
摘要:通过利用一系列利用视频局部性的优化,显著降低了在每个帧上的计算量,同时仍保持常规检索的高精度。的差异检测器目前是使用逐帧计算的逻辑回归模型实现的。这些检测器在上的运行速度非常快,每秒超过万帧。也就是说,每秒处理的视频帧数超过帧。
视频数据正在爆炸性地增长——仅英国就有超过400万个CCTV监控摄像头,用户每分钟上传到 YouTube 上的视频超过300小时。深度学习的进展已经能够自动分析这些海量的视频数据,让我们得以检索到感兴趣的事物,检测到异常和异常事件,以及筛选出不会有人看的视频的生命周期。但是,这些深度学习方法在计算上是非常昂贵的:当前 state-of-the-art 的目标检测方法是在较先进的NVIDIA P100 GPU上以每秒10-80帧的速度运行的。这对单个视频来说还好,但对于大规模实际部署的视频来说,这是难以维持的。具体来说,假如用这样的方法来实时分析英国所有的CCTV监控视频,仅在硬件上就得花费超过50亿美元。
为了解决视频增长速度与分析成本之间的巨大差距,我们构建了一个名为 NoScope 的系统,与目前的方法相比,它处理视频内容的速度要快数千倍。我们的主要想法是,视频是高度冗余的,包含大量的时间局部性(即时间上的相似性)和空间局部性(即场景中的相似性)。为了利用这种局部性,我们设计了用于高效处理视频输入任务的 NoScope。通过利用一系列利用视频局部性的优化,显著降低了在每个帧上的计算量,同时仍保持常规检索的高精度。
本文将介绍NoScope优化的一个示例,并描述NoScope如何在模型级联中端到端地堆叠它们,以获得倍增的加速——在现实部署的网络摄像机上可提速1000倍。
一个典型例子
试想一下,我们想检索下面的监控摄像头拍摄的视频,以确定公交车在什么时候经过台北的某个交叉路口(例如,用于交通分析):


台北某个交叉路口的两个视频片段
那么,当前较好的视觉模型是如何处理这个问题的呢?我们可以运行 YOLOv2 或Faster R-CNN 之类的用于对象检测的卷积神经网络(CNN),通过在视频的每个帧上运行CNN来检测公交车:


使用YOLOv2标记的交叉路口片段
这种方法工作得很好,尤其是如果我们使视频中出现的标签流畅的话,那么问题出现在哪里呢?就是这些模型非常昂贵。这些模型的运行速度是每秒10-80帧,这对监控单个视频输入来说还好,但如果要处理上千个视频输入的话,效果并不好。
机会:视频中的局部性
为了提高检索的效率,我们应该看视频内容本身的性质。具体来说,视频的内容是非常冗余性的。让我们回到台北的街道监控视频,看一下以下一些出现公交车的帧:

从这个视频影像的角度看,这些公交车看起来是非常相似的,我们称这种局部(locality)形式为场景特定的局部性(scene-specific locality),因为在视频影像中,对象之间看起来并没有很大的不同(例如,与另一个角度的摄像头相比)。
此外,从这个监控视频中,很容易看出,即使公交车正在移动,每一个帧之间都没有太大的变化:

我们将这种特征称为时间局部性(temporal locality),因为时间点附近的帧看起来相似,并且包含相似的内容。
NoScope:利用局部性
为了利用上面观察到的特征,我们构建了一个名为 NoScope 的检索引擎,可以大大加快视频分析检索的速度。给定一个视频输入(或一组输入),一个(或一组)要检测的对象(例如,“在台北的监控视频影像中查找包含公交车的帧”),以及一个目标CNN(例如,YOLOv2),NoScope 输出的帧与YOLOv2的一致。但是NoScope 比输入CNN要快许多:它可以在可能的时候运行一系列利用局部性的更便宜的模型,而不是简单地运行成本更高的目标CNN。下面,我们描述了两类成本较低的模型:专门针对给定的视频内容(feed)和要检测的对象(以利用场景特定局部性)的模型,以及检测差异(以利用时间局部性)的模型。
这些模型端到端地堆叠,比原来的CNN要快1000倍。
利用场景特定局部性
NoScope 使用专用模型来利用场景特定局部性,或训练来从特定视频内容的角度检测特定对象的快速模型。如今的CNN已经能够识别各种各样的物体,例如猫、滑雪板、马桶等等。但在我们的检测台北地区的公交车的任务上,我们不需要关心猫、滑雪板或马桶。相反,我们可以训练一个只能从特定角度的监控视频检测公交车的模型。
举个例子,下面的图像是MS-COCO数据集中的一些样本,也是我们在检测中不需要关心的对象。

MS-COCO数据集中没有出现公交车的3个样本

MS-COCO数据集中出现公交车的2个样本。
NoScope 的专用模型也是CNN,但它们比通用的对象检测CNN更简单(更浅)。这有什么作用呢?与YOLOv2的每秒80帧相比,NoScope的专用模型每秒可以运行超过15000帧。我们可以将这些模型作为原始CNN的替代。
使用差异检测器来利用时间局部性
NoScope 使用差异检测器(difference detector)或设计来检测对象变化的快速模型来利用时间局部性。在许多视频中,标签(例如“有公交车”,“无公交车”)的变化比帧的变化少很多(例如,一辆公交车出现在帧中长达5秒,而模型以每秒30帧的速度运行)。为了说明,下面是两个都是150帧长度的视频,但标签并不是在每个视频中都有变化。


每个视频都是150帧,标签一样,但下边的视频没变过!
相比之下,现在的对象检测模型是逐帧地运行的,与帧之间的实际变化无关。这样设计的原因是,像YOLOv2这样的模型是用静态图像训练的,因此它将视频视为一系列的图像。因为NoScope可以访问特定的视频流,因此它可以训练差异检测模型,这些模型对时间依赖性敏感。NoScope的差异检测器目前是使用逐帧计算的逻辑回归模型实现的。这些检测器在CPU上的运行速度非常快,每秒超过10万帧。想专用模型一样,NoScope可以运行这些差异检测器,而不是调用昂贵的CNN。
把这些模型放到一起
NoScope将专用模型和差异检测器结合在一起,堆叠在一个级联中,或堆叠在使计算简化的一系列模型。如果差异检测器没有发生任何变化,那么NoScope会丢弃这一帧。如果专用模型对其标签有信心,那么NoScope会输出这个标签。而且,如果面对特别棘手的框架,NoScope 可以随时返回到完整的CNN。
为了设置这个级联(cascade)以及每个模型的置信度,NoScope提供了可以在精度和 速度之间折衷的优化器。如果想更快地执行,NoScope将通过端到端级联传递更少的帧。如果想得到更准确的结果,NoSceop 则将提高分类决定的简化阈值。如下图所示,最终结果实现了比当前方法快10000倍的加速。
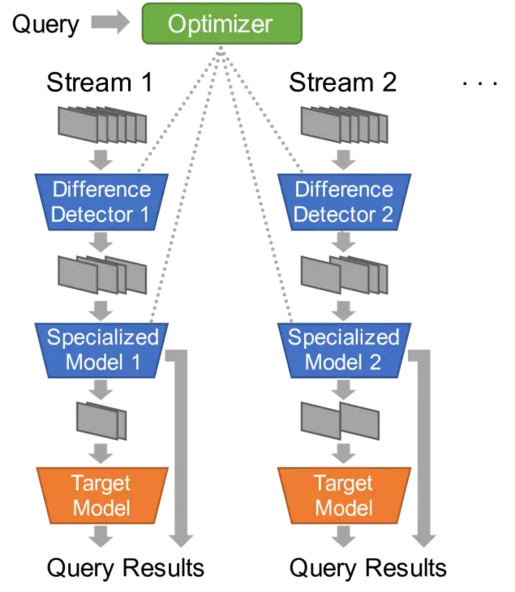
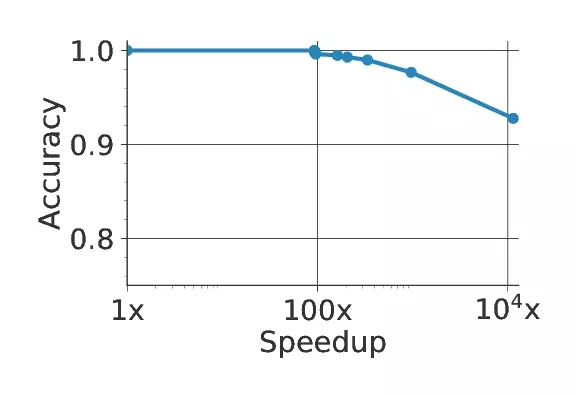
上图是NoScope的系统图示;下图显示了在一个有代表性的视频中速度和准确度的相关性。
差异检测器和专用模型都有助于这一结果。我们先是只使用YOLOv2进行因素分析,然后将每个类型的快速模型添加到级联中。两者都是为了实现较大话性能所必需的。

NoScope系统的因素分析
总结NoScope的级联车辆,优化器先在一个特定视频流中运行较慢的参考模型(YOLOv2,Faster R-CNN等),以获取标签。给定这些标签,NoScope训练一组专用模型和差异检测器,并使用一个holdout set来选择使用哪个特定模型或差异检测器。最后,NoScope的优化器将训练好的模型串联起来,可以在优化模型不确定是调用原始的模型。
结论
总结而言,视频数据非常丰富,但使用现代神经网络进行检索的速度非常慢。在NoScope中,我们利用时间局部性,将视频专用管道中差异检测和专用CNN相结合,视频检索速度比普通CNN检索提高了1000倍。也就是说,每秒处理的视频帧数超过8000帧。我们将继续改进NoScope来支持多类分类,非固定角度监控视频,以及更复杂的检索。
原文:http://dawn.cs.stanford.edu/2017/06/22/noscope/
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4581.html
摘要:月日,斯坦福大学发布了最新的深度学习推理榜单,阿里云获得了图像识别性能及成本双料冠军,打破了亚马逊保持的长达个月的纪录,这是该榜单首次出现中国科技公司。测试结果显示,阿里云识别图片的速度比亚马逊快倍,比谷歌快倍。12月25日,斯坦福大学发布了最新的DAWNBench深度学习推理榜单,阿里云获得了图像识别性能及成本双料冠军,打破了亚马逊保持的长达8个月的纪录,这是该榜单首次出现中国科技公司。斯...
摘要:但是如果你和我是一样的人,你想自己攒一台奇快无比的深度学习的电脑。可能对深度学习最重要的指标就是显卡的显存大小。性能不错,不过够贵,都要美元以上,哪怕是旧一点的版本。电源我花了美元买了一个的电源。也可以安装,这是一个不同的深度学习框架。 是的,你可以在一个39美元的树莓派板子上运行TensorFlow,你也可以在用一个装配了GPU的亚马逊EC2的节点上跑TensorFlow,价格是每小时1美...
摘要:年月日,将标志着一个时代的终结。数据集最初由斯坦福大学李飞飞等人在的一篇论文中推出,并被用于替代数据集后者在数据规模和多样性上都不如和数据集在标准化上不如。从年一个专注于图像分类的数据集,也是李飞飞开创的。 2017 年 7 月 26 日,将标志着一个时代的终结。那一天,与计算机视觉顶会 CVPR 2017 同期举行的 Workshop——超越 ILSVRC(Beyond ImageNet ...
摘要:作为当下最热门的话题,等巨头都围绕深度学习重点投资了一系列新兴项目,他们也一直在支持一些开源深度学习框架。八来自一个日本的深度学习创业公司,今年月发布的一个框架。 深度学习(Deep Learning)是机器学习中一种基于对数据进行表征学习的方法,深度学习的好处是用 非 监督式或半监督式 的特征学习、分层特征提取高效算法来替代手工获取特征(feature)。作为当下最热门的话题,Google...

阅读 3373·2021-11-18 10:02
阅读 1586·2021-10-12 10:08
阅读 1416·2021-10-11 10:58
阅读 1407·2021-10-11 10:57
阅读 1291·2021-10-08 10:04
阅读 2294·2021-09-29 09:35
阅读 913·2021-09-22 15:44
阅读 1381·2021-09-03 10:30





