
摘要:在本次竞赛中,南京信息工程大学和帝国理工学院的团队获得了目标检测的最优成绩,最优检测目标数量为平均较精确率为。最后在视频目标检测任务中,帝国理工大学和悉尼大学所组成的团队取得了较佳表现。
在本次 ImageNet 竞赛中,南京信息工程大学和帝国理工学院的团队 BDAT 获得了目标检测的最优成绩,最优检测目标数量为 85、平均较精确率为 0.732227。而在目标定位任务中Momenta和牛津大学的 WMV 团队和 NUS-Qihoo_DPNs (CLS-LOC) 团队分别在提供的数据内和加上额外数据上取得了最优成绩。最后在视频目标检测任务中,帝国理工大学和悉尼大学所组成的 IC&USYD 团队取得了较佳表现。
ImageNet 2017 简介:
这次挑战赛评估了从大规模的图像/影像中进行物体定位/检测的算法。最成功和富有创新性的队伍会被邀请至 CVPR 2017 workshop 进行展示。
1. 对 1000 种类别进行物体定位
2. 对 200 种全标注类别进行物体检测
3. 对 30 种全标注类别的视频进行物体检测
此次大赛是最后一届 ImageNet 挑战赛,并且聚焦于还未解决的问题和未来的方向。此次大赛的重点是: 1)呈现挑战赛的结果,包含新的测试器挑战赛(tester challenges),2)通过图像和视频中的物体检测,还有分类(classification)竞赛,回顾识别领域的尖端科技,3)这些方法是如何与工业界采用的计算机视觉领域的较高端技术相关联的——这也是本次挑战赛的初衷之一。4)邀请者对将来仍然存在的挑战提出了自己的看法,不论是从认知视觉,到机器视觉,还是一些其他方面。
目标检测(Object detection)
如下所示,目标检测任务取得较好成绩的是由南京信息工程大学和帝国理工学院组成的 BDAT,该队成员 Hui Shuai、Zhenbo Yu、Qingshan Liu、 Xiaotong Yuan、Kaihua Zhang、Yisheng Zhu、Guangcan Liu 和 Jing Yang 来自于南京信息工程大学,Yuxiang Zhou 和 Jiankang Deng 来自于帝国理工学院(IC)。
该团队表示他们在 LOC 任务中使用了适应性注意力机制 [1] 和深度联合卷积模型 [2,3]。Scale[4,5,6]、context[7]、采样和深度联合卷积网络在 DET 任务中得到了有效的使用。同时他们的得分排名也使用了物体概率估计。
[1] Residual Attention Network for Image Classification[J]. arXiv:1704.06904, 2017.
[2] Deep residual learning for image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 770-778.
[3] Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning[C]//AAAI. 2017: 4278-4284.
[4] U-net: Convolutional networks for biomedical image segmentation[J]. arXiv:1505.04597, 2015.
[5] Feature pyramid networks for object detection[J]. arXiv:1612.03144, 2016.
[6] Beyond skip connections: Top-down modulation for object detection[J]. arXiv:1612.06851, 2016.
[7] Crafting GBD-Net for Object Detection[J]. arXiv:1610.02579, 2016.
任务 1a:使用提供的训练数据进行目标检测
根据检测出的目标数量排序
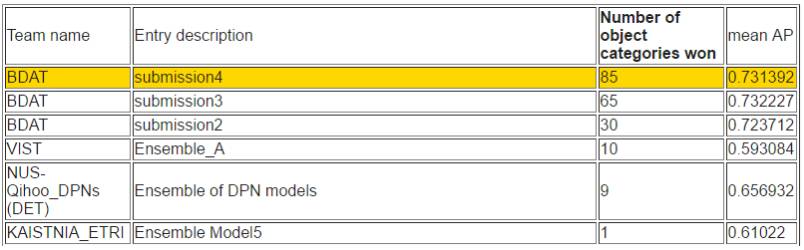
根据平均准确率排序

而在目标检测任务中新加坡国立大学(NUS)和奇虎 360 组成的 NUS-Qihoo_DPNs (DET) 也获得了不错的成绩。
他们在基于 Faster R-CNN 的目标检测任务中,采用了一个包含全新双路径拓扑的双路径网络(DPN/Dual Path Network)。DPN 中的特征共享机制和探索新特征的灵活性被证明在目标检测中有效。特别地,研究人员采用了若干个 DPN 模型——即 DPN-92、DPN-107、DPN-131 等——作为 Faster R-CNN 框架中的中继特征学习器(trunk feature learner)和头分类器(head classifier)。他们只使用最多 131 层的网络,因为在大多数常用的 GPU 内,它易于训练和适应,且性能良好。对于区域提案生成,利用低级细粒度特征取得了有效的 proposals 召回。进而,通过在分割成检测框架中采用扩展卷积,他们合并了有益的语境信息。在测试期间,他们设计了一个类别加权策略,以探索不同类别的专家模型,并根据多任务推断把权重用到不同的专家。除此之外,他们在图像分类任务中采用了预训练的模型以提取整体语境信息,这可在整体输入图像中为探测结果的推理提供有益的线索。
任务 1b:使用额外的训练数据进行目标检测
根据检测出的目标数量排序
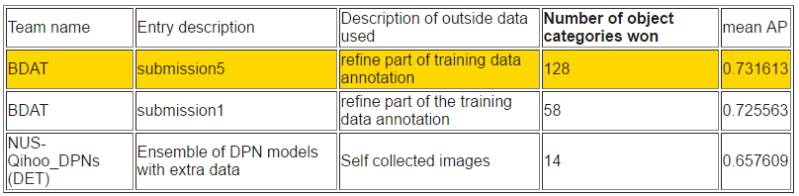
根据平均准确率排序

目标定位(Object localization)
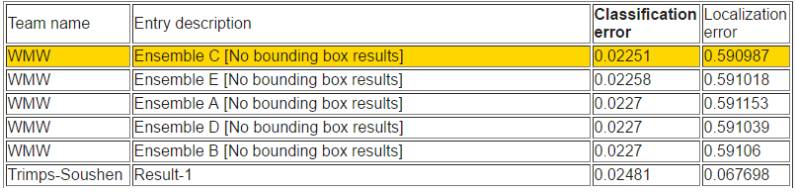
在给定训练数据进行分类和定位的任务中,WMW 取得了优异的成绩,分类误差率是较低的。
他们设计了一个新型结构的构造模块,叫做「挤压与激励」(「Squeeze-and-Excitation——SE」)。每一个基础构造模块通过「挤压」操作在全局接收域中嵌入信息,并且通过「激励」操作选择性地引起增强型响应(response enhancement)。SE 模型是该团队参赛作品的基础。他们研发了多个版本的 SENet,比如 SE-ResNet,SE-ResNeXt 和 SE-Inception-ResNet,在增加少量运算和 GPU 内存的基础上,这明显超过了它们的非 SE 对应部分。该团队在验证数据集中达到了 2.3% 的 top-5 误差率。
任务 2a:使用提供的训练数据进行分类+定位
根据定位错误率排序

根据分类错误率排名
在使用附加训练数据进行分类和定位的任务中,NUS-Qihoo_DPNs (CLS-LOC) 的定位误差率和分类误差率如下所示都取得很好的成绩。据该团队介绍,他们构建了一个简单、高效、模块化的双路径网络,引入了全新双路径拓扑。这一 DPN 模型包含一个残差路径和一个稠密连接路径,二者能够在保持学习探索新特征的灵活性的同时共享共同特征。DPN 是该团队完成全部任务使用的主要网络。在 CLS-LOC 任务中,他们采用 DPN 来预测 Top-5 目标,然后使用基于 DPN 的 Faster RCNN 分配对应的定位边界框。
任务 2b:使用额外的训练数据进行分类+定位
根据定位错误率排名

根据分类错误率排名

视频目标检测(Object detection from video)
如下所示,在视频目标检测任务中,帝国理工大学和悉尼大学所组成的 IC&USYD 团队在各个子任务和排序上都取得了最优的成绩。该团队是视频目标检测任务中使用了流加速(Flow acceleration)[1, 2]。并且最终的分值也是适应性地在检测器(detector)和追踪器(tracker)选择。
任务 3a:使用提供的训练数据进行视频目标检测
根据检测出的目标数量排序

根据平均准确率排序
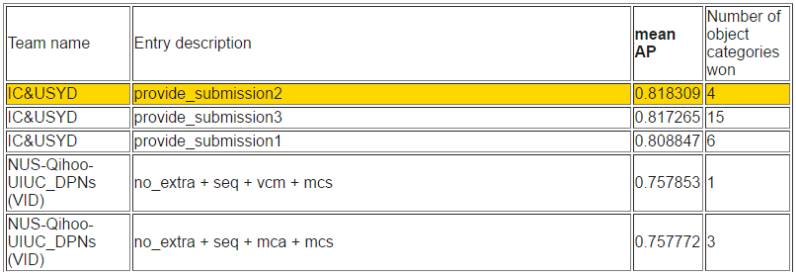
同时 NUS-Qihoo-UIUC_DPNs (VID) 在视频任务中同样有非凡的表现。他们在视频目标检测任务上的模型主要是基于 Faster R-CNN 并使用双路径网络作为支柱。具体地他们采用了三种 DPN 模型(即 DPN-96、DPN-107 和 DPN-131)和 Faster R-CNN 框架下的顶部分类器作为特征学习器。他们团队单个模型在验证集较好能实现 79.3%(mAP)。此外他们还提出了选择性平均池化(selected-average-pooling)策略来推断视频情景信息,该策略能精炼检测结果。
任务 3b:使用额外的训练数据进行视频目标检测
根据检测出的物体数量排序
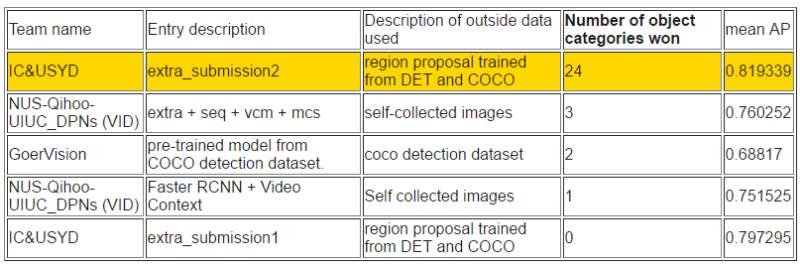
根据平均准确率排序
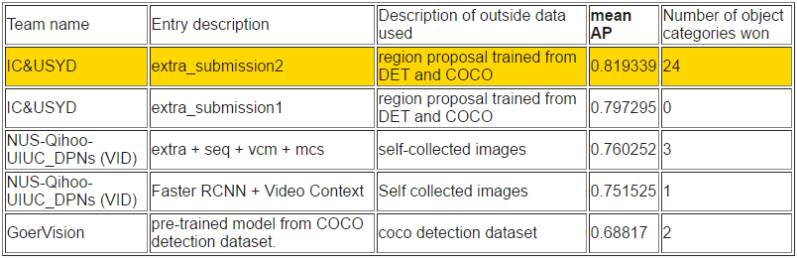
任务 3c:使用提供的训练数据进行视频目标检测/跟踪
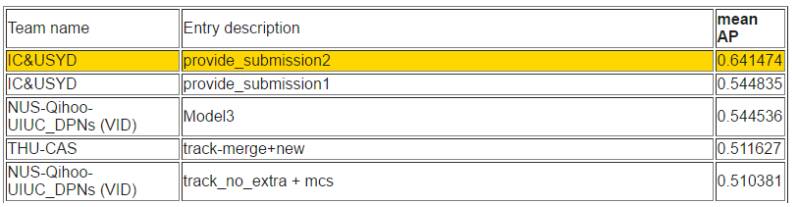
任务 3d:使用额外的训练数据进行视频目标检测/跟踪

本次 ImageNet 竞赛是最后一次,但同时 WebVision 近日也发布了其视觉竞赛的结果。相对于人工标注的 ImageNet 数据集,WebVision 中的数据拥有更多的噪声,并且它们更多的是从网络中获取,因此成本要比 ImageNet 低廉地多。正如近日谷歌发表的论文「Revisiting Unreasonable Effectiveness of Data in Deep Learning Era」,他们表示随着计算力的提升和模型性能的大大增强,我们很有必要构建一个更大和不那么标准的数据集。在该篇论文中,谷歌发现巨型非标准数据集(带噪声)同样能令模型的精度达到目前较好的水平,那么 ImageNet 下一步是否会被 JFT-300M 这样的数据集替换?因此我们很有必要关注能在噪声数据下学习到很好模型的竞赛——WebVision。

近日,WebVision 也发布了其视觉竞赛的结果,Malong AI Research 获得了图像分类任务的最优成绩。
WebVision 2017 挑战赛结果
WebVision 图像分类任务
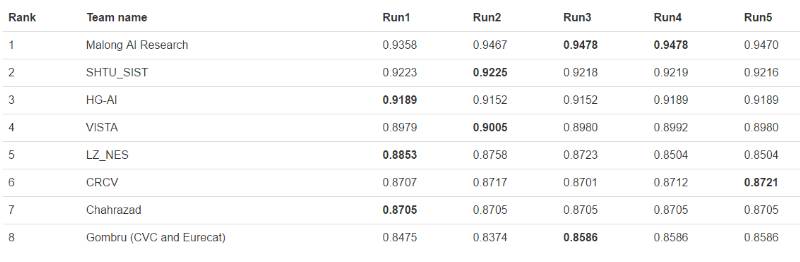
Pascal VOC 迁移学习任务

获胜团队 Malong AI Research:
我们使用半监督学习方法解决如何利用有噪声的不均衡数据训练大规模深度神经网络的问题。我们首先使用聚类算法将训练数据分成两部分:干净数据和噪声数据,然后使用干净数据训练一个深度网络模型。之后,我们使用所有数据(包括干净数据和噪声数据)来训练第一个模型(干净数据训练出的模型)上的网络。值得注意的是,我们在该网络的原始卷积层上使用了两个不同大小的卷积核(5,9)。至于训练,我们在干净数据上进行数据平衡,并设计了一个新的自适应 lr 下降系统,该系统根据噪声的类型(干净数据和噪声数据)略有不同。
WEBVISION 数据集
WebVision 数据集的设计是用来促进从嘈杂互联网数据中学习视觉表征的相关研究的。我们的目的是使深度学习方法从巨大的人工劳力(标注大规模视觉数据集)中解脱出来。我们把这个大规模网络图像数据集作为基准来发布,以推进在网络数据中进行学习的相关研究,包括弱监督视觉表征学习(weakly supervised visual representation learning),视觉迁移学习(visual transfer learning),文本与视觉(text and vision)等等(详见 WebVision 数据集的推荐环境配置)。
WebVision 数据集包含超过 24 万张的图像,它们是从 Flickr 网站和谷歌图像搜索引擎中爬取出来的。与 ILSVRC 2012 数据集相同的 1000 张图像用于查询(query),因此可以对一些现有方法直接进行研究,而且可以与在 ILSVRC 2012 数据集中进行训练的模型进行比较,还可以使在大规模场景中研究数据集偏差(dataset bias)的问题成为可能。伴随那些图片的文本信息(例如字注、用户标签或描述)也作为附加的元数据信息(meta information)来提供。提供一个包括 50,000 张图像(每一类别 50 张)的验证数据集以推进算法级研发。一个简单基准的初级结果展示了 WebVision 在一些视觉任务中是能够学习鲁棒性表征的,其性能表现与在人工标注的 ILSVRC 2012 数据集中学习的模型相类似。
数据集详情
数据统计
在我们的数据集中,每一类别的图像数量如图 1 所示,从几百到超过 10,000。每一类别中的图像数量依赖于:1)每一类别中的同义词集合生成的查询指令(query)的数量,2)Flickr 和谷歌的图像的有效性。
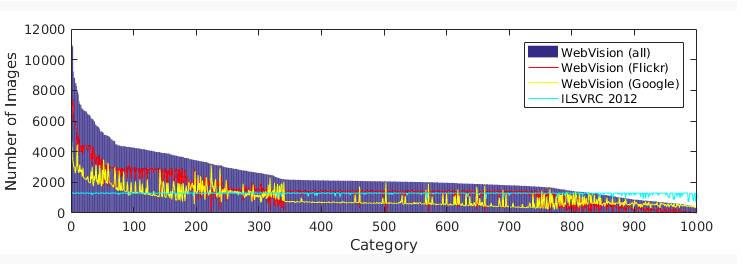
图 1:WebVision 数据集中每一类别的图像数量
简易基准评估
我们使用一个简单的基准对用于学习视觉表征的网络数据容量进行了调查研究。我们把来自 Flickr 和 Google 的已查询图像作为我们的训练数据集,并且从零开始在这一训练集上对 AlexNet 模型进行训练。然后我们在 Caltech-256 数据集和 PASCAL VOC 2007 数据集的图像分类任务中对学习后的 AlexNet 模型进行了评估,并且也在 PASCAL VOC 2007 数据集的物体识别相关任务中做了检测。
图像分类
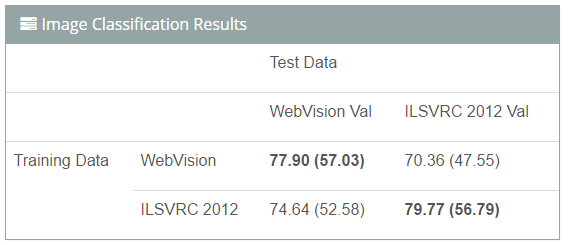
我们使用一个简单的基准调查研究了用于学习深度网络的网络数据容量。我们分别在 WebVision 训练集和 ILSVRC 2012 数据集上从头训练 AlexNet 模型,然后在 WebVision 验证集和 ILSVRC 2012 验证集上对这两个模型进行评估。需要注意的是,在 WebVision 数据集上训练模型时未使用人工标注数据。这里我们对 top-5(top-1)的准确率进行了报道。
结果如下:(1)使用 WebVision 数据集训练的 CNN 模型性能优于使用人工标注的 ILSVRC 2012 数据集训练的模型;(2)存在数据偏差,即在 WebVision 验证集上对这两个模型进行评估时,在 WebVision 上训练的模型优于在 ILSVRC 2012 上训练的模型,反之亦然。这对领域适应研究者可能是一个有意思的话题。
挑战赛结果地址:http://image-net.org/challenges/LSVRC/2017/results
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4602.html
摘要:年月日,将标志着一个时代的终结。数据集最初由斯坦福大学李飞飞等人在的一篇论文中推出,并被用于替代数据集后者在数据规模和多样性上都不如和数据集在标准化上不如。从年一个专注于图像分类的数据集,也是李飞飞开创的。 2017 年 7 月 26 日,将标志着一个时代的终结。那一天,与计算机视觉顶会 CVPR 2017 同期举行的 Workshop——超越 ILSVRC(Beyond ImageNet ...
摘要:月日至日,由麦思博主办的第届软件工作坊在深圳华侨城洲际大酒店盛大召开,位来自互联网行业的一线大咖与超过位中高层技术管理精英汇聚交流,共同探讨最前沿技术热点与技术思维。软件工作坊的每一届举办在技术交流案例分析达成共识上都取得了丰硕的成果。 6月24日至25日,由麦思博(msup)主办的第35届MPD软件工作坊在深圳华侨城洲际大酒店盛大召开,25位来自互联网行业的一线大咖与超过500位中高...
摘要:月日日,由主办的人工智能与机器学习创新峰会在上海海神诺富特大酒店圆满结束。签到现场,秩序井然本次峰会汇聚了超过位国内外顶级人工智能专家及一线技术大咖。本届峰会共设置了个专题,大主题分会场并行。话题主要围绕知乎搜索排序召回展开的。 人工智能的迅速发展深刻改变了世界的发展模式和人们的生活方式。5月18日-19日,由msup主办的A2M人工智能与机器学习创新峰会在上海海神诺富特大酒店圆满结束...
摘要:不仅阐明了应对一系列问题的解决方案,还介绍了在百花齐放的公链项目中的核心竞争力,并透露了主网会在月份正式发布的利好消息。共识之夜圆满落幕月日,联合星球日报及区块律动举办的共识之夜圆满落幕。 亲爱的ETM小伙伴: 随着高考、中考、期末考陆续结束 学生们似乎迎来了一年中最轻松的时刻 而对于区块链圈的人来说 却到了最难熬的时期 丰水期来临本是好事 奈何币价起起伏伏 算力再次大幅提升 伊朗加入...

阅读 984·2023-04-25 19:53
阅读 4637·2021-09-22 15:13
阅读 2820·2019-08-30 10:56
阅读 1581·2019-08-29 16:27
阅读 3183·2019-08-29 14:00
阅读 2672·2019-08-26 13:56
阅读 861·2019-08-26 13:29
阅读 1851·2019-08-26 11:31





