
Apache MXNet v0.12来了。
今天凌晨,亚马逊宣布了MXNet新版本,在这个版本中,MXNet添加了两个重要新特性:
支持英伟达Volta GPU,大幅减少用户训练和推理神经网络模型的时间。
在存储和计算效率方面支持稀疏张量(Sparse Tensor),让用户通过稀疏矩阵训练模型。
下面,量子位将分别详述这两个新特性。

Tesla V100 加速卡内含 Volta GV100 GPU
支持英伟达Volta GPU架构
MXNet v0.12增加了对英伟达Volta V100 GPU的支持,让用户训练深度神经网络的速度比在Pascal GPU上快3.5倍。这些运算通常用单精度(FP32)实现高准确率。
然而,最近的研究显示,用户可以用半精度(FP16)达到相同的准确率。
Volta GPU架构中引入了张量核(Tensor Core),每个张量核每小时能处理64次积和熔加运算(fused-multiply-add,FMA),每小时将CUDA每个核心FLOPS(每秒浮点运算)大致翻至四倍。
每个张量核都执行下图所示的D=AxB+C运算,其中A和B是半较精确的矩阵,C和D可以是半或单精度矩阵,从而进行混合精度训练。
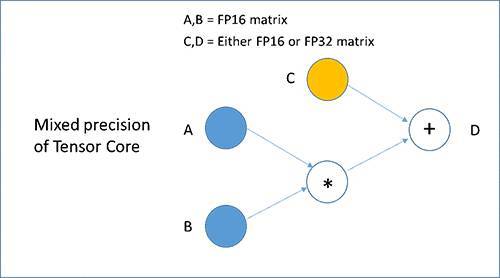
新混合精度训练可在不降低准确性的情况下实现较佳训练性能,神经网络中大部分层精度为FP16,且只在必要时用更高精度的数据类型。
MXNet利用Volta张量核使用户轻松用FP16训练模型。举个例子,用户将以下命令选项传递到train_imagenet,可在MXNet中启用FP16 train_imagenet.py脚本。

支持稀疏张量
MXNet v0.12增加了对稀疏张量的支持,来有效存储和计算大多数元素为0的张量。
我们熟悉的亚马逊推荐系统就是基于深度学习的推荐引擎,它包含了稀疏矩阵的乘法和加法,其中大多数元素都是0。
在稀疏矩阵中执行万亿次矩阵运算,与在密集矩阵之间执行的方式相同。在密集矩阵的存储和计算效率不高,在默认密结构中存储和操作稀疏矩阵,会导致在不必要的处理上浪费内存。
为了解决这些问题,MXNet开始支持稀疏张量,让用户在保持存储和计算效率的方式下执行稀疏矩阵操作,更快地训练深度学习模型。MXNet v0.12支持两种主要的稀疏数据格式:压缩稀疏矩阵(CSR)和行稀疏(RSP)。
CSR格式被优化来表示矩阵中的大量列,其中每行只有几个非零元素。经过优化的RSP格式用来表示矩阵中的大量行,其中的大部分行切片都是零。
例如,可以用CSR格式对推荐引擎输入数据的特征向量进行编码,而RSP格式可在训练期间执行稀疏梯度更新。
这个版本支持大多数在CPU上常用运算符的稀疏操作,比如矩阵点乘积和元素级运算符。在未来版本中,将增加对更多运算符的稀疏支持。
相关资料
最后,附官方介绍地址:
https://amazonaws-china.com/cn/blogs/ai/apache-mxnet-release-adds-support-for-new-nvidia-volta-gpus-and-sparse-tensor/
MXNet使用指南:
http://mxnet.incubator.apache.org/get_started/install.html
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4658.html
摘要:是由华盛顿大学在读博士陈天奇等人提出的深度学习自动代码生成方法,去年月机器之心曾对其进行过简要介绍。目前的堆栈支持多种深度学习框架以及主流以及专用深度学习加速器。 TVM 是由华盛顿大学在读博士陈天奇等人提出的深度学习自动代码生成方法,去年 8 月机器之心曾对其进行过简要介绍。该技术能自动为大多数计算硬件生成可部署优化代码,其性能可与当前最优的供应商提供的优化计算库相比,且可以适应新型专用加...
摘要:亚马逊和华盛顿大学今天合作发布了开源的端到端深度学习编译器。项目作者之一陈天奇在微博上这样介绍这个编译器我们今天发布了基于工具链的深度学习编译器。陈天奇团队对的性能进行了基准测试,并与进行了比较。 亚马逊和华盛顿大学今天合作发布了开源的端到端深度学习编译器NNVM compiler。先提醒一句,NNVM compiler ≠ NNVM。NNVM是华盛顿大学博士陈天奇等人2016年发布的模块化...
摘要:幸运的是,这些正是深度学习所需的计算类型。几乎可以肯定,英伟达是目前执行深度学习任务较好的选择。今年夏天,发布了平台提供深度学习支持。该工具适用于主流深度学习库如和。因为的简洁和强大的软件包扩展体系,它目前是深度学习中最常见的语言。 深度学习初学者经常会问到这些问题:开发深度学习系统,我们需要什么样的计算机?为什么绝大多数人会推荐英伟达 GPU?对于初学者而言哪种深度学习框架是较好的?如何将...
摘要:深度学习是一个对算力要求很高的领域。这一早期优势与英伟达强大的社区支持相结合,迅速增加了社区的规模。对他们的深度学习软件投入很少,因此不能指望英伟达和之间的软件差距将在未来缩小。 深度学习是一个对算力要求很高的领域。GPU的选择将从根本上决定你的深度学习体验。一个好的GPU可以让你快速获得实践经验,而这些经验是正是建立专业知识的关键。如果没有这种快速的反馈,你会花费过多时间,从错误中吸取教训...
摘要:据悉,在旧金山举行的高通活动上,这家巨头正式宣布进军云计算市场,并发布了面向人工智能推理计算的专用加速器。没有任何预告,继谷歌亚马逊和英伟达之后,高通成为第四家成功在云端推理上正式发布芯片的公司。提起高通,业内对它的直接印象就是移动芯片领域的巨头。一直以来,高通也确实只在移动通信领域深耕,并从芯片到底层平台一揽子都包下。而现在,高通冷不丁扔出的一枚炸弹也将一改以往大家对它的认知。据悉,在旧金...

阅读 1672·2023-04-26 01:28
阅读 3413·2021-11-22 13:53
阅读 1592·2021-09-04 16:40
阅读 3279·2019-08-30 15:55
阅读 2765·2019-08-30 15:54
阅读 2577·2019-08-30 13:47
阅读 3503·2019-08-30 11:27
阅读 1219·2019-08-29 13:21






