
摘要:近日,来自华盛顿大学的和提出的版本。而那些评分较高的区域就可以视为检测结果。此外,相对于其它目标检测方法,我们使用了完全不同的方法。从图中可以看出准确率高,速度也快。对于的图像,可以达到的检测速度,获得的性能,与的准确率相当但是速度快倍。
近日,来自华盛顿大学的 Joseph Redmon 和 Ali Farhadi 提出 YOLO 的版本 YOLOv3。通过在 YOLO 中加入设计细节的变化,这个新模型在取得相当准确率的情况下实现了检测速度的很大提升,一般它比 R-CNN 快 1000 倍、比 Fast R-CNN 快 100 倍。
代码地址:https://pjreddie.com/yolo/.
1. 引言
有时,你一整年全在敷衍了事而不自知。比如今年我就没做太多研究,在推特上挥霍光阴,置 GANs 于不顾。凭着上年余留的一点动力,我成功对 YOLO 做了一些升级。但实话讲,没什么超有趣的东西,只不过是些小修小补。同时我对其他人的研究也尽了少许绵薄之力。
于是就有了今天的这篇论文。我们有一个最终截稿日期,需要随机引用 YOLO 的一些更新,但是没有资源。因此请留意技术报告。
技术报告的优势在于其不需要介绍,你自然知道来由。因此简介的最后将为余文提供路标。首先我将介绍 YOLOv3 的结局方案;接着是其实现。我们也会介绍一些失败案例。最后是本文的总结与思考。
2. 解决方案
这一部分主要介绍了 YOLOv3 的解决方案,我们从其他研究员那边获取了非常多的灵感。我们还训练了一个非常优秀的分类网络,因此原文章的这一部分主要从边界框的预测、类别预测和特征抽取等方面详细介绍整个系统。
简而言之,YOLOv3 的先验检测(Prior detection)系统将分类器或定位器重新用于执行检测任务。他们将模型应用于图像的多个位置和尺度。而那些评分较高的区域就可以视为检测结果。
此外,相对于其它目标检测方法,我们使用了完全不同的方法。我们将一个单神经网络应用于整张图像,该网络将图像划分为不同的区域,因而预测每一块区域的边界框和概率,这些边界框会通过预测的概率加权。
我们的模型相比于基于分类器的系统有一些优势。它在测试时会查看整个图像,所以它的预测利用了图像中的全局信息。与需要数千张单一目标图像的 R-CNN 不同,它通过单一网络评估进行预测。这令 YOLOv3 非常快,一般它比 R-CNN 快 1000 倍、比 Fast R-CNN 快 100 倍。
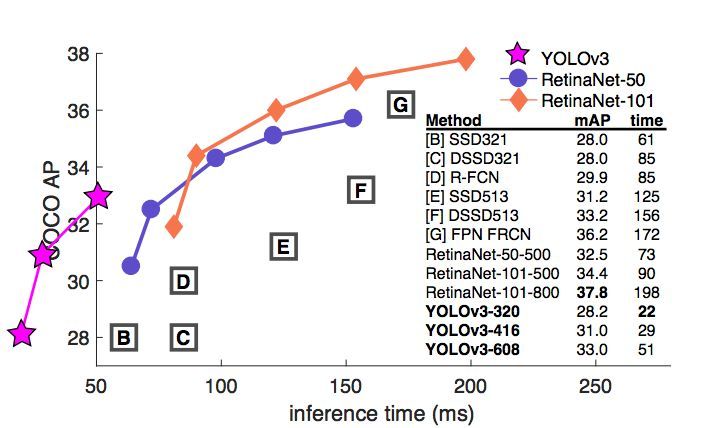
图 1:我们从 Focal Loss 论文 [7] 中采用了这张图。YOLOv3 在实现相同准确度下要显著地比其它检测方法快。时间都是在采用 M40 或 Titan X 等相同 GPU 下测量的。

图 2:带有维度先验和定位预测的边界框。我们边界框的宽和高以作为离聚类中心的位移,并使用 Sigmoid 函数预测边界框相对于滤波器应用位置的中心坐标。
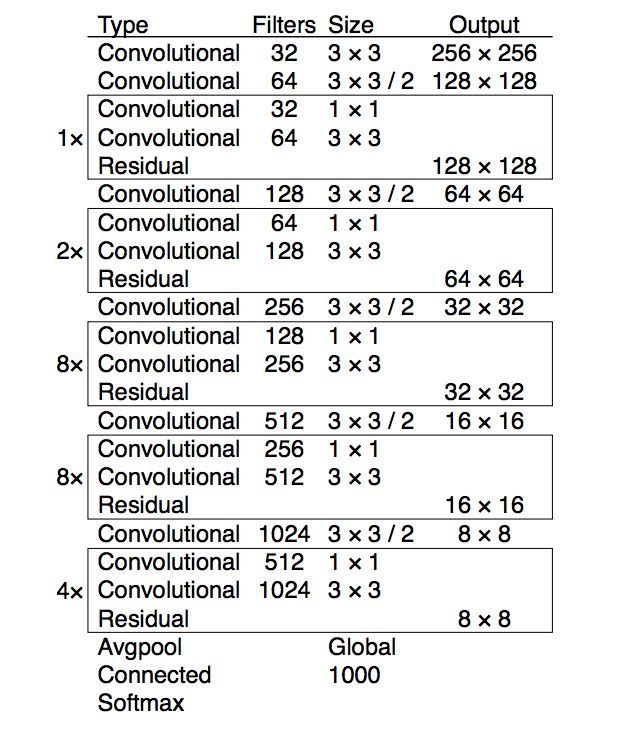
表 1:Darknet-53 网络架构。
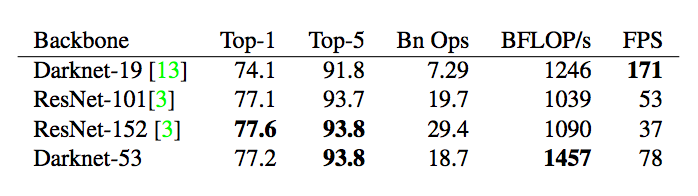
表 2:主干架构的性能对比:准确率(top-1 误差、top-5 误差)、运算次数(/十亿)、每秒浮点数运算次数(/十亿),以及 FPS 值。
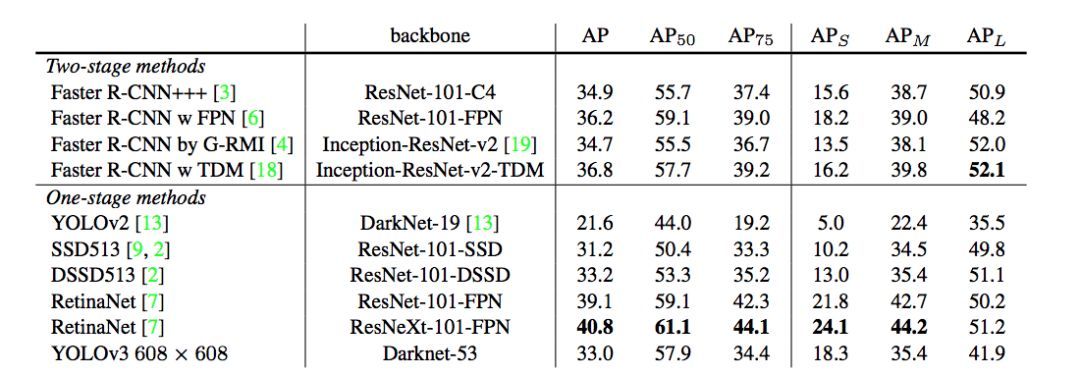
表 3:该表来自 [7]。从中看出,YOLOv3 表现得不错。RetinaNet 需要大约 3.8 倍的时间来处理一张图像,YOLOv3 相比 SSD 变体要好得多,并在 AP_50 指标上和当前较佳模型有得一拼。

图 3:也是借用了 [7] 中的图,展示了以.5 IOU 指标的速度/准确率权衡过程(mAP vs 推断时间)。从图中可以看出 YOLOv3 准确率高,速度也快。
最后,机器之心也尝试使用预训练的 YOLOv3 执行目标检测,在推断中,模型需要花 1s 左右加载模型与权重,而后面的预测与图像本身的像素大小有非常大的关系。因此,吃瓜小编真的感觉 YOLOv3 很快哦。
论文:YOLOv3: An Incremental Improvement

论文链接:https://pjreddie.com/media/files/papers/YOLOv3.pdf
摘要:我们在本文中提出 YOLO 的版本 YOLOv3。我们对 YOLO 加入了许多设计细节的变化,以提升其性能。这个新模型相对更大但准确率更高。不用担心,它依然非常快。对于 320x320 的图像,YOLOv3 可以达到 22ms 的检测速度,获得 28.2mAP 的性能,与 SSD 的准确率相当但是速度快 3 倍。当我们使用旧版.5 IOU mAP 检测指标时,YOLOv3 是非常不错的。它在一块 TitanX 上以 51ms 的速度达到了 57.9 AP_50 的性能,而用 RetinaNet 则以 198ms 的速度获得 57.5 AP_50 的性能,性能相近但快了 3 倍。
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4751.html
摘要:基于候选区域的目标检测器滑动窗口检测器自从获得挑战赛冠军后,用进行分类成为主流。一种用于目标检测的暴力方法是从左到右从上到下滑动窗口,利用分类识别目标。这些锚点是精心挑选的,因此它们是多样的,且覆盖具有不同比例和宽高比的现实目标。 目标检测是很多计算机视觉任务的基础,不论我们需要实现图像与文字的交互还是需要识别精细类别,它都提供了可靠的信息。本文对目标检测进行了整体回顾,第一部分从RCNN...
摘要:我们可以通过在特征图上滑动窗口来检测目标。以前的滑动窗口方法的致命错误在于使用窗口作为最终的边界框,这就需要非常多的形状来覆盖大部分目标。更有效的方法是将窗口当做初始猜想,这样我们就得到了从当前滑动窗口同时预测类别和边界框的检测器。 单次检测器Faster R-CNN 中,在分类器之后有一个专用的候选区域网络。Faster R-CNN 工作流基于区域的检测器是很准确的,但需要付出代价。Fas...
摘要:摘要本文介绍使用和完成视频流目标检测,代码解释详细,附源码,上手快。将应用于视频流对象检测首先打开文件并插入以下代码同样,首先从导入相关数据包和命令行参数开始。 摘要: 本文介绍使用opencv和yolo完成视频流目标检测,代码解释详细,附源码,上手快。 在上一节内容中,介绍了如何将YOLO应用于图像目标检测中,那么在学会检测单张图像后,我们也可以利用YOLO算法实现视频流中的目标检...
摘要:表示类别为,坐标是的预测热点图,表示相应位置的,论文提出变体表示检测目标的损失函数由于下采样,模型生成的热点图相比输入图像分辨率低。模型训练损失函数使同一目标的顶点进行分组,损失函数用于分离不同目标的顶点。 本文由极市博客原创,作者陈泰红。 1.目标检测算法概述 CornerNet(https://arxiv.org/abs/1808.01244)是密歇根大学Hei Law等人在发表E...
摘要:来自原作者,快如闪电,可称目标检测之光。实现教程去年月就出现了,实现一直零零星星。这份实现,支持用自己的数据训练模型。现在可以跑脚本了来自原作者拿自己的数据集训练快速训练这个就是给大家一个粗略的感受,感受的训练过程到底是怎样的。 来自YOLOv3原作者YOLOv3,快如闪电,可称目标检测之光。PyTorch实现教程去年4月就出现了,TensorFlow实现一直零零星星。现在,有位热心公益的程...

阅读 3165·2021-08-03 14:05
阅读 2220·2019-08-29 15:35
阅读 745·2019-08-29 13:30
阅读 3247·2019-08-29 13:20
阅读 2602·2019-08-23 18:15
阅读 1868·2019-08-23 14:57
阅读 2294·2019-08-23 13:57
阅读 1415·2019-08-23 12:10






