类目前较先进的机器学习算法来识别相关文章,也就是深度学习。接下来介绍一下我们在生产环境中配置模型的一些经验。
我们如何开始使用TensorFlow
在Zendesk,我们开发了一系列机器学习产品,比如的自动答案(Automatic Answers)。它使用机器学习来解释用户提出的问题,并用相应的知识库文章来回应。当用户有问题、投诉或者查询时,他们可以在线提交请求。收到他们的请求后,Automatic Answers将分析请求,并且通过邮件建议客户阅读相关的可能最有帮助的文章。
Automatic Answers使用一类目前较先进的机器学习算法来识别相关文章,也就是深度学习。 我们使用Google的开源深度学习库TensorFlow来构建这些模型,利用图形处理单元(GPU)来加速这个过程。Automatic Answers是我们在Zendesk使用Tensorflow完成的第一个数据产品。在我们的数据科学家付出无数汗水和心血之后,我们才有了在Automatic Answers上效果非常好的Tensorflow模型。
但是构建模型只是问题的一部分,我们的下一个挑战是要找到一种方法,使得模型可以在生产环境下服务。模型服务系统将经受大量的业务。所以需要确保为这些模型提供的软件和硬件基础架构是可扩展的、可靠的和容错的,这对我们来说是非常重要的。接下来介绍一下我们在生产环境中配置TensorFlow模型的一些经验。
顺便说一下我们的团队——Zendesk的机器学习数据团队。我们团队包括一群数据科学家、数据工程师、一位产品经理、UX /产品设计师以及一名测试工程师。

Data Team At Zendesk Melbourne
TensorFlow模型服务
经过数据科学家和数据工程师之间一系列的讨论,我们明确了一些核心需求:
预测时的低延迟
横向可扩展
适合我们的微服务架构
可以使用A/B测试不同版本的模型
可以与更新版本的TensorFlow兼容
支持其他TensorFlow模型,以支持未来的数据产品
TensorFlow Serving
经过网上的调研之后,Google的TensorFlow Serving成为我们推荐的模型服务。TensorFlow Serving用C++编写,支持机器学习模型服务。开箱即用的TensorFlow Serving安装支持:
TensorFlow模型的服务
从本地文件系统扫描和加载TensorFlow模型
(小编注:TensorFlow和TensorFlow Serving的区别:TensorFlow项目主要是基于各种机器学习算法构建模型,并为某些特定类型的数据输入做适应学习,而TensorFlow Serving则专注于让这些模型能够加入到产品环境中。开发者使用TensorFlow构建模型,然后TensorFlow Serving基于客户端输入的数据使用前面TensorFlow训练好的模型进行预测。)
TensorFlow Serving将每个模型视为可服务对象。它定期扫描本地文件系统,根据文件系统的状态和模型版本控制策略来加载和卸载模型。这使得可以在TensorFlow Serving继续运行的情况下,通过将导出的模型复制到指定的文件路径,而轻松地热部署经过训练的模型。
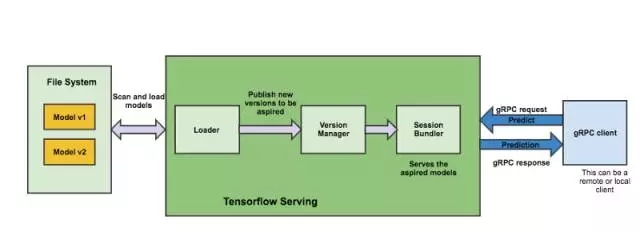
TensorFlow Serving Architecture
根据这篇Google博客中报告的基准测试结果,他们每秒记录大约100000个查询,其中不包括TensorFlow预测处理时间和网络请求时间。
有关TensorFlow Serving架构的更多信息,请参阅TensorFlow Serving文档。
通信协议(gRPC)
TensorFlow Serving提供了用于从模型调用预测的gRPC接口。gRPC是一个开源的高性能远程过程调用(remote procedure call,RPC)框架,它在HTTP/2上运行。与HTTP/1.1相比,HTTP/2包含一些有趣的增强,比如它对请求复用、双向流和通过二进制传输的支持,而不是文本。
默认情况下,gRPC使用Protocol Buffers (Protobuf)作为其信息交换格式。Protocol Buffers是Google的开源项目,用于在高效的二进制格式下序列化结构化数据。它是强类型,这使它不容易出错。数据结构在.proto文件中指定,然后可以以各种语言(包括Python,Java和C ++)将其编译为gRPC请求类。 这是我第一次使用gRPC,我很想知道它与其他API架构(如REST)相比谁性能更好。
模型训练和服务架构
我们决定将深度学习模型的训练和服务分为两个管道。下图是我们的模型训练和服务架构的概述:
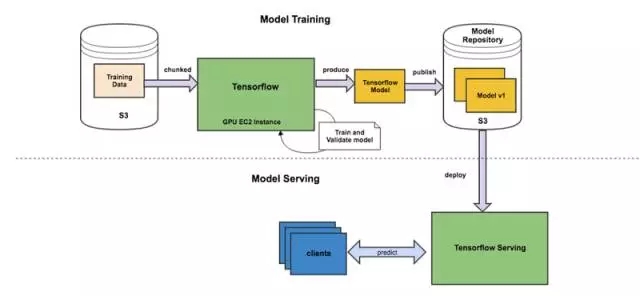
Model Training and Serving Architecture
模型训练管道
模型训练步骤:
我们的训练特征是从Hadoop中提供的数据生成的。
生成的训练特征保存在AWS S3中。
然后使用AWS中的GPU实例和S3中的批量训练样本训练TensorFlow模型。
一旦模型被构建并验证通过,它将被发布到S3中的模型存储库。
模型服务管道
验证的模型在生产中通过将模型从模型库传送到TensorFlow Serving实例来提供。
基础结构
我们在AWS EC2实例上运行TensorFlow Serving。Consul在实例之前设置,用于服务发现和分发流量。客户端连接从DNS查找返回的第一个可用IP。或者弹性负载平衡可用于更高级的负载平衡。由于TensorFlow模型的预测本质上是无状态操作,所以我们可以通过旋转加速更多的EC2实例 来实现横向可扩展性。
另一个选择是使用Google Cloud平台提供的Cloud ML,它提供TensorFlow Serving作为完全托管服务。 但是,当我们在大概2016年9月推出TensorFlow Serving时,Cloud ML服务处于alpha阶段,缺少生产使用所需的功能。因此,我们选择在我们自己的AWS EC2实例中托管,以实现更精细的粒度控制和可预测的资源容量。
模型服务的实现
下面是我们实现TensorFlow Serving部署和运行所采取的步骤:
1.从源编译TensorFlow Serving
首先,我们需要编译源代码来产生可执行的二进制文件。然后就可以从命令行执行二进制文件来启动服务系统。
假设你已经配置好了Docker,那么一个好的开端就是使用提供的Dockerfile来编译二进制文件。请按照以下步骤:
运行该gist中的代码以构建适合编译TensorFlow Serving的docker容器。
在正在运行的docker容器中运行该gist中的代码以构建可执行二进制文件。
一旦编译完成,可执行二进制文件将在你的docker镜像的以下路径中:/work/serving/bazel-bin/tensorflow_serving/model_servers/tensorflow_model_server
2.运行模型服务系统
上一步生成的可执行二进制文件(tensorflow_model_server)可以部署到您的生产实例中。 如果您使用docker编排框架(如Kubernetes或Elastic Container Service),您还可以在docker容器中运行TensorFlow Serving。
现在假设TensorFlow模型存储在目录/work/awesome_model_directory下的生产主机上。你可以在端口8999上使用以下命令来运行TensorFlow Serving和你的TensorFlow模型:
默认情况下,TensorFlow Serving会每秒扫描模型基本路径,并且可以自定义。此处列出了可作为命令行参数的可选配置。
3.从服务定义(Service Definitions)生成Python gRPC存根
下一步是创建可以在模型服务器上进行预测的gRPC客户端。这可以通过编译.proto文件中的服务定义,从而生成服务器和客户端存根来实现。.proto文件在TensorFlow Serving源码中的tensorflow_serving_apis文件夹中。在docker容器中运行以下脚本来编译.proto文件。运行提交版本号为46915c6的脚本的示例:
./compile_ts_serving_proto.sh 46915c6
运行该脚本后应该在tensorflow_serving_apis目录下生成以下定义文件:
model_pb2.py
predict_pb2.py
prediction_service_pb2.py
你还可以使用grpc_tools Python工具包来编译.proto文件。
4.从远程主机调用服务
可以使用编译后的定义来创建一个python客户端,用来调用服务器上的gRPC调用。比如这个例子用一个同步调用TensorFlow Serving的Python客户端。
如果您的用例支持异步调用预测,TensorFlow Serving还支持批处理预测以达到性能优化的目的。要启用此功能,你应该运行tensorflow_model_server同时开启flag —enable_batching。这是一个异步客户端的例子。
从其他存储加载模型
如果你的模型没有存储在本地系统中应该怎么办?你可能希望TensorFlow Serving可以直接从外部存储系统(比如AWS S3和Google Storage)中直接读取。
如果是这种情况,你将需要通过Custom Source来拓展TensorFlow Serving以使其可以读取这些源。TensorFlow Serving仅支持从文件系统加载模型。
一些经验
我们在产品中已经使用TensorFlow Serving大概半年的时间,我们的使用体验是相当平稳。它具有良好的预测时间延迟。以下是我们的TensorFlow Serving实例一周内的预测时间(以秒为单位)的第95百分位数的图(约20毫秒):
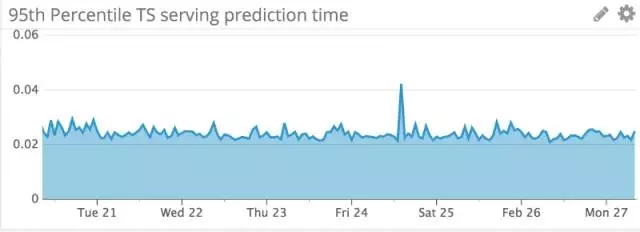
然而,在生产中使用TensorFlow Serving的过程中,我们也有一些经验教训可以跟大家分享。
1.模型版本化
到目前为止,我们已经在产品中使用了几个不同版本的TensorFlow模型,每一个版本都有不同的特性,比如网络结构、训练数据等。正确处理模型的不同版本已经是一个重要的任务。这是因为传递到TensorFlow Serving的输入请求通常涉及到多个预处理步骤。这些预处理步骤在不同TensorFlow模型版本下是不同的。预处理步骤和模型版本的不匹配可能导致错误的预测。
1a.明确说明你想要的版本
我们发现了一个简单但有用的防止错误预测的方法,也就是使用在model.proto定义中指定的版本属性,它是可选的(可以编译为model_pb2.py)。这样可以始终保证你的请求有效负载与预期的版本号匹配。
当你请求某个版本(比如从客户端请求版本5),如果TensorFlow Serving服务器不支持该特定版本,它将返回一个错误消息,提示找不到模型。
1b.服务多个模型版本
TensorFlow Serving默认的是加载和提供模型的版本。当我们在2016年9月首次应用TensorFlow Serving时,它不支持同时提供多个模型。这意味着在指定时间内它只有一个版本的模型。这对于我们的用例是不够的,因为我们希望服务多个版本的模型以支持不同神经网络架构的A / B测试。
其中一个选择是在不同的主机或端口上运行多个TensorFlow Serving进程,以使每个进程提供不同的模型版本。这样的话就需要:
用户应用程序(gRPC客户端)包含切换逻辑,并且需要知道对于给定的版本需要调用哪个TensorFlow Serving实例。这增加了客户端的复杂度,所以不是推荐。
一个可以将版本号映射到TensorFlow Serving不同实例的注册表。
更理想的解决方案是TensorFlow Serving可以支持多个版本的模型。
所以我决定使用一个“lab day”的时间来扩展TensorFlow Serving,使其可以服务多个版本的时间。在Zendesk,“lab day”就是我们可以每两周有一天的时间来研究我们感兴趣的东西,让它成为能够提高我们日常生产力的工具,或者一种我们希望学习的新技术。我已经有8年多没有使用C++代码了。但是,我对TensorFlow Serving代码库的可读性和整洁性印象深刻,这使其易于扩展。支持多个版本的增强功能已经提交,并且已经合并到主代码库中。
TensorFlow Serving维护人员对补丁和功能增强的反馈非常迅速。从的主分支,你可以启动TensorFlow Serving,用model_version_policy中附加的flag来服务多个模型版本:
/work/serving/bazel-bin/tensorflow_serving/model_servers/tensorflow_model_server — port=8999 — model_base_path=/work/awesome_model_directory — model_version_policy=ALL_VERSIONS
一个值得注意的要点是,服务多个模型版本,需要权衡的是更高的内存占用。所以上述的flag运行时,记住删除模型基本路径中的过时模型版本。
2.活用压缩
当你部署一个新的模型版本的时候,建议在复制到model_base_path之前,首先将导出的TensorFlow模型文件压缩成单个的压缩文件。Tensorflow Serving教程中包含了导出训练好的Tensorflow模型的步骤。导出的检查点TensorFlow模型目录通常具有以下文件夹结构:
一个包含版本号(比如0000001)和以下文件的父目录:
saved_model.pb:序列化模型,包括模型的图形定义,以及模型的元数据(比如签名)。
variables:保存图形的序列化变量的文件。压缩导出的模型:
tar -cvzf modelv1.tar.gz 0000001
为什么需要压缩?
压缩后转移和复制更快
如果你将导出的模型文件夹直接复制到model_base_path中,复制过程可能需要一段时间,这可能导致导出的模型文件已复制,但相应的元文件尚未复制。如果TensorFlow Serving开始加载你的模型,并且无法检测到源文件,那么服务器将无法加载模型,并且会停止尝试再次加载该特定版本。
3.模型大小很重要
我们使用的TensorFlow模型相当大,在300Mb到1.2Gb之间。我们注意到,在模型大小超过64Mb时,尝试提供模型时将出现错误。这是由于protobuf消息大小的硬编码64Mb限制,如这个TensorFlow Serving在Github上的问题所述。
最后,我们采用Github问题中描述的补丁来更改硬编码的常量值。(这对我们来说还是一个问题。如果你可以找到在不改变硬编码的情况下,允许服务大于64Mb的模型的替代方案,请联系我们。)
4.避免将源移动到你自己的分支下
从实现时开始,我们一直从主分支构建TensorFlow Serving源,的版本分支(v0.4)在功能和错误修复方面落后于主分支。因此,如果你只通过检查主分支来创建源,一旦新的更改被合并到主分支,你的源也可能改变。为了确保人工制品的可重复构建,我们发现检查特定的提交修订很重要:
TensorFlow Serving
TensorFlow(TensorFlow Serving里的Git子模块)
期待未来加入的一些功能增强清单
这里是一些我们比较感兴趣的希望以后TensorFlow Serving会提供的功能:
健康检查服务方法
一个TensorFlow Serving实例可以支持多种模型类型
直接可用的分布式存储(如AWS S3和Google存储)中的模型加载
直接支持大于64Mb的模型
不依赖于TensorFlow的Python客户端示例
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4490.html
摘要:在近期举办的全球架构师峰会上,个推首席数据架构师袁凯,基于他在数据平台的建设以及数据产品研发的多年经验,分享了面向机器学习数据平台的设计与搭建。二具体开展机器学习的过程原始数据经过数据的处理,入库到数据仓里。 机器学习作为近几年的一项热门技术,不仅凭借众多人工智能产品而为人所熟知,更是从根本上增能了传统的互联网产品。在近期举办的2018 ArchSummit全球架构师峰会上,个推首席数...
摘要:如何进行操作本文将介绍在有道云笔记中用于文档识别的实践过程,以及都有些哪些特性,供大家参考。年月发布后,有道技术团队第一时间跟进框架,并很快将其用在了有道云笔记产品中。微软雅黑宋体以下是在有道云笔记中用于文档识别的实践过程。 这一两年来,在移动端实现实时的人工智能已经形成了一波潮流。去年,谷歌推出面向移动端和嵌入式的神经网络计算框架TensorFlowLite,将这股潮流继续往前推。Tens...

阅读 859·2023-04-25 17:54
阅读 3082·2021-11-18 10:02
阅读 1229·2021-09-28 09:35
阅读 817·2021-09-22 15:18
阅读 2970·2021-09-03 10:49
阅读 3179·2021-08-10 09:42
阅读 2670·2019-08-29 16:24
阅读 1340·2019-08-29 15:08




