
摘要:二是精度查全率和得分,用来衡量判别式模型的质量。精度查全率和团队还用他们的三角形数据集,测试了样本量为时,大范围搜索超参数来进行计算的精度和查全率。
从2014年诞生至今,生成对抗网络(GAN)热度只增不减,各种各样的变体层出不穷。有位名叫Avinash Hindupur的国际友人建立了一个GAN Zoo,他的“动物园”里目前已经收集了多达214种有名有姓的GAN。
DeepMind研究员们甚至将自己提出的一种变体命名为α-GAN,然后在论文中吐槽说,之所以用希腊字母做前缀,是因为拉丁字母几乎都被占了……

这还不是最匪夷所思的名字,在即将召开的NIPS 2017上,杜克大学还有个Δ-GAN要发表。
就是这么火爆!
那么问题来了:这么多变体,有什么区别?哪个好用?
于是,Google Brain的几位研究员(不包括原版GAN的爸爸Ian Goodfellow)对各种GAN做一次“中立、多方面、大规模的”评测,得出了一个有点丧的结论:
No evidence that any of the tested algorithms consistently outperforms the original one.
量子位非常不严谨地翻译一下:
都差不多……都跟原版差不多……

比什么?
这篇论文集中探讨的是无条件生成对抗网络,也就是说,只有无标签数据可用于学习。选取了如下GAN变体:
MM GAN
NS GAN
WGAN
WGAN GP
LS GAN
DRAGAN
BEGAN
其中MM GAN和NS GAN分别表示用minimax损失函数和用non-saturating损失函数的原版GAN。

除此之外,他们还在比较中加入了另一个热门生成模型VAE(Variational Autoencoder,变分自编码器)。
对于各种GAN的性能,Google Brain团队选了两组维度来进行比较。
一是FID(Fréchet Inception Distance),FID的值和生成图像的质量负相关。
测试FID时用了4个数据集:MNIST、Fashion MNIST、CIFAR-10和CELEBA。这几个数据集的复杂程度从简单到中等,能快速进行多次实验,是测试生成模型的常见选择。
二是精度(precision、)、查全率(recall)和F1得分,用来衡量判别式模型的质量。其中F1是精度和查全率的调和平均数。
这项测试所用的,是Google Brain研究员们自创的一个数据集,由各种角度的三角形灰度图像组成。

精度和查全率都高、高精度低查全率、低精度高查全率、精度和查全率都低的模型的样本
对比结果
Google Brain团队从FID和F1两个方面对上面提到的模型进行比较,得出了以下结果。
FID
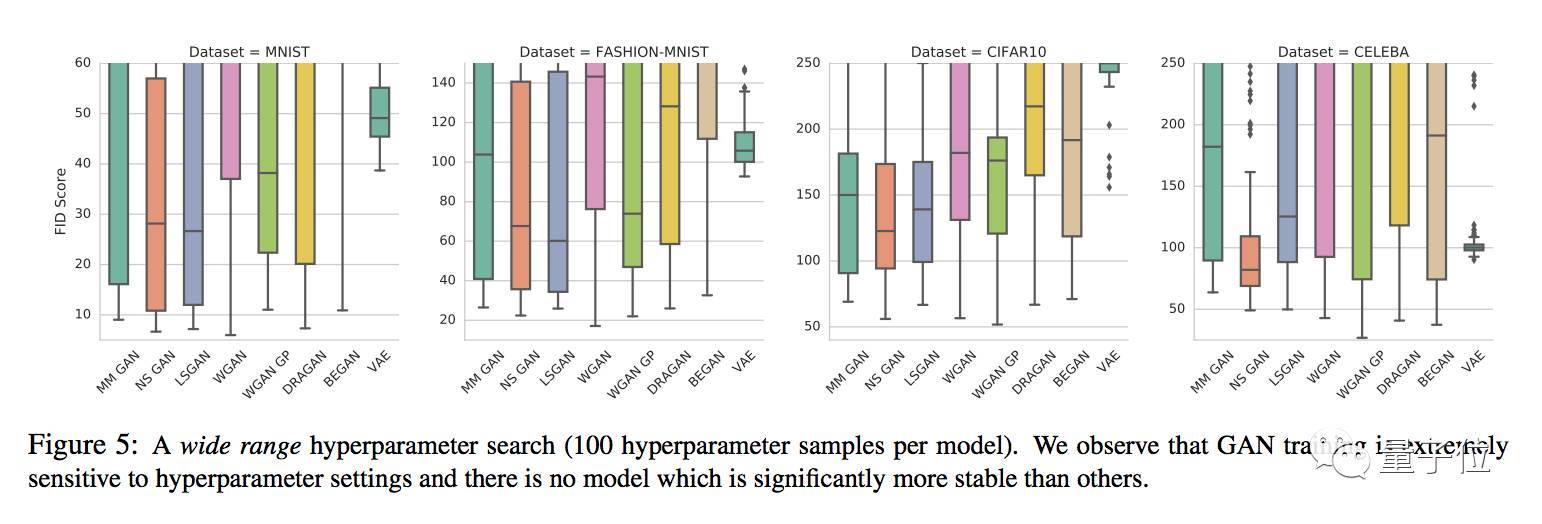
通过对每个模型100组超参数的大范围搜索,得出的结论是GAN在训练中都对于超参数设置非常敏感,没有哪个变体能够幸免,也就说,哪个GAN也没能比竞品们更稳定。
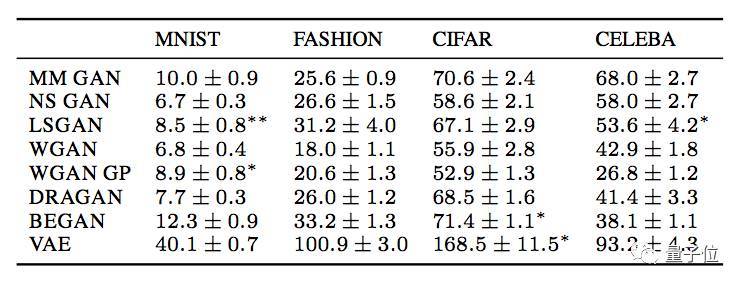
从结果来看,每个模型的性能擅长处理的数据集不太一样,没有在所有数据集上都明显优于同类的。不过,VAE相比之下是最弱的,它所生成出的图像最模糊。
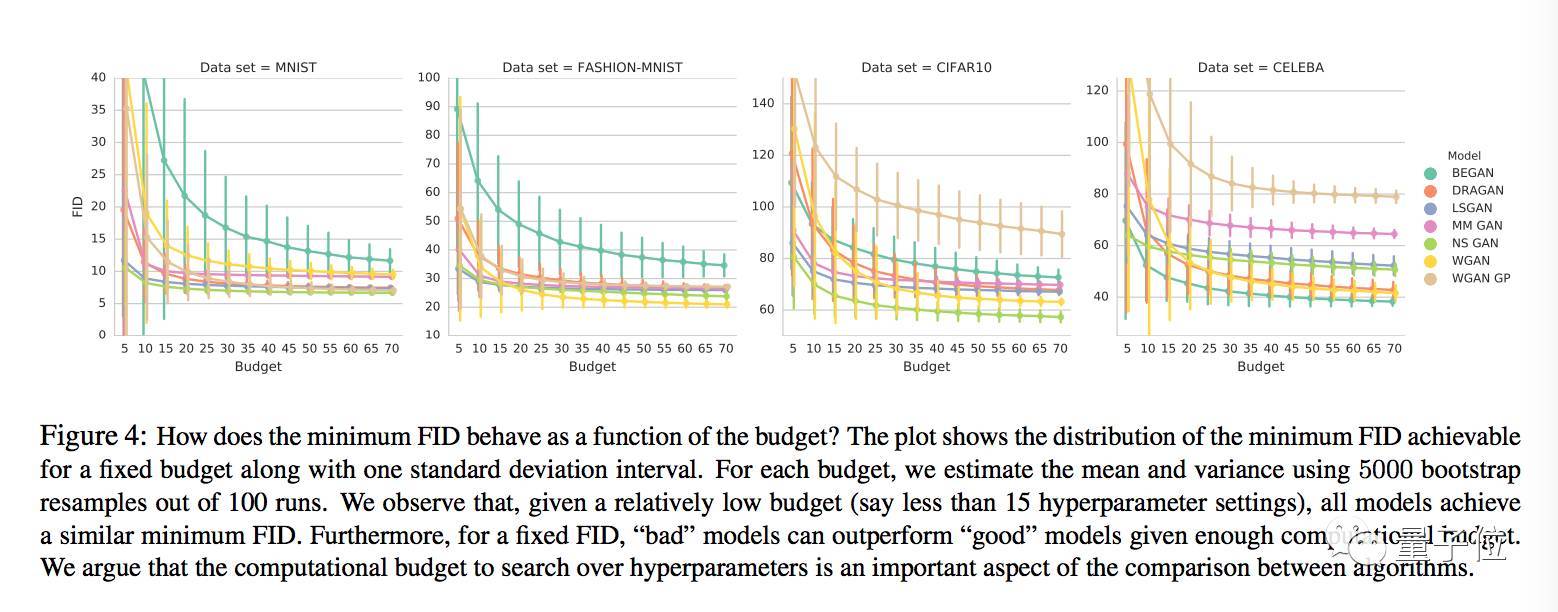
测试还显示,随着计算资源配置的提高,最小FID有降低的趋势。
如果设定一个FID范围,用比较多计算资源训练的“坏”模型,可能表现得比用较少计算资源训练的“好”模型要更好。
另外,当计算资源配置相对比较低的时候,所有模型的最小FID都差不多,也就是说,如果严格限制预算,就比较不出这些模型之间具有统计意义的显著区别。
他们经过比较得出的结论是,用能达到的最小FID来对模型进行比较是没有意义的,要比较固定计算资源配置下的FID分布。
FID之间的比较也表明,随着计算力的增加,较先进的GAN模型之间体现不出算法上的优劣差别。
精度、查全率和F1
Google Brain团队还用他们的三角形数据集,测试了样本量为1024时,大范围搜索超参数来进行计算的精度和查全率。
对于特定的模型和超参数设置,较高F1得分会随着计算资源配置的不同而不同,如下图所示:
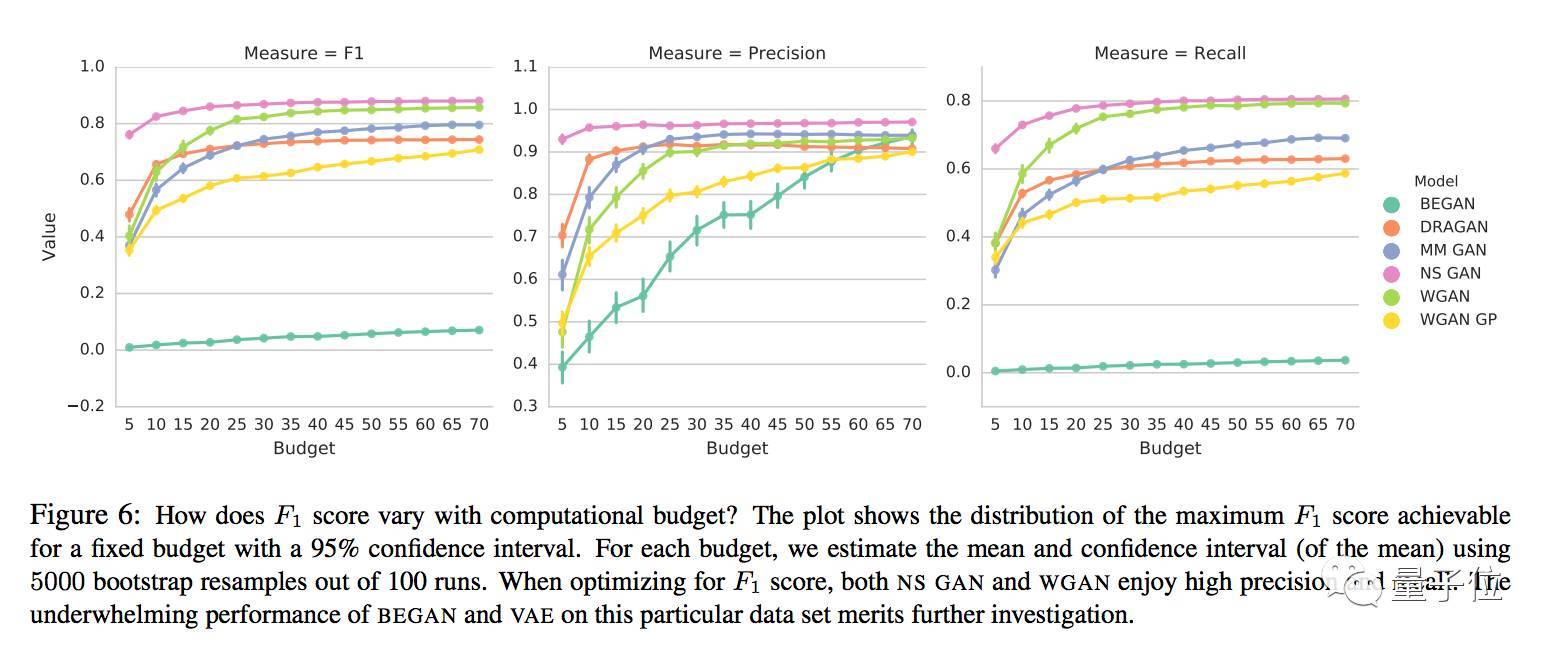
不同计算资源配置下各模型的F1、精度和查全率
论文作者们说,即使是一个这么简单的任务,很多模型的F1也并不高。当针对F1进行优化时,NS GAN和WGAN的精度和查全率都比较高。
和原版GAN相比
Google Brain团队还将这些变体和原版GAN做了对比。他们得出的结论是,没有实证证据能证明这些GAN变体在所有数据集上明显优于原版。
实际上,NS GAN水平和其他模型持平,在MNIST上的FID总体水平较好,F1也比其他模型要高。
相关链接
要详细了解这项研究,还是得读论文:
Are GANs Created Equal? A Large-Scale Study
Mario Lucic, Karol Kurach, Marcin Michalski, Sylvain Gelly, Olivier Bousquet
https://arxiv.org/abs/1711.10337
查找某种GAN变体,可以去文章开头提到的GAN Zoo:
https://github.com/hindupuravinash/the-gan-zoo
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4684.html
摘要:近日,谷歌大脑发布了一篇全面梳理的论文,该研究从损失函数对抗架构正则化归一化和度量方法等几大方向整理生成对抗网络的特性与变体。他们首先定义了全景图损失函数归一化和正则化方案,以及最常用架构的集合。 近日,谷歌大脑发布了一篇全面梳理 GAN 的论文,该研究从损失函数、对抗架构、正则化、归一化和度量方法等几大方向整理生成对抗网络的特性与变体。作者们复现了当前较佳的模型并公平地对比与探索 GAN ...
摘要:我仍然用了一些时间才从神经科学转向机器学习。当我到了该读博的时候,我很难在的神经科学和的机器学习之间做出选择。 1.你学习机器学习的历程是什么?在学习机器学习时你最喜欢的书是什么?你遇到过什么死胡同吗?我学习机器学习的道路是漫长而曲折的。读高中时,我兴趣广泛,大部分和数学或科学没有太多关系。我用语音字母表编造了我自己的语言,我参加了很多创意写作和文学课程。高中毕业后,我进了大学,尽管我不想去...
摘要:是世界上最重要的研究者之一,他在谷歌大脑的竞争对手,由和创立工作过不长的一段时间,今年月重返,建立了一个探索生成模型的新研究团队。机器学习系统可以在这些假的而非真实的医疗记录进行训练。今年月在推特上表示是的,我在月底离开,并回到谷歌大脑。 理查德·费曼去世后,他教室的黑板上留下这样一句话:我不能创造的东西,我就不理解。(What I cannot create, I do not under...
摘要:生成式对抗网络简称将成为深度学习的下一个热点,它将改变我们认知世界的方式。配图针对三年级学生的对抗式训练属于你的最严厉的批评家五年前,我在哥伦比亚大学举行的一场橄榄球比赛中伤到了自己的头部,导致我右半身腰部以上瘫痪。 本文作者 Nikolai Yakovenko 毕业于哥伦比亚大学,目前是 Google 的工程师,致力于构建人工智能系统,专注于语言处理、文本分类、解析与生成。生成式对抗网络—...

阅读 1025·2021-11-16 11:56
阅读 1827·2021-11-16 11:45
阅读 3340·2021-10-08 10:13
阅读 4294·2021-09-22 15:27
阅读 871·2019-08-30 11:03
阅读 777·2019-08-30 10:56
阅读 1083·2019-08-29 15:18
阅读 1864·2019-08-29 14:05






