
摘要:是为了大规模分布式训练和推理而设计的,不过它在支持新机器学习模型和系统级优化的实验中的表现也足够灵活。本文对能够同时兼具规模性和灵活性的系统架构进行了阐述。尽管大多数训练库仍然只支持,但确实能够支持有效的推理。
TensorFlow 是为了大规模分布式训练和推理而设计的,不过它在支持新机器学习模型和系统级优化的实验中的表现也足够灵活。
本文对能够同时兼具规模性和灵活性的系统架构进行了阐述。设定的人群是已基本熟悉 TensorFlow 编程概念,例如 computation graph, operations, and sessions。有关这些主题的介绍,请参阅
https://tensorflow.google.cn/guide/low_level_intro?hl=zh-CN。如已熟悉 Distributed TensorFlow,本文对您也很有帮助。行至文尾,您应该能了解 TensorFlow 架构,足以阅读和修改核心 TensorFlow 代码了。
概览
TensorFlow runtime 是一个跨平台库。图 1 说明了它的一般架构。 C API layer 将不同语言的用户级代码与核心运行时分开。
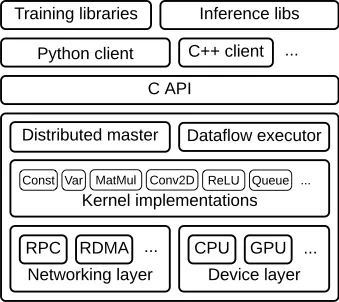
图 1
本文重点介绍以下几个方面:
客户端:
将整个计算过程转义成一个数据流图
通过 session,启动图形执行
分布式主节点
基于用户传递给 Session.run() 中的参数对整个完整的图形进行修剪,提取其中特定子图
将上述子图划分成不同片段,并将其对应不同的进程和设备当中
将上述划分的片段分布到 worker services 工作节点服务上
每个 worker services 工作节点服务上执行其收到的图形片段
工作节点服务 Worker Services (每一任务一个)
使用内核实现来计划图形表示的计算部分分配给正确的可用硬件(如 cpu,gpu 等)
与其他工作节点服务 work services 相互发送和接收计算结果
内核实现
执行单个图形操作的计算部分
图 2 说明了这些组件的相互作用。“/ job:worker / task:0” 和 “/ job:ps / task:0” 都是工作节点服务 worker services 上执行的任务。“PS” 表示 “参数服务器”:负责存储和更新模型参数。其他任务在迭代优化参数时会对这些参数发送更新。如果在单机环境下,上述 PS 和 worker 不是必须的,不需要在任务之间进行这种特定的分工,但是对于分布式训练,这种模式就是很常见的。

图 2
请注意,分布式主节点 Distributed Master 和工作节点服务 Worker Service 仅存在于分布式 TensorFlow 中。TensorFlow 的单进程版本包含一个特殊的 Session 实现,它可以执行分布式主服务器执行的所有操作,但只与本地进程中的设备进行通信。
下面,通过逐步处理示例图来详细介绍一下 TensorFlow 核心模块。
客户端
用户在客户端编写 TensorFlow 程序来构建计算图。该程序可以直接组成多带带的操作,也可以使用 Estimators API 之类的便利库来组合神经网络层和其他更高级别的抽象概念。TensorFlow 支持多种客户端语言,我们优先考虑 Python 和 C ++,因为我们的内部用户最熟悉这些语言。随着功能的日趋完善,我们一般会将它们移植到 C ++,以便用户可以从所有客户端语言优化访问。尽管大多数训练库仍然只支持 Python,但 C ++ 确实能够支持有效的推理。
客户端创建会话,该会话将图形定义作为 tf.GraphDef 协议缓冲区发送到分布式主节点。当客户端评估图中的一个或多个节点时,评估会触发对分布式主节点的调用以启动计算。
在图 3 中,客户端构建了一个图表,将权重(w)应用于特征向量(x),添加偏差项(b)并将结果保存在变量中。

图 3
代码:
tf.Session
分布式主节点 Distributed master
分布式主节点:
基于客户端指定的节点,从完整的图形中截取所需的子图
对图表进一步进行划分,使其可以将每个图形片段映射到不同的执行设备上
以及缓存这些划分好的片段,以便在后续步骤中再次使用
由于主节点可以总揽步骤计算,因此它可以使用标准的优化方法去做优化,例如公共子表达式消除和常量的绑定。然后,对一组任务中优化后的子图或者片段执行协调。
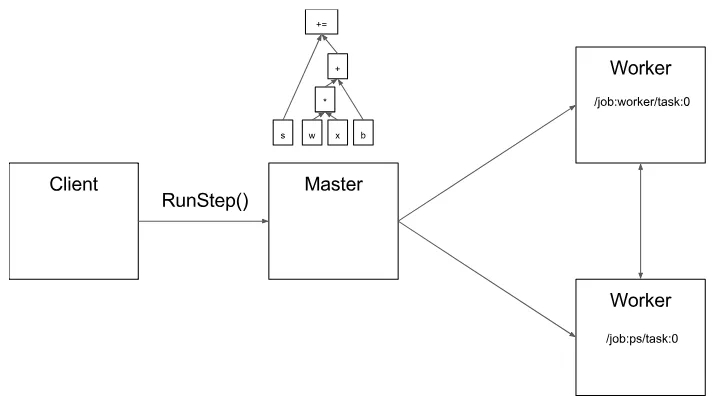
图 4
图 5 显示了示例图的可能分区。分布式主节点已对模型参数进行分组,以便将它们放在参数服务器上。
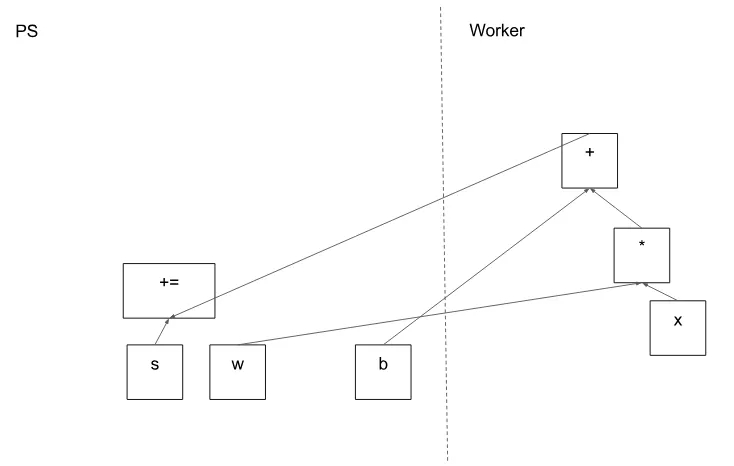
图 5
在分区切割图形边缘的情况下,分布式主节点插入发送和接收节点以在分布式任务之间传递信息(图 6)。
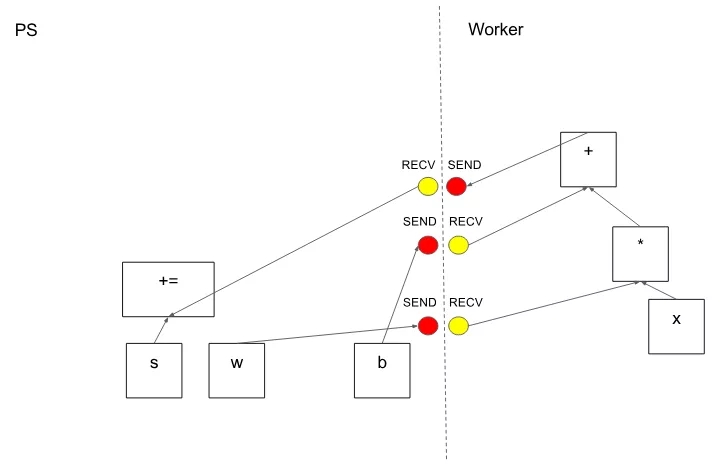
图 6
然后,分布式主节点将图形片段传送到分布式任务。

图 7
代码:
MasterService API definition
Master interface
工作节点服务 Worker Service
在每个任务中,该部分负责:
处理来自 master 发来的请求
为包含本地子图规划所需要的内核执行
协调与其他任务之间的直接信息交换
我们优化了 Worker Service,以便其以较低的负载便能够运行大型图形。当前的版本可以执行每秒上万个子图,这使得大量副本可以进行快速的,细粒度的训练步骤。Worker service 将内核分派给本地设备并在可能的情况下并行执行内核,例如通过使用多个 CPU 内核或者 GPU 流。
我们还特别针对每对源设备和目标设备类型的 Send 和 Recv 操作进行了专攻:
使用 cudaMemcpyAsync() 来进行本地 CPU 和 GPU 设备之间的重叠计算和数据传输
两个本地 GPU 之间的传输使用对等 DMA,以避免通过主机 CPU 主内存进行高负载的复制
对于任务之间的传输,TensorFlow 使用多种协议,包括:
gRPC over TCP
融合以太网上的 RDMA
另外,我们还初步支持 NVIDIA 用于多 GPU 通信的 NCCL 库,请参阅:
tf.contrib.nccl
(https://tensorflow.google.cn/api_docs/python/tf/contrib/nccl?hl=zh-CN)。

图8
代码:
WorkerService API definition
Worker interface
Remote rendezvous (for Send and Recv implementations)
内核运行
该运行时包含了 200 多个标准操作,其中涉及了数学,数组,控制流和状态管理等操作。每个操作都有对应各种设备优化后的内核运行。其中许多操作内核都是通过使用 Eigen::Tensor 实现的,它使用 C ++ 模板为多核 CPU 和 GPU 生成高效的并行代码;但是,我们可以自由地使用像 cuDNN 这样的库,就可以实现更高效的内核运行。我们还实现了 quantization 量化,可以在移动设备和高吞吐量数据中心应用等环境中实现更快的推理,并使用 gemmlowp 低精度矩阵库来加速量化计算。
如果用户发现很难去将子计算组合,或者说组合后发现效率很低,则用户可以通过注册额外的 C++ 编写的内核来提供有效的运行。例如,我们建议为一些性能的关键操作注册自己的融合内核,例如 ReLU 和 Sigmoid 激活函数及其对应的梯度等。XLA Compiler 提供了一个实验性质的自动内核融合实现。
代码:
OpKernel interface
声明:文章收集于网络,如有侵权,请联系小编及时处理,谢谢!
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4857.html
摘要:在两个平台三个平台下,比较这五个深度学习库在三类流行深度神经网络上的性能表现。深度学习的成功,归因于许多层人工神经元对输入数据的高表征能力。在年月,官方报道了一个基准性能测试结果,针对一个层全连接神经网络,与和对比,速度要快上倍。 在2016年推出深度学习工具评测的褚晓文团队,赶在猴年最后一天,在arXiv.org上发布了的评测版本。这份评测的初版,通过国内AI自媒体的传播,在国内业界影响很...
摘要:本报告面向的读者是想要进入机器学习领域的学生和正在寻找新框架的专家。其输入需要重塑为包含个元素的一维向量以满足神经网络。卷积神经网络目前代表着用于图像分类任务的较先进算法,并构成了深度学习中的主要架构。 初学者在学习神经网络的时候往往会有不知道从何处入手的困难,甚至可能不知道选择什么工具入手才合适。近日,来自意大利的四位研究者发布了一篇题为《神经网络初学者:在 MATLAB、Torch 和 ...
摘要:而道器相融,在我看来,那炼丹就需要一个好的丹炉了,也就是一个优秀的机器学习平台。因此,一个机器学习平台要取得成功,最好具备如下五个特点精辟的核心抽象一个机器学习平台,必须有其灵魂,也就是它的核心抽象。 *本文首发于 AI前线 ,欢迎转载,并请注明出处。 摘要 2017年6月,腾讯正式开源面向机器学习的第三代高性能计算平台 Angel,在GitHub上备受关注;2017年10月19日,腾...
摘要:在嵌入式系统上的深度学习随着人工智能几乎延伸至我们生活的方方面面,主要挑战之一是将这种智能应用到小型低功耗设备上。领先的深度学习框架我们来详细了解下和这两个领先的框架。适用性用于图像分类,但并非针对其他深度学习的应用,例如文本或声音。 在嵌入式系统上的深度学习随着人工智能 (AI) 几乎延伸至我们生活的方方面面,主要挑战之一是将这种智能应用到小型、低功耗设备上。这需要嵌入式平台,能够处理高性...

阅读 3666·2021-11-25 09:43
阅读 2892·2021-09-22 15:54
阅读 720·2019-08-30 15:55
阅读 1117·2019-08-30 15:55
阅读 2179·2019-08-30 15:55
阅读 1872·2019-08-30 15:53
阅读 3655·2019-08-30 15:52
阅读 2205·2019-08-30 12:55





