
摘要:为了进一步了解的逻辑,图对和进行了展开分析。另外,在命名空间中还隐式声明了控制依赖操作,这在章节控制流中相关说明。简述是高效易用的开源库,有效支持线性代数,矩阵和矢量运算,数值分析及其相关的算法。返回其中一块给用户,并将该内存块标识为占用。
3. TF 代码分析初步
3.1 TF总体概述
为了对TF有整体描述,本章节将选取TF白皮书[1]中的示例展开说明,如图 3 1所示是一个简单线性模型的TF正向计算图和反向计算图。图中x是输入,W是参数权值,b是偏差值,MatMul和Add是计算操作,dMatMul和dAdd是梯度计算操作,C是正向计算的目标函数,1是反向计算的初始值,dC/dW和dC/dx是模型参数的梯度函数。
图 3 1 tensorflow计算流图示例
以图 3 1为例实现的TF代码见图 3 2。首先声明参数变量W、b和输入变量x,构建线性模型y=W*x+b,目标函数loss采用误差平方和最小化方法,优化函数optimizer采用随机梯度下降方法。然后初始化全局参数变量,利用session与master交互实现图计算。
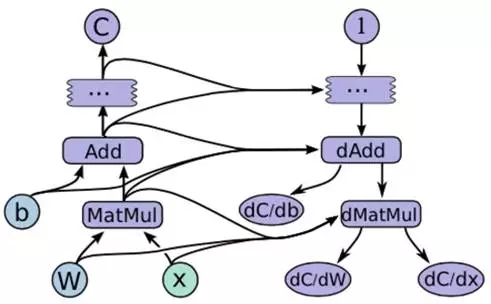
图 3 2 TF线性模型示例的实现代码
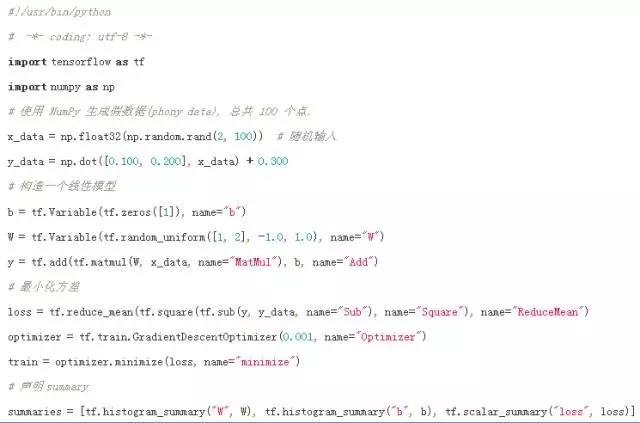
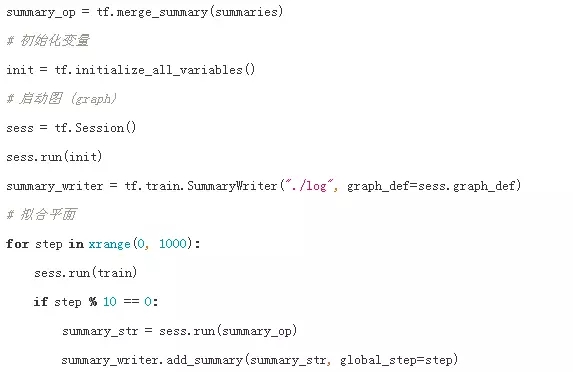
图 3 2中summary可以记录graph元信息和tensor数据信息,再利用tensorboard分析模型结构和训练参数。
图 3 3是上述代码在Tensorboard中记录下的Tensor跟踪图。Tensorboard可以显示scaler和histogram两种形式。跟踪变量走势可更方便的分析模型和调整参数。
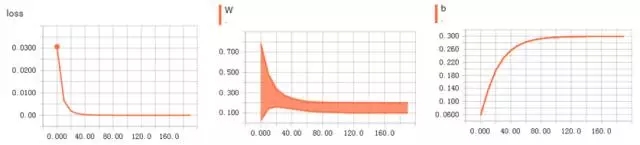
图 3 3 Tensorboard显示的TF线性模型参数跟踪
图 3 4是图 3 1示例在Tensorboard中显示的graph图。左侧子图描述的正向计算图和反向计算图,正向计算的输出被用于反向计算的输入,其中MatMul对应MatMul_grad,Add对应Add_grad等。右上侧子图指明了目标函数最小化训练过程中要更新的模型参数W、b,右下侧子图是参数节点W、b展开后的结果。
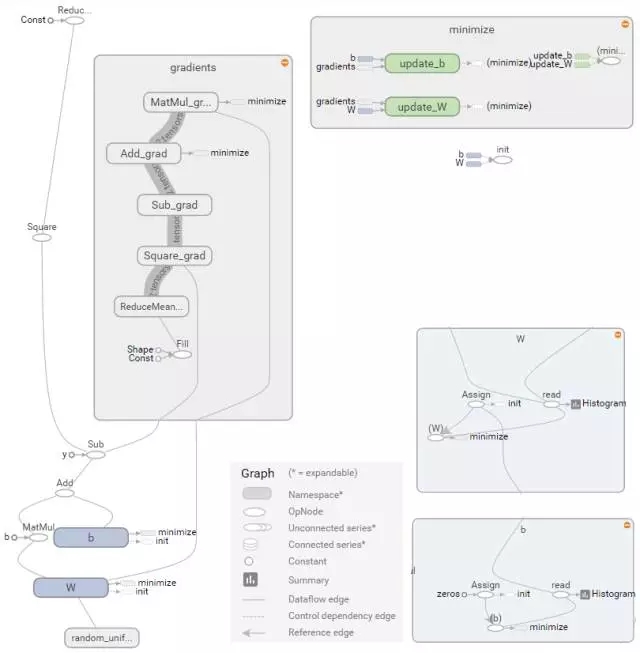
图 3 4 Tensorboard显示的TF线性模型graph
图 3 4中,参数W是命名空间(Namespace)类型,展开后的W主要由Assign和Read两个OpNode组成,分别负责W的赋值和读取任务。
命名空间gradients是隐含的反向计算图,定义了反向计算的计算逻辑。从图 3 1可以看出,更新参数W需要先计算dMatMul,即图 3 4中的MatMul_grad操作,而Update_W节点负责更新W操作。为了进一步了解UpdateW的逻辑,图 3 5对MatMul_grad和update_W进行了展开分析。

图 3 5 MatMul_grad计算逻辑
图 3 5中,子图(a)描述了MatMul_grad计算逻辑,子图(b)描述了MatMul_grad输入输出,子图(c)描述了update_W的计算逻辑。首先明确MatMul矩阵运算法则,假设 z=MatMul(x, y),则有dx = MatMul(dz, y),dy = MatMul(x, dz),由此可以推出dW=MatMul(dAdd, x)。在子图(a)中左下侧的节点b就是输入节点x,dAdd由Add_grad计算输出。update_W的计算逻辑由最优化函数指定,而其中的minimize/update_W/ApplyGradientDescent变量决定,即子图(b)中的输出变量Outputs。
另外,在MatMul_grad/tuple命名空间中还隐式声明了control dependencies控制依赖操作,这在章节2.4控制流中相关说明。
3.2 Eigen介绍
在Tensoflow中核心数据结构和运算主要依赖于Eigen和Stream Executor库,其中Eigen支持CPU和GPU加速计算,Stream Executor主要用于GPU环境加速计算。下面简单讲述Eigen库的相关特性,有助于进一步理解Tensorflow。
3.2.1 Eigen简述
Eigen是高效易用的C++开源库,有效支持线性代数,矩阵和矢量运算,数值分析及其相关的算法。不依赖于任何其他依赖包,安装使用都很简便[8]。具有如下特性:
Ø 支持整数、浮点数、复数,使用模板编程,可以为特殊的数据结构提供矩阵操作。比如在用ceres-solver进行做优化问题(比如bundle adjustment)的时候,有时候需要用模板编程写一个目标函数,ceres可以将模板自动替换为内部的一个可以自动求微分的特殊的double类型。而如果要在这个模板函数中进行矩阵计算,使用Eigen就会非常方便。
Ø 支持逐元素、分块、和整体的矩阵操作。
Ø 内含大量矩阵分解算法包括LU,LDLt,QR、SVD等等。
Ø 支持使用Intel MKL加速
Ø 部分功能支持多线程
Ø 稀疏矩阵支持良好,到今年新出的Eigen3.2,已经自带了SparseLU、SparseQR、共轭梯度(ConjugateGradient solver)、bi conjugate gradient stabilized solver等解稀疏矩阵的功能。同时提供SPQR、UmfPack等外部稀疏矩阵库的接口。
Ø 支持常用几何运算,包括旋转矩阵、四元数、矩阵变换、AngleAxis(欧拉角与Rodrigues变换)等等。
Ø 更新活跃,用户众多(Google、WilliowGarage也在用),使用Eigen的比较著名的开源项目有ROS(机器人操作系统)、PCL(点云处理库)、Google Ceres(优化算法)。OpenCV自带到Eigen的接口。
Eigen库包含 Eigen模块和unsupported模块,其中Eigen模块为official module,unsupported模块为开源贡献者开发的。
Eigen unsupported 模块中定义了数据类型Tensor及相关函数,包括Tensor的存储格式,Tensor的符号表示,Tensor的编译加速,Tensor的一元运算、二元运算、高维度泛化矩阵运算,Tensor的表达式计算。本章后续所述Tensor均为Eigen::Tensor
Eigen运算性能评估如图 3 6所示[9],eigen3的整体性能比eigen2有很大提升,与GOTO2、INTEL_MKL基本持平。
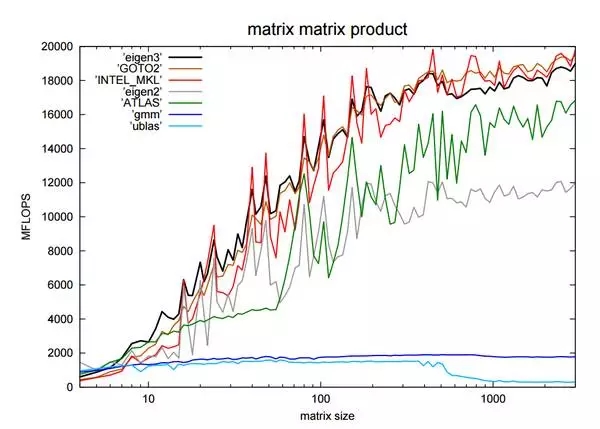
图 3 6矩阵运算常用库比较
3.2.2 Eigen 存储顺序
Eigen中的Tensor支持两种存储方式:
Ø Row-major表示矩阵存储时按照row-by-row的方式。
Ø Col-major表示矩阵存储时按照column-by-column的方式。
Eigen默认采用Col-major格式存储的(虽然也支持Row-major,但不推荐),具体采用什么存储方式取决于算法本身是行遍历还是列遍历为主。例如:A=[[a11, a12, a13], [a21, a22, a23]]的存储序列见图 3 7。
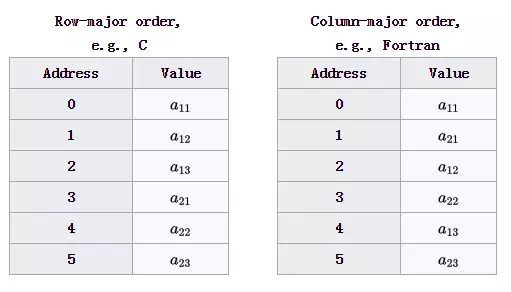
图 3 7 Row-major和Column-major存储顺序
3.2.3 Eigen 惰性求值
在编程语言理论中,存在及早求值(Eager Evaluation) 和惰性求值(Lazy Evaluation)
Ø 及早求值:大多数编程语言所拥有的普通计算方式
Ø 惰性求值:也认为是“延迟求值”,可以提高计算性能,最重要的好处是它可以构造一个无限的数据类型。
关于惰性求值,举例如下:
Vec3 = vec1 + vec2;
及早求值形式需要临时变量vec_temp存储运算结果,再赋值给vec3,计算效率和空间效率都不高:
Vec_temp = vec1 + vec2;
Vec3 = vec_temp
而惰性求值不需要临时变量保存中间结果,提高了计算性能:
Vec_symbol_3 = (vec_symbol_1 + vec_symbol_2);
Vec3 = vec_symbol_3.eval(vec1, vec2)
由于Eigen默认采用惰性计算,如果要求表达式的值可以使用Tensor::eval()函数。Tensor::eval()函数也是session.run()的底层运算。例如:
Tensor
3.2.4 Eigen 编译加速
编译加速可以充分发挥计算机的并行计算能力,提高程序运行速度。
举例如下:
普通的循环相加运算时间复杂度是O(n):
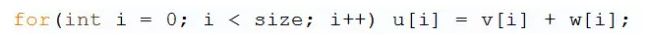
如果指令集支持128bit并行计算,则时间复杂度可缩短为O(n/4):

Eigen编译时使用了SSE2加速。假设处理float32类型,指令集支持128bit并行计算,则一次可以计算4个float32类型,速度提升4倍。
3.2.5 Eigen::half
Tensorflow支持的浮点数类型有float16, float32, float64,其中float16本质上是Eigen::half类型,即半精度浮点数[10]。关于半精度浮点数,英伟达2002年首次提出使用半精度浮点数达到降低数据传输和存储成本的目的。
在分布式计算中,如果对数据精度要求不那么高,可以将传输数据转换为float16类型,这样可以大大缩短设备间的数据传输时间。在GPU运算中,float16还可以减少一般的内存占用。
在Tensorflow的分布式传输中,默认会将float32转换为float16类型。Tensorflow的转换方式不同于nvidia的标准,采用直接截断尾数的方式转化为半精度浮点数,以减少转换时间。
图 3 8是双精度浮点数(float64)存储格式。

图 3 8 双精度浮点数
图 3 9是单精度浮点数(float32)存储格式。

图 3 9 单精度浮点数
图 3 10是半精度浮点数(float16)存储格式。
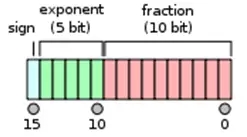
图 3 10 半精度浮点数
浮点数存储格式分成3部分,符号位,指数和尾数。不同精度是指数位和尾数位的长度不一样。
3.3 设备内存管理
TF设备内存管理模块利用BFC算法(best-fit with coalescing)实现。BFC算法是Doung Lea’s malloc(dlmalloc)的一个非常简单的版本。它具有内存分配、释放、碎片管理等基本功能[11]。
BFC将内存分成一系列内存块,每个内存块由一个chunk数据结构管理。从chunk结构中可以获取到内存块的使用状态、大小、数据的基址、前驱和后继chunk等信息。整个内存可以通过一个chunk的双链表结构来表示。
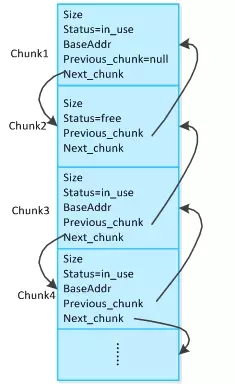
图 3 11内存分块结构图
用户申请一个内存块(malloc)。根据建立的chunk双链表找到一个合适的内存块(后面会说明什么是合适的内存块),如果该内存块的大小是用户申请大小的两倍以上,那么将该内存块切分成两块,这就是split操作。返回其中一块给用户,并将该内存块标识为占用。Spilt操作会新增一个chunk,所以需要修改chunk双链表以维持前驱和后继关系。
用户释放一个内存块(free)。先将该块标记为空闲。然后根据chunk数据结构中的信息找到其前驱和后继内存块。如果前驱和后继块中有空闲的块,那么将刚释放的块和空闲的块合并成一个更大的chunk(这就是merge操作,合并当前块和其前后的空闲块)。再修改双链表结构以维持前驱后继关系。这就做到了内存碎片的回收。
BFC的核心思想是:将内存分块管理,按块进行空间分配和释放;通过split操作将大内存块分解成小内存块;通过merge操作合并小的内存块,做到内存碎片回收。
但是还留下许多疑问。比如说申请内存空间时,什么样的块算合适的内存块?如何快速管理这种块?
BFC算法采取的是被动分块的策略。最开始整个内存是一个chunk,随着用户申请空间的次数增加,最开始的大chunk会被不断的split开来,从而产生越来越多的小chunk。当chunk数量很大时,为了寻找一个合适的内存块而遍历双链表无疑是一笔巨大的开销。为了实现对空闲块的高效管理,BFC算法设计了bin这个抽象数据结构。
Bin数据结构中,每个bin都有一个size属性,一个bin是一个拥有chunk size >= bin size的空闲chunk的集合。集合中的chunk按照chunk size的升序组织成单链表。BFC算法维护了一个bin的集合:bins。它由多个bin以及从属于每个bin的chunks组成。内存中所有的空闲chunk都由bins管理。
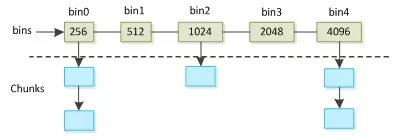
图 3 12 bins集合的结构图
图 3 12中每一列表示一个bin,列首方格中的数字表示bin的size。bin size的大小都是256的2^n的倍。每个bin下面挂载了一系列的空闲chunk,每个chunk的chunk size都大于等于所属的bin的bin size,按照chunk size的升序挂载成单链表。BFC算法针对bins这个集合设计了三个操作:search、insert、delete。
Search 操作:给定一个chunk size,从bins中找到大于等于该chunk size的最小的那个空闲chunk。Search操作具体流程如下。如果bin以数组的形式组织,那么可以从index = chunk size /256 >>2的那个bin开始查找。较好的情况是开始查找的那个bin的chunk链表非空,那么直接返回链表头即可。这种情况时间复杂度是常数级的。最坏的情况是遍历bins数组中所有的bin。对于一般大小的内存来说,bins数组元素非常少,比如4G空间只需要23个bin就足够了(256 * 2 ^ 23 > 4G),因此也很快能返回结果。总体来说search操作是非常高效的。对于固定大小内存来说,查找时间是常数量级的。
Insert 操作:将一个空闲的chunk插入到一个bin所挂载的chunk链表中,同时需要维持chunk链表的升序关系。具体流程是直接将chunk插入到index = chunk size /256 >>2的那个bin中即可。
Delete操作:将一个空闲的chunk从bins中移除。
TF中内存分配算法实现文件core/common_runtime/bfc_allocator.cc,GPU内存分配算法实现文件core/common_runtime/gpu/gpu_bfc_allocator.cc。
3.4 TF开发工具介绍
TF系统开发使用了bazel工具实现工程代码自动化管理,使用了protobuf实现了跨设备数据传输,使用了swig库实现python接口封装。本章将从这三方面介绍TF开发工具的使用。
3.4.1 Swig封装
Tensorflow核心框架使用C++编写,API接口文件定义在tensorflow/core/public目录下,主要文件是tensor_c_api.h文件,C++语言直接调用这些头文件即可。
Python通过Swig工具封装TF库包间接调用,接口定义文件tensorflow/python/ tensorflow.i。其中swig全称为Simplified Wrapper and Interface Generator,是封装C/C++并与其它各种高级编程语言进行嵌入联接的开发工具,对swig感兴趣的请参考相关文档。
在tensorflow.i文件中包含了若干个.i文件,每个文件是对应模块的封装,其中tf_session.i文件中包含了tensor_c_api.h,实现client向session发送请求创建和运行graph的功能。
3.4.2 Bazel编译和调试
Bazel是Google开源的自动化构建工具,类似于Make和CMake工具。Bazel的目标是构建“快速并可靠的代码”,并且能“随着公司的成长持续调整其软件开发实践”。
TF中几乎所有代码编译生成都是依赖Bazel完成的,了解Bazel有助于进一步学习TF代码,尤其是编译测试用例进行gdb调试。
Bazel假定每个目录为[package]单元,目录里面包含了源文件和一个描述文件BUILD,描述文件中指定了如何将源文件转换成构建的输出。
以图 3 13为例,左子图为工程中不同模块间的依赖关系,右子图是对应模块依赖关系的BUILD描述文件。
图 3 13中name属性来命名规则,srcs属性为模块相关源文件列表,deps属性来描述规则之间的依赖关系。”//search: google_search_page”中”search”是包名,”google_search_page”为规则名,其中冒号用来分隔包名和规则名;如果某条规则所依赖的规则在其他目录下,就用"//"开头,如果在同一目录下,可以忽略包名而用冒号开头。
图 3 13中cc_binary表示编译目标是生成可执行文件,cc_library表示编译目标是生成库文件。如果要生成google_search_page规则可运行

如果要生成可调试的二进制文件,可运行

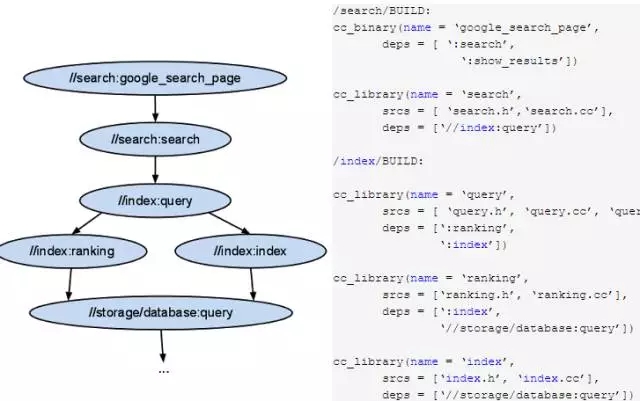
图 3 13 Bazel BUILD文件示例
TF中首次运行bazel时会自动下载很多依赖包,如果有的包下载失败,打开tensorflow/workspace.bzl查看是哪个包下载失败,更改对应依赖包的new_http_archive中的url地址,也可以把new_http_archive设置为本地目录new_local_repository。
TF中测试用例跟相应代码文件放在一起,如MatMul操作的core/kernels/matmul_op.cc文件对应的测试用例文件为core/kernels/matmul_op_test.cc文件。运行这个测试用例需要查找这个测试用例对应的BUILD文件和对应的命令规则,如matmul_op_test.cc文件对应的BUILD文件为core/kernels/BUILD文件,如下

其中tf_cuda_cc_test函数是TF中自定义的编译函数,函数定义在/tensorflow/ tensorflow.bzl文件中,它会把matmul_op_test.cc放进编译文件中。要生成matmul_op_test可执行文件可运行如下脚本:

3.4.3 Protobuf序列化
Protocol Buffers 是一种轻便高效的结构化数据存储格式,可以用于结构化数据串行化,或者说序列化。它很适合做数据存储或 RPC 数据交换格式。可用于通讯协议、数据存储等领域的语言无关、平台无关、可扩展的序列化结构数据格式。
Protobuf对象描述文件为.proto类型,编译后生成.pb.h和.pb.cc文件。
Protobuf主要包含读写两个函数:Writer(序列化)函数SerializeToOstream() 和 Reader(反序列化)函数 ParseFromIstream()。
Tensorflow在core/probobuf目录中定义了若干与分布式环境相关的.proto文件,同时在core/framework目录下定义了与基本数据类型和结构的.proto文件,在core/util目录中也定义部分.proto文件,感觉太随意了。
在分布式环境中,不仅需要传输数据序列化,还需要数据传输协议。Protobuf在序列化处理后,由gRPC完成数据传输。gRPC数据传输架构图见图 3 14。
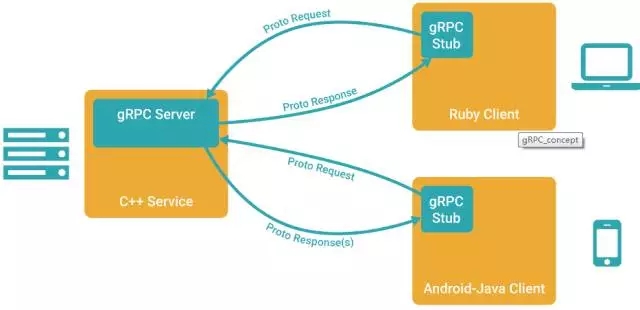
图 3 14 gRPC数据传输架构
gRPC服务包含客户端和服务端。gRPC客户端调用stub 对象将请求用 protobuf 方式序列化成字节流,用于线上传输,到 server 端后调用真正的实现对象处理。gRPC的服务端通过observer观察处理返回和关闭通道。
TF使用gRPC完成不同设备间的数据传输,比如超参数、梯度值、graph结构。
作者简介:

姚健,毕业于中科院计算所网络数据实验室,毕业后就职于360天眼实验室,主要从事深度学习和增强学习相关研究工作。目前就职于腾讯MIG事业部,从事神经机器翻译工作。联系方式: yao_62995@163.com
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4499.html

阅读 1176·2021-10-12 10:11
阅读 965·2019-08-30 15:53
阅读 2399·2019-08-30 14:15
阅读 3046·2019-08-30 14:09
阅读 1270·2019-08-29 17:24
阅读 1038·2019-08-26 18:27
阅读 1350·2019-08-26 11:57
阅读 2252·2019-08-23 18:23


