
摘要:而自然语言处理被视为深度学习即将攻陷的下一个技术领域,在今年全球较高级的学术会议上,我们也看到大量的在深度学习引入方面的探索研究。和也是近几年暂露头角的青年学者,尤其是在将深度学习应用于领域做了不少创新的研究。
深度学习的出现让很多人工智能相关技术取得了大幅度的进展,比如语音识别已经逼近临界点,即将达到Game Changer水平;机器视觉也已经在安防、机器人、自动驾驶等多个领域得到应用。 而自然语言处理(NLP)被视为深度学习即将攻陷的下一个技术领域,在今年全球较高级的NLP学术会议ACL上,我们也看到大量的在深度学习引入NLP方面的探索研究。让我们跟随阿里的科学家们一起去探求深度学习给NLP带来些改变。
一、会议概要
ACL2016于2016年8月7日至12日在德国柏林洪堡大学召开,本届参会人数在1200人左右。其中,8月7日是Tutorial环节,8月8日-10日是正会,8月11日-12日是若干主题的workshop。本届ACL2016 Lifetime AchievementAward winner是来自斯坦福的Joan Bresnan教授,词汇功能文法的奠基人。

参会的阿里巴巴同学们
二、Tutorial总结
1、《Computer Aided Translation》
这个tutorial的报告人是约翰霍普金斯大学的Philipp Koehn教授,他是统计机器翻译领域的领军学者之一,在基于短语的机器翻译模型方面做了很多影响深远的工作,主持了著名的开源统计机器翻译系统Moses的开发。最近几年,Koehn教授重点关注如何借助机器翻译技术来帮助译员如何更有效率地完成翻译工作,即计算机辅助翻译技术(CAT),并得到了欧盟CASMACAT项目资助,这个tutorial也算是整个CASMACAT项目的总结。在这个报告中,Koehn介绍了在这个项目中开发的一系列新的CAT技术及其实际效果。与在线术语库、记忆库、译后编辑等传统手段不同,CASMACAT结合了SMT的大量研究成果,例如置信分(confidence score)、复述(paraphrasing)、可视化词对齐(visualization of word alignment)、翻译选项阵列(translationoption array)等,为译员提供了更加丰富的信息,从而为辅助翻译提供了更好的灵活性。
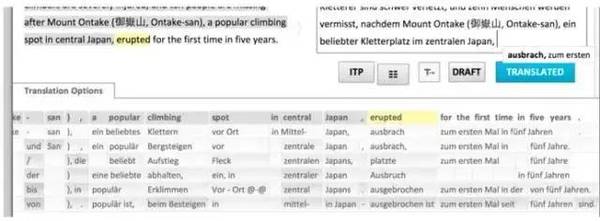
图1、翻译选项阵列
这个项目实现了一套完整的在线CAT系统(CASMACAT),通过对大量译员的实际使用情况进行数据统计,并结合眼部跟踪(eye tracking)等认知分析,证明这些新的CAT方法的确能够提升译员的工作效率,提升产出。
总体上,这个报告的内容属于比较偏应用型的工作,学术上的创新工作不多,因此受到的关注不如其它学术性报告多,但它是一个非常完整的实用性工作,通过把机器翻译的新技术与CAT场景进行创新的结合,并通过大量真实用户的使用验证这些技术的有效性。
2、《NeuralMachine Translation》
这个tutorial的报告人是斯坦福大学的Christopher Manning教授、他的博士生Thang Luong以及纽约大学的助理教授Kyunghyun Cho。Manning教授在NLP领域的影响力非常大,是统计NLP领域的领军学者之一,最近几年也逐渐转向深度学习,在递归神经网络、句法分析、词向量、神经机器翻译等领域做了很多开创性工作。Luong和Cho也是近几年暂露头角的青年学者,尤其是在将深度学习应用于NLP领域做了不少创新的研究。
这个tutorial对目前神经机器翻译的研究进展做了一个阶段性的总结。虽然NMT真正开始兴起的时间不到3年(大致从2013年Kalchbrenner和Blunsum发表《Recurrent continuous translation models》开始算起),但迅速在研究界掀起了新的热潮,并取得了巨大进展,在一些语言上的效果已经超越了传统的方法。报告首先回顾了最近20年占统治地位的SMT方法,然后介绍了几年之前将神经网络作为新特征集成到传统解码器的思路,接下来重点介绍了大家非常关注的端到端的神经机器翻译(End2end NMT)。报告中以一个具体的NMT实现为例,详细描述了一个NMT的序列到序列框架及相关的较大似然估计和beam-search解码过程。报告最后描述了NMT研究近期的发展趋势,包括引入LSTM和attention机制,以及如何通过sub-word或基于字符解码来尽量减少受限词表对最后翻译效果的影响等。
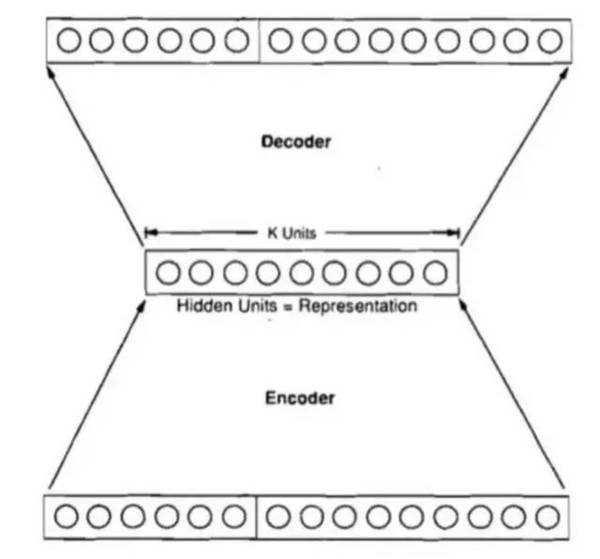
图2、一个典型的encoder-decoderNMT框架
总的来说,这个报告对于我们更好理解NMT基本原理,了解当前面临的主要问题以及的研究成果都非常有帮助。

图3、Manning教授、Luong和Cho在Tutorial上
3、《SemanticRepresentations of Word Senses and Concepts》
来自罗马大学的J Camacho-Collados,I Iacobacci,R Navigli,以及剑桥大学的MT Pilehvar共同带来了这次《词义和概念的语义表示》的Tutorial分享。
Word(词)是句子、文章、文档的重要组部分,但是Word Representation有比较大的局限性,例如:一词多义以及词义消歧等,因此本文详细介绍基于语义表示(Sense Representation)技术,而此领域作为一个基础领域可以在众多领域进行广泛的应用,例如:语义相似度、语义消歧、信息挖掘、语义聚类等等领域进行应用。并且系统的通过基于知识库(knowledge-based)和无监督(unsupervised)两个不同的技术体系与方案进行相关领域成果及方法系统的介绍。整个Topic虽无特别创新的地方,但是实用性较高,基于知识以及无监督的方法大部分在工业场景都可以借鉴,可以一读。
Slides下载地址:http://wwwusers.di.uniroma1.it/~collados/Slides_ACL16Tutorial_SemanticRepresentation.pdf
4、《UnderstandingShort Texts》
短文本理解的主题从字面意思理解就非常接地气。在日常的很多领域中都会产生大量的短文本,包括搜索、问答以及对话、推荐等领域,而短文本带来的问题也非常明显,包括稀疏问题、噪音问题以及歧义问题。因此这里就会产生大量的工作以及有意思的工作。
本次报告的分享人是来自前微软亚洲研究院(MSRA)的研究员王仲远(目前已经在Facebook)以及来自Facebook的王海勋(前Google以及前MSRA高级研究员)。可能是因为本次Topic分享人来自于企业界,加上相对接地气的分享主题,因此本次分享吸引了不少产业界以及学术领域的同学前来参加,包括Amazon、Yelp、讯飞、百度、微软等。
本文在短文本的理解技术上从文本语义明确(Explict)表示与隐性(Implict)表示将处理的方法技术分成了两种类型:ERM(Explict Representation Model)和IRM(ImplictRepresentation Model)。
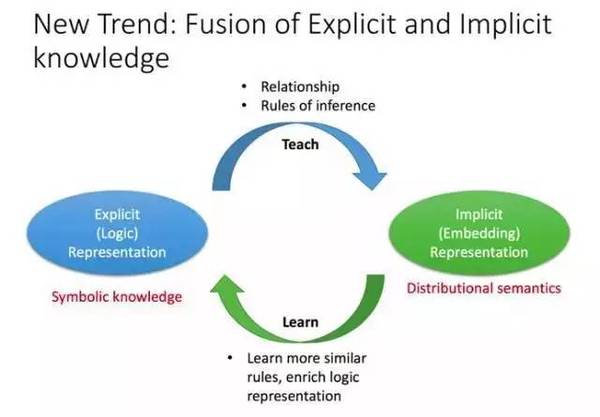
图4、EMR and IMR
ERM还是基于结构化知识库或者知识图谱,切分成为单实例和上下文多实例的两种类型分别进行短文本的理解;
单实例的处理方式:单实例的查询是否有歧义,无歧义既返回,有歧义进行基础基础的概念模型进行归一和分类,最终进行语义相似度的方法进行倾向性理解的方法;
多实例短文本的方式:语义分词处理与切分(文中提到了有监督和无监督N-Gram的方式,而在实际场景这个问题相对会更加成熟,可以参考中文分词技术),实体及结合上下文的实体识别、消歧和类型标注,到实例之间的关系标注,到最终的语义相似度计算;
IRM更多基于embedding和deep learning的方法做短文的理解与计算。本文还是有不少实际工业可以借鉴的地方,可以关注并读一下。
slides下载地址:
http://www.wangzhongyuan.com/tutorial/ACL2016/Understanding-Short-Texts/
三、会议详细内容
1、机器翻译方向
《Multimodal Pivots for Image CaptionTranslation》,这篇论文入选了本届会议的杰出论文,作者是德国海德堡大学的Julian Hitschlerand ShigehikoSchamoni和Stefan Riezler,所做的工作比较有新意。论文工作要解决的问题是改进图片标题的翻译质量,但并不是通过扩大双语句对、优化解码器等方法实现,而是先用图像检索的方法在目标语言图片库中检索与源语言图片相似的图片,然后用其所带的标题和机器翻译输出的译文组合之后进行重排序,从而显著提升了标题翻译的质量。对于改进机器翻译质量,这个工作并没有试图直接硬碰硬地去改进核心算法,而是另辟蹊径,反而取得了更好的结果。
《Modeling Coveragefor Neural Machine Translation》,这篇论文的作者是来自华为诺亚方舟实验室的涂兆鹏博士和李航博士,其核心思想是要解决之前基于注意力(attention)的NMT框架中由于缺少已翻译范围指引而导致的过翻(over-translation)或欠翻(under-translation)问题。论文引入了一个覆盖向量来跟踪NMT的attention历史,并在解码过程中反馈给attention模型,帮助后者不断调整未来的attention,从而从全局上记录哪些词已翻,哪些词未翻。这个工作解决了之前NMT框架中一个比较明显的缺口,对于NMT系统的实用化具有很好的价值。
《Phrase-LevelCombination of SMT and TM Using Constrained Word Lattice》,这篇论文的作者是来自于都柏林大学ADAPT中心的刘群教授、Andy Way和李良友。文中使用了一种受限词图结构,将输入的短语和由记忆库施加的约束条件编码到一个向量里,从而将SMT和TM在句子级实现了融合。这是众多NMT论文中为数不多的仍然以传统SMT和记忆库(TM)为主题的工作。考虑到TM在实用系统中仍是不可缺少的部分,这个工作也是具有一定的应用前景的。

图5、Phrase-Level Combination of SMT and TM UsingConstrained Word Lattice
2、机器阅读与理解
机器阅读理解是约在5、6年前逐渐为人关注的领域,它可以说是自然语言理解的终极形态。这个领域的研究形式是让机器先处理一篇文章(新闻文章或短篇故事),然后回答跟文章内容相关的填充题,要填充的一般都是某个实体的名字。(注:为了避免利用外部资源来作弊,常用做法是把实体名字替换成’@entity1’等特殊符号。)
本届ACL会议正好有一篇优秀论文(“A Thorough Examination ofthe CNN/Daily Mail Reading Comprehension Task”)是关于阅读理解的。该论文的重点在于借助一个基于CNN和每日邮报新闻数据的评测数据集去探讨当前阅读理解技术所能解决的范围。论文作者实现了两个相当标准的系统,一个基于传统分类器,另一个基于神经网络,然后对两个系统的表现作抽样调研。调研结果是:(i) 只需要字面匹配就能解答的问题是两个系统都能百分百回答正确的;(ii) 大部分阅读理解问题的关键在于同义表达的理解和若干程度的文本、常识推理,这方面基于神经网络的系统能达到90%上下的水平;(iii) 牵涉到代词指代和需要消化多个句子信息的问题,两个系统的表现都只达到50%左右;(iv)连一般人都难以回答的问题,机器也同样没辙,只能偶尔蒙中一两题而已。换言之,这篇论文一方面印证了神经网络确实是解决同义表达和简单文本推理的一个良好框架,但同时亦指出了要机器阅读理解的未来方向在于篇章级的理解方法。
另外一篇论文“Text Understanding with theAttention Sum Reader Network”在这个CNN/每日邮报数据集上使用了另外一套基于神经网络的方法,也得到几乎一样的准确率,印证了顶尖研究者都已经达到一样的水平了。
3、语言与视觉
这个又名“language grounding”的领域是NLP和computer vision的交叉领域,近年来也越来越受到关注。今年ACL有两篇论文对现实产品有相当意义。第一篇是“Learning Prototypical EventStructure from Photo Albums”。这篇论文指出不少照片簿其实都是关于一个大主题(例如婚礼),这个大主题往往由好几个小主题组成(例如交换戒指、新郎亲吻新娘、抛花球、切结婚蛋糕),而这些小主题往往也有一个时序。(见图6)论文作者于是提出一套方法,利用照片图像之间的相似度/差异度、照片标题的相似度/差异度、主题之间的顺序关系来对照片簿进行切分,并利用图像分类和文本分类对每个切分出来的部分给出一个主题标签。

图6、照片簿的自动切分和分类
第二篇值得注意的论文是来自微软研究院的“Generating Natural Questions about an Image”。论文指出目前的image captioning(自动赋予图片标题)研究通常都会对照片给一个很客观但也很干巴巴、‘没有人文关怀’的标题,例如对于图7中的照片,一般的系统都会给出“有个人在摩托车旁边”或类似的标题。这种标题抓不住整张图片的重点,因此也不能引起读者兴趣。这篇论文应该是关于Tay(英文版微软小冰)的一个功能,就是用户上传一张如图7的照片,然后聊天机器人回应一句像“发生什么意外了?”或“司机受伤了吗?”的回应。论文作者收集了并人工标注了一个相关的数据集,也提出生成式和检索式的两套方法。

图7、自然与不自然的相片标题
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4424.html
摘要:而自然语言处理被视为深度学习即将攻陷的下一个技术领域,在今年全球较高级的学术会议上,我们也看到大量的在深度学习引入方面的探索研究。 深度学习的出现让很多人工智能相关技术取得了大幅度的进展,比如语音识别已经逼近临界点,即将达到Game Changer水平;机器视觉也已经在安防、机器人、自动驾驶等多个领域得到应用。 而自然语言处理(NLP)被视为深度学习即将攻陷的下一个技术领域,在今年全球较高级...
摘要:深度学习浪潮这些年来,深度学习浪潮一直冲击着计算语言学,而看起来年是这波浪潮全力冲击自然语言处理会议的一年。深度学习的成功过去几年,深度学习无疑开辟了惊人的技术进展。 机器翻译、聊天机器人等自然语言处理应用正随着深度学习技术的进展而得到更广泛和更实际的应用,甚至会让人认为深度学习可能就是自然语言处理的终极解决方案,但斯坦福大学计算机科学和语言学教授 Christopher D. Mannin...
摘要:于月日至日在意大利比萨举行,主会于日开始。自然语言理解领域的较高级科学家受邀在发表主旨演讲。深度学习的方法在这两方面都能起到作用。下一个突破,将是信息检索。深度学习在崛起,在衰退的主席在卸任的告别信中这样写到我们的大会正在衰退。 SIGIR全称ACM SIGIR ,是国际计算机协会信息检索大会的缩写,这是一个展示信息检索领域中各种新技术和新成果的重要国际论坛。SIGIR 2016于 7月17...
摘要:年月日,麻省理工科技评论发布了年岁以下科技创新人中国榜单,美团点评平台部中心负责人点评搜索智能中心负责人王仲远获评为远见者。这一次,王仲远依然拿到了很多顶级机构发出的。年,因为家庭方面的考虑,王仲远选择回国发展。 2019 年 1 月 21 日,《麻省理工科技评论》发布了 2018 年35 岁以下科技创新 35 人(35 Innovators Under 35)中国榜单,美团点评AI平...

阅读 2265·2023-04-25 19:06
阅读 1513·2021-11-17 09:33
阅读 1873·2019-08-30 15:53
阅读 2675·2019-08-30 14:20
阅读 3624·2019-08-29 12:58
阅读 3634·2019-08-26 13:27
阅读 600·2019-08-26 12:23
阅读 572·2019-08-26 12:22





