
摘要:文和,创意实验室创意技术专家在机器学习和计算机视觉领域,姿势预测或根据图像数据探测人体及其姿势的能力,堪称最令人兴奋而又最棘手的一个话题。使用,用户可以直接在浏览器中运行机器学习模型,无需服务器。
文 / Jane Friedhoff 和 Irene Alvarado,Google 创意实验室创意技术专家
在机器学习和计算机视觉领域,姿势预测或根据图像数据探测人体及其姿势的能力,堪称最令人兴奋而又最棘手的一个话题。近期,Google 公布了 PoseNet,这是一个先进的姿势预测模型,可从图像数据中提取非常精准的姿势数据(即便在图像模糊不清、分辨率低或仅为黑白色的情况下仍能做到)。本文将详细介绍这项实验,正是在该实验的推动下,我们率先创建了这一适用于网页的姿势预测内容库。
几个月前,我们开展了一项名为 Move Mirror 的趣味原型实验:您只需四下走动,即可在浏览器中检索相应图像。该实验创造了一种动画般的独有体验,它会追踪您的动作并据此呈现各种人体动作图像,其中包括体育运动、舞蹈、武术以及表演等多种动作。我们希望在网页上推出这项体验,让其他人也有机会亲身感受,了解机器学习相关知识,然后与好友分享。但遗憾的是,我们面临着一个问题:眼下没有可公开获取的网页专用姿势预测模型。
一般而言,用户在处理姿势数据时需要访问特殊硬件或需要具备 C++/Python 计算机视觉库的相关使用经验。由此,我们发现了一个有助推动姿势预测更加大众化的难得机会,具体方法是将内部模型移植到 TensorFlow.js 中,这是一个 Javascript 库,支持用户在浏览器中运行机器学习项目。我们组建了一支团队,耗费数月来开发这一内容库,并最终推出了 PoseNet 这一开放源代码工具,该工具允许任何网页开发者完全在浏览器内轻松处理人体互动,且无需配备专门的摄像头或具备 C++/Python 技能。
随着 PoseNet 的问世,我们最终得以发布 Move Mirror 项目,该项目可谓实验和趣味游戏提升工程设计工作价值的明证。正是由于研究团队、产品团队 和 创意团队的真诚合作,我们才得以成功构建 PoseNet 和 Move Mirror。

Move Mirror 是一项 AI 实验,能够检测您的姿势,并将检测到的动作与全球成千上万张图像进行匹配
继续阅读,以深入了解我们的实验思路、我们在浏览器中预测姿势时经历的兴奋点,以及令我们甚为激动的后续创意。
什么是姿势预测?什么是 PoseNet?
您或许已猜到,姿势预测是一个极为复杂的问题:人的体型大小各异;需追踪的关节数量众多(这些关节在空间中的连接方式多种多样);周围通常还会有其他人及/或物体遮挡视线。有些人使用轮椅或拐杖等辅助装置,这可能会阻挡摄像头对人体的取像;有些人或许肢体不全,还有些人的身体比例可能与常人迥然不同。我们希望,我们的机器学习模型能够理解并推理各类不同体型的数据。


此图显示 PoseNet 针对不同辅助装置(如手杖、轮椅和假肢)的使用者给出的关节检测结果
过去,在解决姿势预测问题时,技术专家曾使用专门的摄像头和传感器(如 3D 眼镜、动作捕捉套装和红外摄像头),以及可从 2D 图像中提取预测姿势的计算机视觉技术(如 OpenPose)。这些解决方案尽管有效,但往往需要采用昂贵而又远未普及的技术,并且/或者要熟知计算机视觉库以及 C++ 或 Python。这加大了普通开发者迅速开展趣味姿势实验的难度。
首次使用 PoseNet 时,发现它可通过简单的 web API 获取,这让我们无比激动。突然间,我们就可以在 Javascript 中轻松迅速地开展姿势预测原型实验了。我们只需向内部终端地址发送 HTTP POST 请求以及图像的 base64 数据,API 终端地址便会为我们返回姿势数据,而且几乎没有任何延迟时间。这大大降低了开展小型探索性姿势实验的准入门槛:只需寥寥几行 JavaScript 代码和一个 API 密钥,即可大功告成!当然,并非人人都能够在后端运行自己的 PoseNet,而且(按常理)并非人人都愿意将自己的照片发送到中央服务器。我们如何才能让人们有可能运行自己的姿势实验,而不必依赖自己或他人的服务器呢?
我们意识到,这是将 TensorFlow.js 与 PoseNet 相连接的绝佳机会。使用 TensorFlow.js,用户可以直接在浏览器中运行机器学习模型,无需服务器。将 PoseNet 移植到 TensorFlow.js 后,只要用户拥有一部质量尚可且配备网络摄像头的桌面设备或电话,便可直接在网络浏览器内亲身体验并尝试使用这项技术,而无需担心低级计算机视觉库, 亦 无需设置复杂的后端和 API。通过与 TensorFlow.js 团队的 Nikhil Thorat 和 Daniel Smilkov、Google 研究员 George Papandreou 和 Tyler Zhu,以及 Dan Oved 展开密切协作,我们已能将某个 PoseNet 模型版本移植到 TensorFlow.js 中。(您可以在此处了解该流程的详细信息。)
关于在 TensorFlow.js 中使用 PoseNet,还有一些方面也让我们感到非常兴奋:
无处不在/随地获取:大多数开发者均能访问文本编辑器和网络浏览器,而且 PoseNet 使用起来非常简便,只需在您的 HTML 文件中添加两个脚本标记即可,无需进行复杂的服务器设置。此外,您无需配备专门的高分辨率摄像头、红外摄像头或传感器来获取数据。我们发现,其实 PoseNet 在处理低分辨率、黑白以及老旧照片时依然表现良好。
可供分享:TensorFlow.js PoseNet 实验可全部在浏览器中运行,因此您不费吹灰之力,即可在浏览器中分享该实验。无需构建特定的操作系统版本,只需上传网页即可。
隐私性:由于姿势预测的全部工作均可在浏览器中完成,因此您的所有图像数据均会留存在本地计算机中。您无需将照片发送至某个云端服务器以利用集中式服务开展姿势分析(例如,当您使用自己无法控制的视觉 API 时,或此 API 可能发生故障,或存在任何不可控因素时),只需使用自身设备即可完成所有的姿势预测工作,并能较精确控制图像的移动位置。借助 Move Mirror,我们可以将 PoseNet 输出的 (x,y) 关节数据与后端的姿势图库进行匹配,但您的图像仍会完全留存在您自己的计算机中。
技术讨论到此结束:下面我们来谈谈设计!
设计与灵感
我们曾耗费数周时间,四处摸索不同的姿势预测原型。对于我们当中有过 C++ 或 Kinect 黑客行为的人来说,仅仅是使用网络摄像头在浏览器中看到我们的骨骼 反射回自身,就足以称得上是令人惊叹的演示。我们在对移动轨迹、木偶以及其他各类易于操控的物件进行过试验之后,才开始真正着眼于后来的 Move Mirror 概念。
若听到 Google 创意实验室的许多研究员都有意进行搜索和探究,这也许不足为奇。在谈及姿势预测的用途时,我们都觉得通过姿势搜索归档数据的想法十分有趣。如果您在摆出姿势后,得到一个您在做舞蹈动作的结果,会怎么样?或者更有趣的是,您在摆出姿势后得到一个相同的动作结果,但该结果却与您所处情境完全不同,又会怎么样?从武术、烹饪、滑雪到婴儿的第一次学步,我们如何从纷繁多样的人体活动中找到这种古怪、偶然的联系呢?这会如何让我们大吃一惊、愉悦享受,并开怀大笑呢?

出自 Awwwards 的 Land Lines Gif;出自 Cooper Hewitt 的 Gesture Match 图像
我们的灵感源自于 Land Lines(该实验会使用手势数据探索 Google 地球中的相似线条)和 Cooper Hewitt 的 Gesture Match(这是一个现场安置项目,可通过姿势匹配从归档数据中查找相应条目)等项目。不过,从美学上来看,我们倾向于采用更迅速且更实时的方式。我们热衷这一想法,即调用连续不断的图像来响应您的动作,并通过您的动作将各行各业的人们联系在一起。从 The Johnny Cash 项目中所用的转描和缩时摄影技术得到启发,再加上 YouTube 上自拍缩时摄影趋势的推动,我们决定铆足干劲,着力在浏览器中实现实时响应式姿势匹配(尽管这本身就是一个十分复杂的问题)。

The Johnny Cash 项目生成的 Gif,在此项目中已有超过 250000 人为 “Ain’t No Grave” 这首歌描画框架,制作众包的音乐视频
构建 Move Mirror
尽管 PoseNet 会为我们作出姿势预测,但我们仍有许多任务要完成。这项实验的核心体验全部在于寻找与用户姿势相匹配的图像,如此,当您直立且右臂上扬时,Move Mirror 便能找到某人站立且抬起右臂的图像。为此,我们需要做好三项准备:图像数据集、搜索该数据集的技术和姿势匹配算法。下面我们来逐一细谈。
构建数据集:搜索多样图片
要创建有用的数据集,我们必须搜索共同涵盖海量人体动作的图像。如果数据集中未包含其他姿势,而只有 400 张举起右臂直立的人体图像,这将毫无意义。为确保提供始终如一的体验,我们还决定只寻找全身图像。最终,我们出品了系列视频,在我们看来,这些视频不仅代表着各类动作,而且还涵盖各种体型、肤色、文化特质和身体能力。我们将这些视频分为大约 80000 个静止帧,然后使用 PoseNet 处理了每张图像,并存储了相关的姿势数据。接下来,我们来探讨最棘手的部分:姿势匹配与搜索。
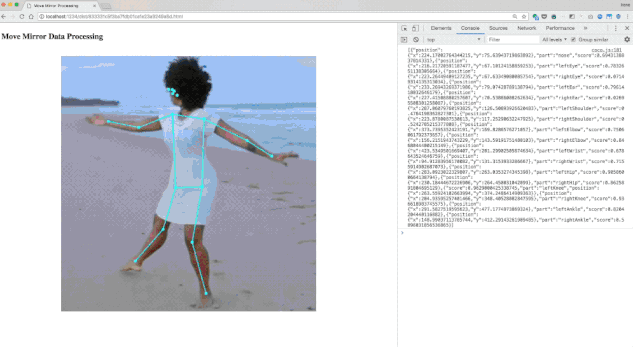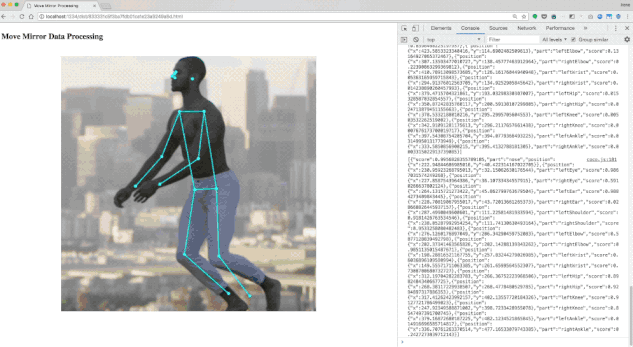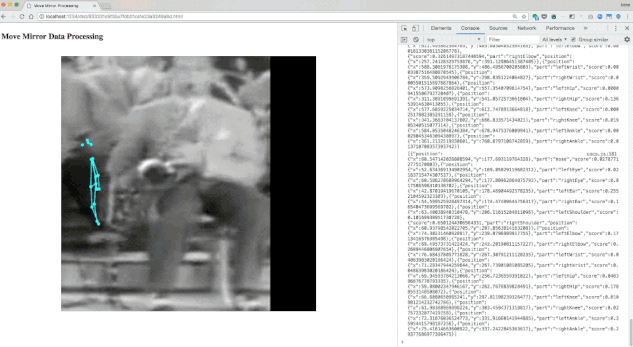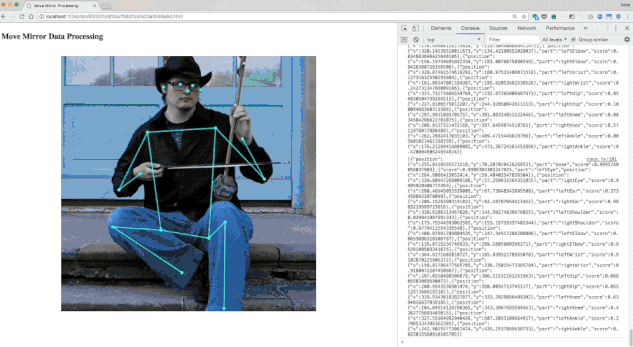
我们通过 PoseNet 解析了数千张图像。您会发现,并非所有图像都解析正确,因此我们舍弃了一些,最终得到的数据集约包含 80000 张图像
姿势匹配:定义相似性时遇到的挑战
要让 Move Mirror 正常运作,我们首先要明确该如何定义“匹配”。“匹配”指的是当用户摆出一个姿势时,我们根据接收到的姿势数据返回的图像。在谈及由 PoseNet 生成的“姿势数据”时,我们指的是一组包含 17 个身体或面部部位的数据,例如我们称为“关键点”的肘部或左眼部位。PoseNet 会返回输入图像中每个关键点的 x 和 y 坐标,以及相应的置信度得分(稍后会详细介绍)。
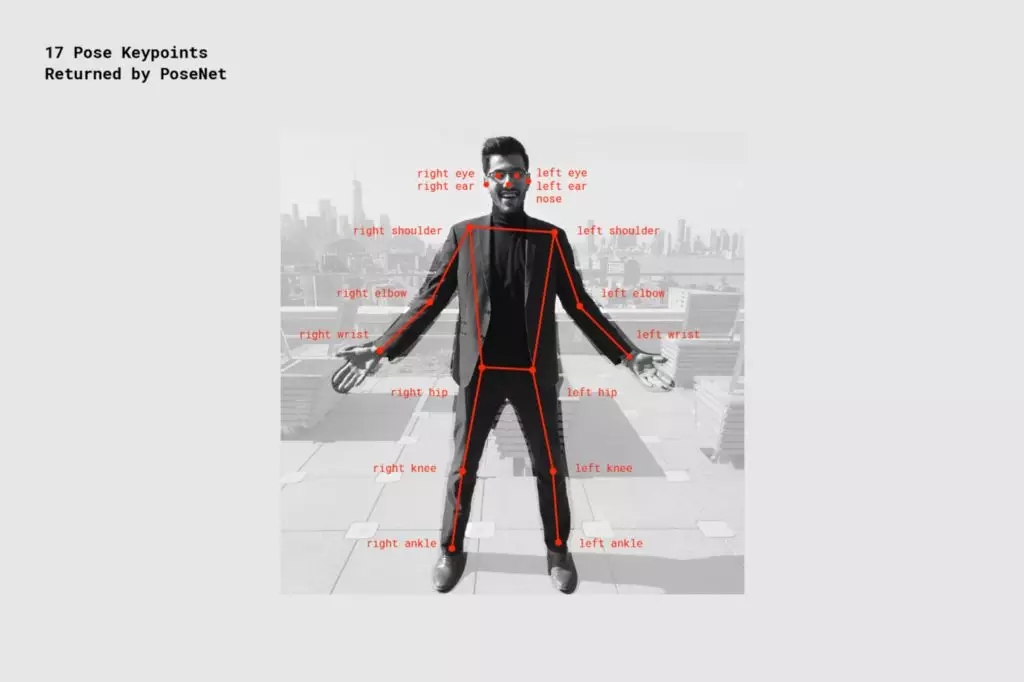
PoseNet 会检测面部和身体的 17 个姿势关键点。每个关键点均包括三个重要的数据块:(x,y) 坐标(代表输入图像中 PoseNet 找到该关键点的像素位置)和置信度得分(PoseNet 认为其猜测正确的信心度)
定义 “相似度” 是我们遇到的第一个难题。对于用户的 17 个关键点数据组与数据集中图像的 17 个关键点数据组,我们应如何确定二者之间的相似度?我们尝试了几种不同方法来确定相似度,最终敲定了两种有效方式:余弦相似度和结合关键点置信度得分得出的加权匹配。
匹配策略 #1:余弦距离
如果我们将每组的 17 个关键点数据转换为一个向量,并将其标绘在高维空间中,那么寻找两个最相似姿势的任务便会转化为在此高维度空间中寻找两个最接近的向量。这就是余弦距离的用途所在。
余弦相似度是一种测量两个向量之间相似度的方法:主要测量两个向量的夹角,在向量指向完全相反时返回 -1,而在指向几乎完全相同时则返回 1。重要的是,这种方法测量的是方向而非数值。
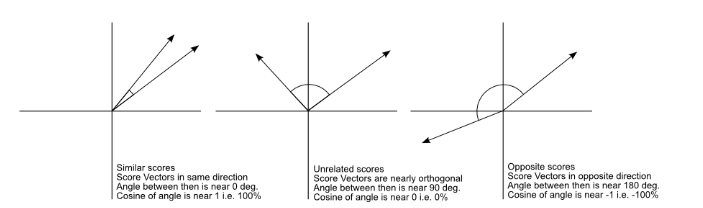
余弦相似度的直观描述,出自 Christian Perone
虽然我们现在谈论的是向量和角度,但这并不限于图表上的线条。例如,您可以使用余弦相似度来获得两个等长字符串之间的数值相似度。(如果您以前使用过 Word2Vec,可能已间接用到余弦相似度。)这一方法的确非常实用,能够将两个高维向量(两个长句或两个长数组)之间的关系最终简化为一个单一数值。

Nish Tahir 典型示例 简化版。 不懂向量数学也无妨,重点在于我们能够将两个抽象的高维数据块(5 个字词为 5 维)转化为一个表示二者相似度的归一化数值。这里,您也可以尝试使用 自己的语句
我们输入的数据是 JSON,但我们可以将这些值轻松压缩为一维数组,其中每个条目均象征着某一个关键点的 X 或 Y 坐标。只要我们的结构保持统一并且可预测,便能以相同的方式对生成的数组展开比较。这就是我们的第一步:将物体数据变为数组。

源自 PoseNet 的 JSON 数据片段,以及包含 X 和 Y 坐标的扁平化数组的数据片段。(您会发现该数组并未考虑到置信度,我们稍后会回到这个话题!)
这样,我们就可以使用余弦相似度来求得所输入的 34 位浮点数组与数据库中任何给定的 34 位浮点数组之间的相似度测量值。我们偶尔也可输入两个长数组,然后获得更易解析的相似度得分(介于 -1 与 1 之间)。
由于数据集中所有图像的宽度/高度各不相同,且每个人还会出现在不同的图像子集(左上、右下或中央子集等)中,因此我们额外执行了两个步骤,以便能对数据作出一致比较:
调整尺寸与缩放:我们根据每个人的边界框坐标来将每张图像(以及相应的关键点坐标)裁剪并缩放至同等尺寸。
归一化:我们将得到的关键点坐标视为 L2 归一化向量数组,将其进一步归一化。
具体而言,我们使用 L2 归一化来进行第二步,这表示我们要将向量缩放为单位范数(如果将 L2 归一化向量中的每个元素进行一致化处理并对其求和,所得结果将为 1)。比较这些图表,即可了解归一化对向量的转换方式:
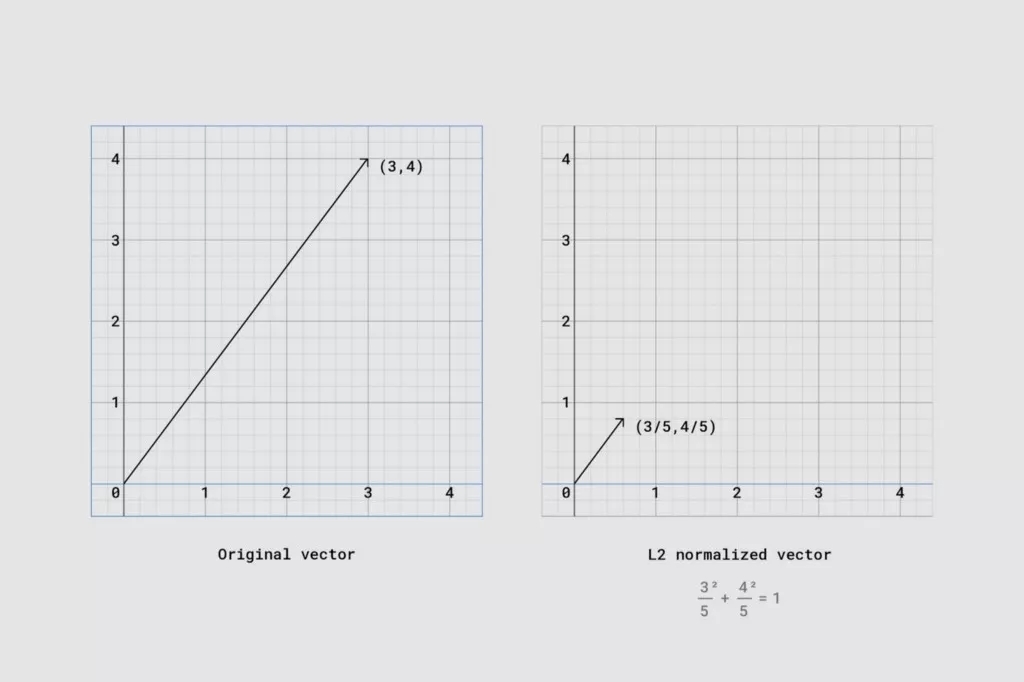
利用 L2 归一化缩放的向量
对上述两个步骤可作如下直观考虑:

Move Mirror 数据归一化步骤
使用归一化处理后的关键点坐标(以向量数组形式存储),我们最终可计算出余弦相似度并执行若干计算(下文将详细介绍),从而得出一个可解释为余弦距离的欧几里得距离。计算公式如下所示:

在以上公式中,Fxy 与 Gxy 表示经 L2 归一化处理后可供比较的两个姿势向量。此外,Fxy 和 Gxy 仅包含 17 个关键点的 X 和 Y 坐标,并不包含每个关键点的置信度得分。
JavaScript 要点如下所示:
一目了然,对吧?开始匹配吧!
匹配策略 #2:加权匹配
好吧,其实这种方法仍存在很大缺陷。上例中,我们在计算余弦相似度时使用了两个句子:“Jane likes to code” 和 “Irene likes to code”,这两句话是静态的:我们已就二者表示的含义得出了 100% 的置信度。但姿势预测并非如此索然无味。事实上,我们在努力推断关节位置时,几乎从未得出 100% 的置信度。我们也能做到十分接近,但除非变成 X 光机,否则我们很难较精确达到 100% 的置信度。有时,我们也会完全看不到关节,只能根据获知的其他人体信息作出较佳猜测。

Posenet 会返回每个关键点的置信度得分。该模型预测关键点的置信度得分越高,结果就会越准确
由此,每个返回的关节数据块也会有置信度得分。有时,我们非常自信能够确定关节的位置(例如当我们可以清楚看到关节时);但有些时候,我们的置信度会很低(例如当关节被拦断或出现遮挡时),以至必须为数值附带一个大大的耸肩表情符号来当做挡箭牌。如果忽视这些置信度得分,我们便会丧失与自身数据相关的重要数据,并可能对实际置信度较低的数据赋予过多权重和重要性。这会产生干扰,最终导致匹配结果十分怪异,看似杂乱无章。
因此,倘若余弦距离法较为实用且能产生良好结果,我们觉得纳入对置信度得分(PoseNet 正确预计关节所在位置的概率)的考量将能进一步提升结果的准确度。具体而言,我们希望能对关节数据进行加权,以确保低置信度关节对距离指标的影响低于高置信度关节。Google 研究员 George Papandreou 和 Tyler Zhu 合力研究出了一个能够准确进行此类加权计算的公式:
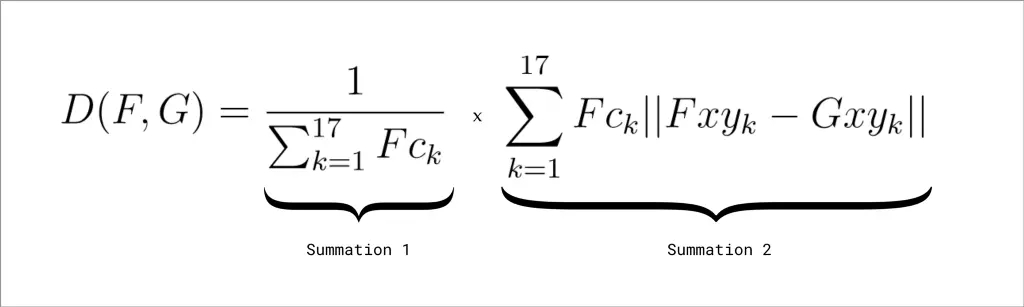
在以上公式中,F 和 G 表示经 L2 归一化处理后可供比较的两个姿势向量(已在前文中有过说明)。Fck 表示 F 的 kth 关键点的置信度得分。Fxy 和 Gxy 表示每个向量的 kth 关键点的 x 和 y 坐标。不理解整个公式也无妨,重点在于您要理解我们需使用关键点置信度得分来改善匹配结果。以下 Javascript 要点可能会更清晰地说明这一点:
这一策略可为我们提供更准确的结果。即使人体被遮挡或位于框架之外,我们也能借助该策略更准确地找到与用户所做动作相似的姿势图像。




Move Mirror 尝试根据 PoseNet 预测的姿势来寻找匹配图像。匹配准确度取决于 PoseNet 的准确度和数据集的多样性。
大规模搜索姿势数据:约在 15 毫秒内搜索 80000 张图像
最后,我们必须设法弄清如何进行大规模搜索和匹配。首先,我们可以轻松进行暴力匹配:在对输入姿势与包含 10 种姿势的数据库中的每个条目进行比较时,毫不费力。但显而易见,10 张图像远远不够:为涵盖各类人体动作,我们至少需要数万张图像。您也许已经预料到,对包含 80000 张图像的数据库中的每个条目运行距离函数,将无法生成实时结果!因此,我们的下一个难题就是设法弄清如何快速推导可以跳过的条目以及真正相关的条目。我们能够确信跳过的条目越多,返回匹配结果的速度就会越快。
我们从 Zach Lieberman 和 Land Lines 实验中得到启发,并采用了一种名为 “制高点树” 的数据结构(前往此处查看 Javascript 库)来遍历姿势数据。制高点树以递归方式将数据划分为两类:一类为比阈值更临近某个制高点的数据,另一类为比阈值相距更远的数据。这一递归分类创造了一个可供遍历的树形数据结构。(如果您熟知制高点树,便会发现它与 K-D 树有些类似。您可以在此处了解制高点树的更多相关信息。)
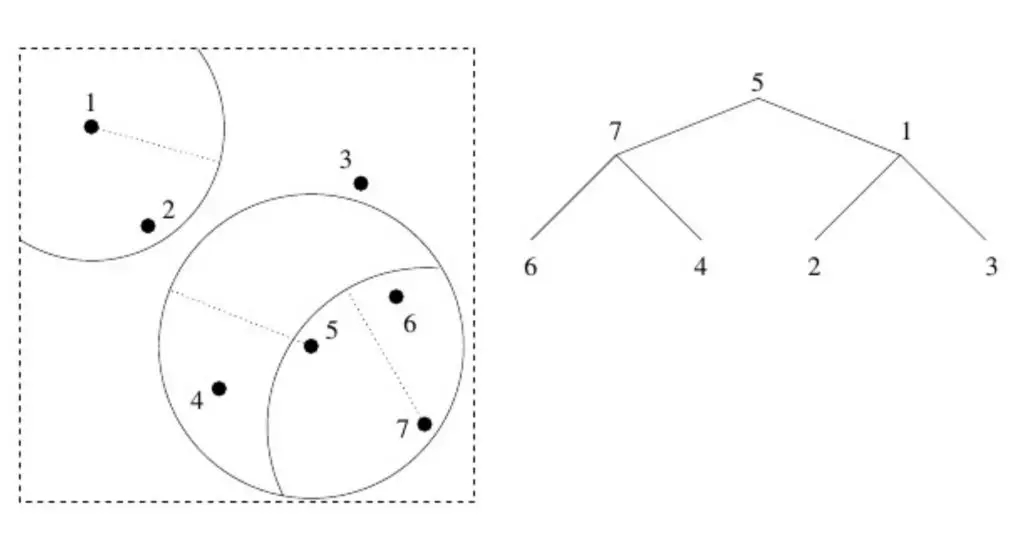
下面我们来深入探讨一下 vp 树。不能完全理解下文描述也无妨,重点是要理解大致原理。我们的数据空间中包含一组数据点,从中选择一个数据点(可随机选择!)作为我们的制高点(上图中选择的是数据点 5)。以该数据点为圆心画一个圆,这样便可看到部分数据位于圆内,部分位于圆外。然后,我们再选择两个新的制高点:一个位于圆内,另一个位于圆外(此处分别选择了数据点 1 和 7)。我们将这两个数据点作为子数据点添加到第一个制高点中。之后,我们对这两个数据点执行如下相同操作:分别以两个数据点为圆心画圆,在两圆内外各选一个数据点,然后将这些制高点用作它们的子数据点,以此类推。关键在于,如果您起初选择数据点 5,之后发现数据点 7 要比 1 更接近您想要的位置,此时不仅可以舍弃数据点 1,还能舍弃其子数据点。
使用此树形结构,我们就不必再去逐一比较每个条目:如果输入的姿势与制高点树中某个节点的相似度不够,我们便可设想该节点的所有子节点均不会达到足够的相似度。如此,我们便无需暴力搜索数据库中的所有条目,而只需通过遍历制高点树来进行搜索,这样我们就能够安全、安心地舍弃数据库中不相关的巨大数据列。
制高点树有助我们大幅提升搜索结果的速度,同时还可打造我们向往的实时体验。尽管制高点树应用起来困难重重,但其使用体验之奇妙一如我们所望。
如果您想亲自尝试这些方法,可参考我们在使用 Javascript 库 vptree.js 构建 vp 树时所用的 Javascript 代码要点。在本例中,我们使用了自有的距离匹配函数,不过,我们也建议您去探索并尝试其他可能的方法,只需在构建时替换传输到 vp 树的距离函数即可。
在 Move Mirror中,我们最终只使用了最邻近的图像来匹配用户姿势。但如果是调试,我们实际可以遍历制高点树,并找到最邻近的 10 张或 20 张图像。事实上,我们构建了一个调试工具来以这种方式探索数据,而且该工具还能协助我们十分高效地探索数据集的漏洞。

使用我们的调试工具后,生成的图像会按照相似度由高至低的顺序进行分类(依上述算法确定)
开发环境搭建
当看到自己的动作在游泳者、厨师、舞者和婴儿身上再现时,我们会觉得乐趣十足。此外,这项技术还能为我们带来更多其他乐趣。想像一下,无论是搜索各类舞蹈动作、经典电影片段还是音乐短片,一切都可在您的私人客厅(甚至是您的私人浏览器)中完成。换个角度考虑,您还可利用姿势预测协助指导居家瑜伽锻炼或物理治疗。Move Mirror 只是一项小小实验,我们希望它能引领浏览器内的姿势预测实验遍地开花,让大众畅享无穷乐趣。
声明:文章收集于网络,如有侵权,请联系小编及时处理,谢谢!
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4802.html
摘要:反馈检测到的每个人的置信度值以及检测到的每个姿势关键点。姿势置信度这决定了姿势判断的整体置信度。在较高级别,这将控制回馈的姿势较低置信度分数。只有在调整姿势置信度得分不够好的情况下,为了过滤掉不太准确的姿势,该数值应该增加或减少。 文 / Dan Oved,Google Creative Lab 的自由创意技术专家,纽约大学 ITP 的研究生。编辑和插图 / 创意技术专家 Irene Alv...
摘要:年后的你长什么样北京航空航天大学和密歇根州立大学的研究人员设计了一个系统,采用生成对抗网络,可以根据原始照片生成一个人年龄增长后的样子,甚至连发际线逐渐后移也能逼真地模拟。 20年后的你长什么样?北京航空航天大学和密歇根州立大学的研究人员设计了一个AI系统,采用生成对抗网络(GAN),可以根据原始照片生成一个人年龄增长后的样子,甚至连发际线逐渐后移也能逼真地模拟。论文发表在CVPR 2018...
摘要:最近,这就是街舞第二季开播,又一次燃起了全民热舞的风潮。然而,真要自己跳起来,实际与想象之间,估计差了若干个罗志祥。系统映射结果展示对于系统的结果,研究人员表示还不完美。谷歌在和跳舞的结合上也花了心思。好了,先不说了,我要去跟学跳舞了。 最近,《这!就是街舞》第二季开播,又一次燃起了全民热舞的风潮。 刚开播没多久,这个全程高能的节目,就在豆瓣上就得到了 9.6 的高分。舞者们在比赛中精...
摘要:感谢像这样的框架,使得这些数据集可以应用于机器学习领域。蓝点被标记为坏球,橙点被标记为好球标注来自大联盟裁判员使用构建模型将机器学习带入和领域。使用库将预测结果呈现为热图。好球区域位于本垒板上方至英尺之间。 在这篇文章中,我们将使用TensorFlow.js,D3.js和网络的力量来可视化训练模型的过程,以预测棒球数据中的坏球(蓝色区域)和好球(橙色区域)。在整个训练过程中,我们将一步...

阅读 1554·2021-11-22 15:25
阅读 3588·2021-10-21 09:38
阅读 1789·2021-10-19 13:21
阅读 1217·2021-09-06 15:00
阅读 1893·2019-08-30 15:44
阅读 2769·2019-08-29 15:40
阅读 3823·2019-08-29 13:44
阅读 2328·2019-08-26 16:56





