
摘要:陈云霁陈天石课题组在国际上提出了较早的深度学习处理器架构寒武纪。而则是寒武纪的指令集。模拟实验表明,采用指令集的深度学习处理器相对于指令集的有两个数量级的性能提升。
背景:
中科院计算所提出国际上较早的深度学习指令集DianNaoYu
2016年3月,中国科学院计算技术研究所陈云霁、陈天石课题组提出的深度学习处理器指令集DianNaoYu被计算机体系结构领域较高级国际会议ISCA2016(International Symposium on Computer Architecture)所接收,其评分排名所有近300篇投稿的第一名。论文第一作者为刘少礼博士。
深度学习是一类借鉴生物的多层神经网络处理模式所发展起来的智能处理技术。这类技术已被微软、谷歌、脸书、阿里、讯飞、百度等公司广泛应用于计算机视觉、语音识别、自然语言处理、音频识别与生物信息学等领域并取得了极好的效果。基于深度学习的围棋程序AlphaGo甚至已经达到了职业棋手的水平。因此,深度学习被公认为目前最重要的智能处理技术。
但是深度学习的基本操作是神经元和突触的处理,而传统的处理器指令集(包括x86和ARM等)是为了进行通用计算发展起来的,其基本操作为算术操作(加减乘除)和逻辑操作(与或非),往往需要数百甚至上千条指令才能完成一个神经元的处理,深度学习的处理效率不高。因此谷歌甚至需要使用上万个x86 CPU核运行7天来训练一个识别猫脸的深度学习神经网络。
陈云霁、陈天石课题组在国际上提出了较早的深度学习处理器架构寒武纪。而DianNaoYu则是寒武纪的指令集。DianNaoYu指令直接面对大规模神经元和突触的处理,一条指令即可完成一组神经元的处理,并对神经元和突触数据在芯片上的传输提供了一系列专门的支持。模拟实验表明,采用DianNaoYu指令集的深度学习处理器相对于x86指令集的CPU有两个数量级的性能提升。
指令集是计算机软硬件生态体系的核心。Intel和ARM正是通过其指令集控制了PC和嵌入式生态体系。寒武纪在深度学习处理器指令集上的开创性进展,为我国占据智能产业生态的领导性地位提供了技术支撑。
两篇论文
杨军 从事大规模机器学习系统研发及应用相关工作
(更新历史:10.5号更新,加入了DianNao部分的内容;10.4号更新,加入了DaDianNao部分的内容;10.2号更新,加入了ShiDianNao部分的内容;)
最近正好在比较系统地关注AI硬件加速的东东。
前几天比较细致的读了一下ISCA16上关于寒武纪指令集的文章,在这里(寒武纪神经网络处理器效能如何 ? - 杨军的回答)有一个当时写的paper reading notes。
这两天花了一些时间,又把发在ASPLOS 15、ISCA 15、Micro 14以及ASPLOS 14上的PuDianNao/ShiDianNao/DaDianNao/DianNao这四篇文章也读了一下,整理了一份reading notes,分享出来供参考。在我看来,系统性地把DianNao项目的相关重点论文一起梳理一遍,对于透过陈氏兄弟的工作来把握AI硬件加速器这个技术trend会更有助益。
1. PuDianNao
[1]是陈氏兄弟发起的Diannao项目[2]中的最后一篇论文,文章对七种常见的机器学习算法的计算操作类型和访存模式进行了总结。包括:
kNN/k-Means/DNN/Linear Regression/Support Vector Machine/Naive Bayes/Classification Tree。
基于对这七种算法的分析,提出了一种能够同时支持七种算法的硬件加速器的设计方案。
发在ASPLOS这种国际顶会上的文章,写作风格通常也非常干净清晰,结构明了,这篇文章也秉持了这个传统,即使是非体系结构出身的人,读起来也会感觉很清爽。
文章先是对七种机器学习算法的计算及访存范式进行了分析,这也是后续的硬件加速器的基础,套用工业界的说法,这属于我们的“业务问题”,只有先对业务问题认识清楚了,才能给出好的解决方案。
以kNN算法[3]为例,这个算法的核心思想比较直观,并不需要显式的训练环节,而是直接根据已经获取到的有标签的reference sample,对于待预测样本,通过给定的distance function,找到距离待预测样本最近的k个reference sample,然后再根据这k个reference sample的标签决议出待预测样本的标签,核心的代码逻辑如下:

主要的计算开销花在了distance function的计算上(具体distance function根据业务、数据的特点来进行design,常用的比如cosine similarity[4]/Euclidean distance[5]/Hamming distance[6])。
如果我们把计算开销拆解得再细致一些,会发现,计算开销由纯计算时间+访存时间构成。纯计算时间的优化,可以通过定制硬件资源来获取到,而访存时间的优化则需要结合具体的访存模式来展开。
在计算机体系结构领域,常用的提升访存性能的方案是缓存机制的引入,这在Pattern 04年的talk[7]里,也将其列为解决计算机系统里bandwidth与latency的gap的1st solution。
我个人比较直观的印象是,在读master的时候,自己做过一段时间硬件模拟器的开发工作,当时的工作现在看起来并不复杂,参考VMIPS[8]实现了一个基于龙芯1号的SoC模拟器,当时的实际观测里,运行非常简单的benchmark(因为是裸芯片,所以为了简单,这个benchmark就是一个类似于简易BIOS的bootloader + 硬件测试逻辑的组合),能够观察到cache生效与否对性能带来几十倍以上的影响。
回到我们讨论的这篇文章,访存性能的提升,往往对于最终系统的性能会带来显著的影响。在文章里也基于一个cache仿真器,对七类机器学习算法的访存行为进行了仿真评估,并发现kNN算法的原始实现会引入大量的访存行为,这个访存行为的频繁度会随着reference sample集合的增加而增加(原因很简单,cache无法装下所有 的reference sample,所以,即便这些reference sample会不断地被重复访问,也无法充分挖掘data locality所带来的cache收益)。针对这种应用类型,实际上存在成熟的优化范式——Loop tiling[9]。
Loop tiling的基本思想是,对于循环逻辑,通过将大块的循环迭代拆解成若干个较小的循环迭代块,减少一个内存元素的re-use distance,换句话说,也就是确保当这个内存元素被加载到cache以后,尽可能保留在cache中,直到被再次访问,这样就达到了减少了昂贵的片外访存的开销的目的。对体系结构不太熟悉的同学,可能未必能一下子感知到这样做的意义,参考[10][11][12][16][17]里的一些number,能够更为量化地感知到数据访问落在不同的存储部件上(CPU寄存器/Cache/内存/磁盘外存/网络)的差异,也许就可以更为深刻地理解到loop tiling这个看起来不起眼的优化技巧对性能带来的潜在提升。

针对kNN算法,使用loop tiling优化后的代码逻辑会长成这样:

优化后相较于优化之前的实现,片外访存带宽减少了 90%:
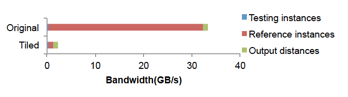
针对kNN算法的分析套路,也可以套用在剩下的6种算法上,每种算法的most time-consuming的主要计算逻辑类型不同(kNN/k-Means对应的是distance function的计算,DNN/Linear Regression对应的则是向量点积和矩阵乘法计算, Naive Bayes对应的是计数),为了充分挖掘data locality的优化技巧细节也有所差异,但基本上都是loop tiling的应用。
比如k-Means里,聚类中心点会被反复访问,其data locality就是需要着力优化的地方;DNN里,两层layer之间的线性变换操作中,weight和上层layer不具备data locality,不需要进行优化,而下层layer的神经元会被访问多次,就需要充分挖掘其data locality,这里就不再详述,可以直接参考原始论文。
在这7个算法中,基于loop tiling优化技巧,kNN/k-Means/Linear Regression/DNN/SVM具有较好的data locality挖掘空间,而Naive Bayes/Classification Tree的data locality挖掘空间则较小。这从下图可以表现得更为形象:
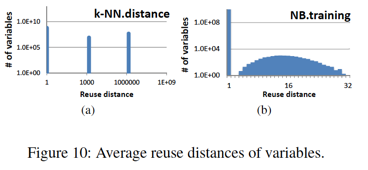
对跑在加速器上的这7类算法任务的认识,对于加速器的结构设计有着重要的影响。
比如,在kNN为代表的5算法都表现出相似的data locality,带来的一个直观启示就是对于reuse distance > 1的两大类变量,分别提供两种不同尺寸的cache,来配合loop tiling充分挖掘data locality。
另外,对于不同算法里耗时最多的计算任务的理解,对于具体的硬件执行流水线的设计也有着重要的启示。
下面我们可以来看一下PuDianNao的结构设计图:
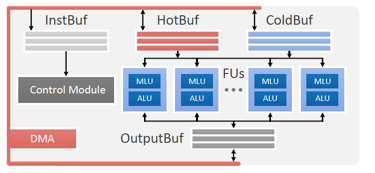
PuDiannao的结构主要由若干个Function Unit(每个FU的功能是相同的),三个数据缓存(Hot Buffer, Cold Buffer, Output Buffer),一个指令缓存(Inst Buffer),一个控制模块(Control Module),以及DMA控制器组成。
Function Unit是PuDiannao的基本执行单元,每个FU又由两个部件构成,分别是用于机器学习算法硬件定制支持的Machine Learning Unit,以及用于常规计算控制任务的Arithmetic Logic Unit。
作为提供机器学习硬件加速支持的MLU,其内部由Counter、Adder、Multiplier、Adder Tree、Acc、Misc 6级流水线组成。MLU的流水线微结构图如下:
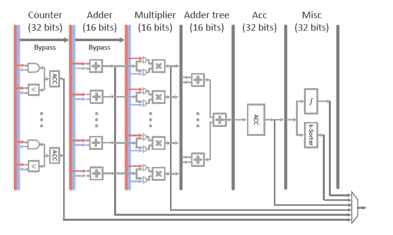
关于流水线的设计,值得一提的是Multiplier + Adder Tree提供了dot product的支持,这也是LR/SVM/DNN里的高频操作。当样本维度高于流水线运算部件的计算宽度时,可以通过Acc stage对Multiplier + Adder Tree输出的partial sum结果进行累积,来给以支持。Misc stage提供了对非线性函数(比如sigmoid/tanh函数)的线性插值近似和top-k/tail-k功能(在kNN和k-Means里会用到)的硬件支持。
为了减少芯片面积及功耗,在Adder/Multipler/Adder tree这三个stage里支持的是16位的浮点计算,而对于Counter/Acc/Misc这三个stage则仍然使用32位浮点数,这种设计也是考虑到Counter/Acc/Misc离最终计算结果比较近,overflow的风险较高,而Adder/Multiplier/Adder tree对应于中间计算结果,overflow风险较低,所以会做出这种设计trade-off。
在文章里,也对于这种16-bit的trade-off所可能带来的算法精度下降进行了量化评估:
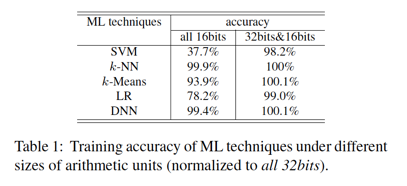
基准线是所有pipeline stage都采用32-bit浮点数的精度,能够看到,32bi&16bit的混合设计,对于模型精度影响并不大。
相较于MLU,ALU的设计则比较简单,主要实现了MLU里未支持,也即是在机器学习算法中非高频操作的逻辑。比如除法、条件赋值等。这样设计的考虑是希望PuDiannao能够尽可能自治地支持起机器学习算法运行所需的基础部件支持,因为PuDiannao本质上还是一个加速器,所以会作为协处理器[15]嵌入到宿主系统里,协同支持完整计算任务的执行。如果对于机器学习算法中非典型高频操作不提供支持,那么这些操作就需要回落到宿主cpu上,这会增加宿主系统与PuDiannao的协同开销,对加速效果也会带来影响。
关于存储部件的设计,在上面已经提了引入多种data buffer的设计动机(支持计算任务里不同的reuse distance),需要再补充一下的是,为了减少芯片面积和功耗,hot buffer/code buffer使用的是单端口的SRAM,而output buffer则因为其支持的操作类型(同时读写),使用了双端口的SRAM。
在[13]里,可以了解到,相较于单端口RAM,双端口RAM无论是在基本存储单元cell的面积上,还是控制逻辑上,都引入了额外的代价,这也是这里做这个设计trade-off的考量。另外,为了提升主存到PuDiannao的数据交换性能,对于inst buffer和data buffer都采取了DMA与宿主系统进行交互。
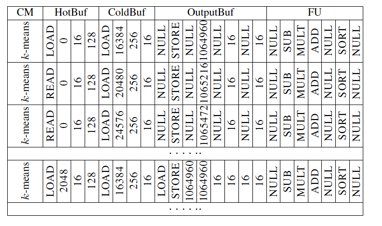
PuDiannao的Control Module扮演的是指令译码器和dispatcher的功能。PuDiannao里,计算任务的描述,通过control instruction来描述,而control module就是对control instruction进行译码,然后把需要执行的操作指令发送给所有 的FU上。PuDiannao的指令抽象度比较低,所以使用control instruction编程需要对PuDiannao的架构实现细节非常了解,看一下control instruction的格式会有助于建立这个认识:

以及基于control instruction所编写的k-Means的code snippet:
最后基于PuDianNao的评估集中在性能加速比以及功耗这两个方面。分别基于verilog和C仿真器完成了评估环境的搭建。verilog评估环境(65nm工艺)的精度更高,但速度慢,C仿真器的速度快,但评估精度会有一定的损失。
评估使用的数据集描述如下:
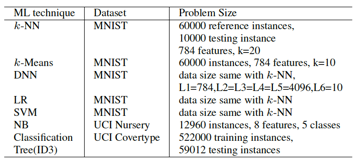
评估的baseline是GPU(NVIDIA K20M, 3.2TFlops peak,5GB显存,208GB/s显存带宽,28nm工艺, CUDA SDK5.5)。
性能评估的策略是将7个算法的不同phase拆分开来与baseline进行评估对比:
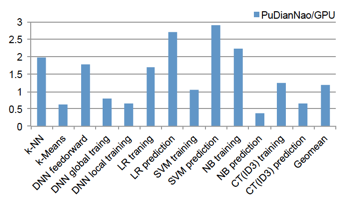
在上面的评估结果中,能够看到,有某些phase里,GPU baseline的表现要比PuDianNao要好,比如Naive Bayes的prediction phase,这跟Naive Bayes的prediction的计算类型涉及到大量的乘法计算有关,PuDianNao并没有配置大规模的寄存器堆,所以需要在on-chip的data buffer和FU之间频繁地进行数据交互,而K20M则有64K个寄存器可供给计算,所以不会存在这个问题,于是造成了这种performance差异(说到这里,我有些好奇的是在[14]里,对于这个问题是怎样解决的。因为在[14]里,我并没有看到在regisger上面的额外设计资源投入,仍是通过data buffer来完成计算任务所需的数据存储,看起来似乎应该存在跟PuDianNao相同的问题。但是在[14]里,工艺与PuDianNao相同,都是65nm,相较于相同的GPU baseline,averagely却获得了3X的性能提升,这是一个让我暂时未解的疑问)。性能提升最明显的SVM prediction则主要是FU里提供了kernel函数的插值逻辑硬件实现带来的。
如果说PuDianNao带来的性能提升相较于GPU并不显著的话(in average 1.2X),那么在计算能耗比上的提升,就相当显著了:
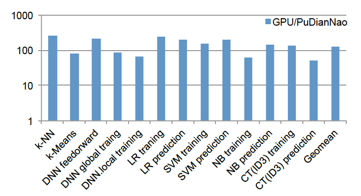
最后可以看一下PuDianNao的layout信息:

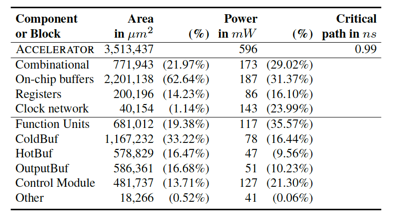
能够看到,FU(Functional Unit)和CB(Cold Buffer)是面积大户,CM(Control Module)的面积不大,但是功耗并不小。
正好前不久刚刚精读了Cambricon指令集的论文[14],把两篇论文联系在一起来看,还是隐约能够感知到一些脉络。PuDianNao里给出的流水线设计,更像是一个特殊的定制硬件逻辑,ad-hoc的味道更浓,而[14]里给出的流水线设计则比较接近于一个中规中矩的处理器的设计了。[14]里也能够看到更明显的抽象的味道,把Add/Multplication这些操作都集中在了Vector/Matrix Func Unit里,不像PuDianNao这样,会在不同的流水线stage里,分别提供了看起来有些相近的实现(Add逻辑在多个pipeline stage里出现)。在片上存储体系的设计里,[14]也更为general,通过更为精巧的crossbar scratchpad memory来统一提供片上访存支持。最重要的是,PuDianNao只提供了针对7种算法的操作码,而[14]则在指令集的层次为更丰富的应用类型提供了支持。
接下来计划再去读一下DianNao系列的其他几篇文章,以作相互映照。
在阅读PuDianNao的时候,还是发现对于[14]的理解,有些地方并不如之前所以为的那样深入,因为在PuDianNao里看到的一些问题(比如Naive Bayes prediction的问题),似乎并没有理解清楚在[14]里是如何针对性解决的,也许随着对整个系列论文的深入阅读 ,能够形成一个更为完整系统化的认识吧。
References:
[1]. Daofu Liu. PuDianNao: A Polyvalent Machine Learning Accelerator. ASPLOS, 2015.
[2]. A Brief Introduction to The Dianao Project. http://novel.ict.ac.cn/diannao/
[3]. k-nearest neighbors algorithm. k-nearest neighbors algorithm
[4]. cosine similarity. Cosine similarity
[5]. Euclidean distance. Euclidean distance
[6]. Hamming distance. Hamming distance
[7]. David Patterson. Why Latency Lags Bandwidth and What It Means to Computing. https://www.ll.mit.edu/HPEC/agendas/proc04/invited/patterson_keynote.pdf
[8]. VMIPS. The vmips Project
[9]. Loop tiling. Loop tiling
[10]. Approximate cost to access various caches and main memory. latency - Approximate cost to access various caches and main memory?
[11]. CPU Cache Flushing Fallacy. http://mechanical-sympathy.blogspot.com/2013/02/cpu-cache-flushing-fallacy.html
[12]. Answers from Peter Norvig. Teach Yourself Programming in Ten Years
[13]. What is dual-port RAM. Dual port memory, dual ported memory, Ports, sdram, sram, sdram, memories
[14]. Shaoli Liu. Cambricon: An Instruction Set Architecture for Neural Networks", in Proceedings of the 43rd ACM/IEEE International Symposium on Computer Architecture. ISCA, 2016.
[15]. Coprocessor. Coprocessor
[16]. Visualization of Latency Numbers Every Programmer Should Know. Numbers Every Programmer Should Know By Year
[17]. Latency Numbers Every Programmer Should Know. https://gist.github.com/jboner/2841832
2. ShiDianNao
这[1]是陈氏兄弟DianNao项目[2]的第三篇论文,发在了ISCA 2015上。
之前阅读了这个系列里的Cambricon[4]和PuDianNao[3]这两篇论文,感觉ShiDianNao这篇论文在立意的创新性上比起[3][4]略逊了一筹,更像是一个针对具体应用场景的一个偏工程层面的体系结构设计&优化工作,但是在加速器的设计细节上却是touch得更为详细的,无论是访存体系的设计,还是计算单元的设计,介绍得都非常的细致,看完这个设计,说对一个比较naive的GPGPU这样的硬件加速器建立起一定的sense并不为过。
文章的核心思想是利用CNN网络weight sharing的特性,将CNN模型整体加载入SRAM构成的高速存储里,减少了访问DRAM带来的内存开销。同时,将加速器直接与视频图像传感器相连接,传感器采集到的图像数据直接作为加速器的输入进行处理,减少了额外的访存操作(传统模式下,会先将传感器采集到的数据放入DRAM,再知会加速器进行处理,于是会有至少两次的额外DRAM访问操作)。
Overall的思想听起来很直观,但真正操作起来,有着大量的设计细节需要去考量,列举几个文章中提到的挑战以及我在文章阅读过程中想到的挑战:
1.与传感器直连的加速器芯片中的SRAM尺寸取多大比较合适?太大了,功耗、面积就上去了。太小了,对性能会带来明显的影响(想象一下如果模型不能全部hold到加速器的SRAM里,对计算过程带来的影响)。所以这很考究架构师对目标问题以及技术实现方案细节的把控和理解。
2.对于会跑在这款加速器上的CNN模型,采取什么样的方式来映射到硬件计算资源?比较natural且高效的方式是,每个神经元都要对应于一个硬件计算单位,但这样很容易因为模型尺寸超出硬件物理计算单元个数而限制加速器所能支持的应用类型。而如果不强求一个神经元对应一个硬件计算单位,采用时分复用的方法,也还有小的设计权衡要考虑,以卷积层为例,在计算一个特定的feature map的output neuron的时候,在同一个时刻是只为一个output neuron进行计算,还是同时为多个output neuron进行计算,这在硬件复杂性/面积/灵活性上都会有不同的影响。
3.跑在加速器芯片上的应用任务,存在一定的data locality,对这种data locality是否需要进行挖掘,以榨取更多的性能加速的空间?比如,在计算卷积层feature map的时候,卷积输入层的input neuron实际上是会被多个output neuron使用到的,这些input neuron是每次为某个output neuron计算的时候,都去从SRAM中访问获取,还是在计算单元中,引入一些local storage,进行计算单元之间的内部通信。虽然说SRAM已经比DRAM的性能要好了一个数量级[7],但是计算单元之间的直连通信能够带来更多的性能收益。当然,这样做的代价是硬件设计的复杂性。
硬件开发工作不像软件开发,一次性成本非常高,所以在设计环节往往需要食不厌精,反复雕琢。也只有这样做,当芯片大规模量产以后,ROI优势才能突显出来。
ShiDianNao的工作,最出彩的,就是针对上面提到的具体问题场景,给出了比较精巧的硬件设计方案。
首先来看一下ShiDianNao的顶层结构:
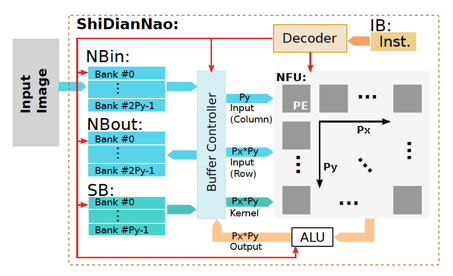
在这个设计方案里,左侧是SRAM堆起来的数据存储(共计288KB,见下图片上SRAM的具体功用分配),
根据CNN计算任务的特点(一组input neurons通过一层数学计算,生成一组output neurons),设计了三类SRAM存储:
NBin:存取input neurons。
NBout:存放输出output neurons。
SB:存放完整的模型参数。
在这三类存储中,SB要求能够hold住模型的全部参数,而NBin/NBout要求能够hold住神经网络一个layer的完整input/output neurons。原因是因为,模型参数会被反复使用,所以需要放在SRAM里以减少从DRAM里加载模型参数的时间开销,而作为CNN模型输入数据的一张特定的图片/视频帧的raw data被模型处理完毕后不会被反复使用,所以只需要确保每个神经层计算过程中所需的input/output neurons都hold在SRAM里,就足以满足性能要求。
右侧则是一个NFU(Neural Functional Unit),这是一个由若干个PE组成的计算阵列。每个PE内部由一个乘法器、一个加法器、若干个寄存器、两组用于在PE阵列水平/垂直方向进行数据交互的FIFO以及一些辅助的控制逻辑组成:
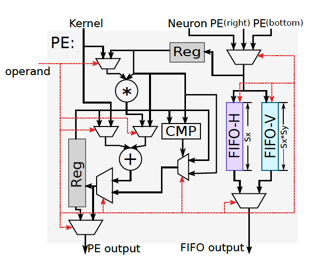
NFU的计算结果会输出到一个ALU,通过ALU最终写入到NBOut里。ALU里实现了一些并行度要求不那么高的运算支持,比如average pooling会用到的除法操作,以及非线性激活函数的硬件实现等。其中非线性激活函数的实现,使用了分段函数进行插值近似[8],以求在精度损失较小的情况下,获取功耗和性能的收益。
在ShiDianNao里,所有的数值计算均使用的是16位定点计算[6],而没有使用32位的浮点计算。这种策略在其他硬件加速器的设计[5]里也有过成功的应用。
NFU的PE阵列设计里,值得一提的是对Inter-PE data propagation的支持。引入这层支持的考虑是减少NFU与SRAM的数据通讯量。我们回顾一下卷积层Feature Map的计算细节,会注意到同一个feature map里不同的output neuron,在stride没有超过kernel size的前提下,其输入数据存在一定的overlap,这实际上就是Inter-PE data propagation的引入动机,通过将不同的output neuron之间overlap的那部分input neuron直接在PE之间进行传播,从而减少访问SRAM的频次,可以在性能和功耗上都获得一定的收益。这个收益,会随着卷积核尺寸的增加而变得更加明显。
以32x32 input feature map + 5x5 卷积核为例,通过下图,可以看到,随着PE个数的增加,对SRAM带宽需求的增加,以及Inter-PE data propagation优化的效果:

ShiDianNao另一个重要的部件是Buffer Controller,这是用于在片上存储NBin/NBout/SB与计算部件NFU之间协调数据交互的co-ordinator。Buffer Controller负责完成两个功能:以流式的方式,layer-wise的为NFU提供计算所需数据的供给,以及缓冲NFU计算的partial输出结果,汇总完一个完整layer/feature map上所有的output neuron之后才写回到NBout。这里比较关键的细节是,为了能够高效地支持CNN模型中的不同操作对应的访存特点,在Buffer Controller里提供了对多种read mode的支持:
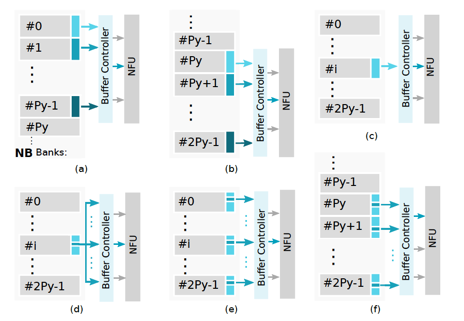
稍微选几个典型的读取模式进行介绍。在上面这个图里,(a)/(b)/(e)模式主要用于为卷积层提供数据读取,读取的每个input neuron会对应于一个output neuron(注意:在ShiDianNao里,这些已经通过Buffer Controller读取到PE中作为输入的input neuron接下来会通过Inter-PE data propagation的机制进行传递,从而节省了SRAM的访问带宽),其中(e)对应于卷积核step size > 1的情形。(d)对应于全连接层,读取一个input neuron,会用作多个output neuron的输入。
至此,ShiDianNao的设计思想的核心基本介绍完了,一些更为detail的细节,在论文里描述得很细致,比如,NFU里支持CNN/Pooling/Normalization/DNN layer的细节、为了节省指令cache对控制指令进行了一层抽象。我认为已经不再影响把握论文的核心设计思想,所以这里就不再详述了。
最后还是评估环节,评估环境的搭建使用的是Synopsys提供的EDA工具,65nm(跟[1][3]相同)。Baseline则选取了CPU(Intel Xeon E7-8830/2.13GHZ/1TB Memory/gcc 4.4.7/MMX/SSE/SSE2/SSE4/SSE4.2)、GPU(NVIDIA K20M/5GB显存/3.52TFlops/28nm/Caffe)以及DianNiao项目的第一个工作成果[9]。
评估的Benchmark使用了下表中所列出的10类较小规模的CNN模型(受限于片上SRAM的尺寸,在ShiDianNao里不能支持太大的CNN model,比如AlexNet。在这10个Benchmark model里,layer wise的神经元最多消耗45KB SRAM存储,而模型的权重最多只消耗118KB SRAM,足以被ShiDianNao目前配备的288KB SRAM所支持):
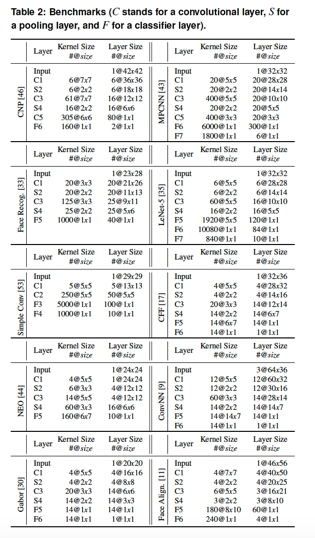
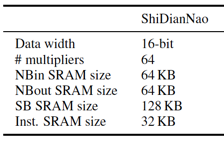
评估所用的ShiDianNao,其NFU由8*8共计64个PE组成,也即在一个cycle里。同时支持64组乘/加组合运算,存储上,由64KB NBin、64KB NBout、128KB SB和32KB的指令buffer组成。
评估指标还是集中在计算性能以及功耗两个方面:
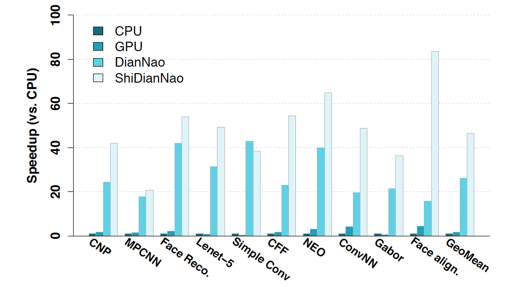
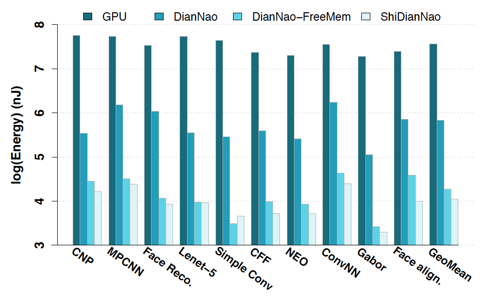
能够看到,ShiDianNao在性能上相较于CPU/GPU的baseline都有显著的speed up(46.38X than CPU,28.94X than GPU),相较于[9]里提出的加速器,也有1.87X的加速,这主要是因为ShiDianNao将模型全部hold在片上的SRAM里以及为了进一步减少SRAM访存开销设计的Inter-PE data propagation机制。
在功耗上,ShiDianNao的优势则更为明显,具体数字可以直接阅读原始论文,值得一提的是ShiDianNao的功耗在不同硬件部件上的分配:
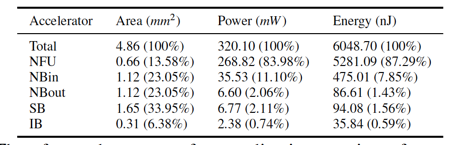
我们能够看到,在ShiDianNao里,主要的功耗都集中在计算部件(NFU)上了,访存部件带来的功耗开销并不大(小于15%),这与[9里的DianNao加速器]形成了巨大的差异:
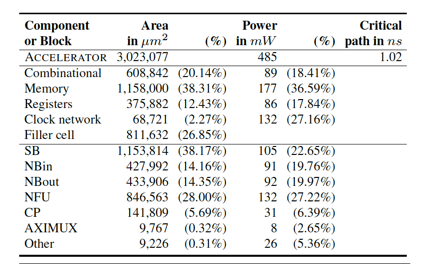
不过,这个关于功耗的评估对比结果里有些tricky的地方是,在ShiDianNao里,一部分数据传输操作实际上从SRAM访问操作里转移到PE之间的Inter-PE data propagation之上了,这部分功耗被计算入了NFU里,但实际上还是属于数据访问相关的功耗开销。这是我们在观察这些实验结果时要注意的地方。
最后说说我对这篇论文的一些思考。
这篇论文propose的加速器,适用面其实还是比较窄的,尺寸超过片上SRAM存储极限的模型都无法支持。比如包含几千万权重参数的AlexNet这样的model,肯定无法在ShiDianNao里被支持。当然这两年来,有不少研究团队提出了一些模型压缩的技术,比如DeepScale提出的SqueezeNet[10]和ICLR16上提出的Deep Compression[11],能够缓解ShiDianNao这样的加速器的片上模型存储的压力,但ShiDianNao要求模型能够全部hold在片上SRAM的约束,对于其通用性还是带来了一些挑战(相比而言,要求神经层的输入/输出神经元全部能够hold在NBin/NBout倒并不是一个苛刻的约束),这个约束在[3][4]里并没有看到。也许未来的一种可能是将ShiDianNao这样专门针对特定场景的加速芯片与[3][4]这种更具通用性的加速器设计融合在一起,可以获取到更好的性能/通用性的trade-off,当然其代价是芯片设计的复杂性。
最后想说的,真的是no free lunch。记得以前Knuth说过,系统的复杂性是恒定的,无非是在硬件和软件之间的分配。当硬件遇到了阶段性极限的时候,软件设计人员就要去填充更多的复杂性。当软件也遇到极限的时候,就需要硬件与软件进行协同设计来改善系统复杂性。在DianNao系列工作中,能够明显看到这个trend。在[12]里也通过对体系结构顶会的技术主题的变迁进行了回顾分析,能够看到软硬件协同设计、应用驱动设计的趋势。我个人相信,随着计算资源越来越可以便利地获取,网络带宽的使用成本日益降低,通过计算设备满足人类形形色色需求的应用驱动年代会更快/已经到来,在这个时代,应用/软件/硬件相结合来提供更具ROI的解决方案会是相当长一段时间内的趋势性现象。
References:
[1]. Zidong Du. ShiDianNao: Shifting Vision Processing Closer to the Sensor. ISCA, 2015.
[2]. A Brief Introduction to The Dianao Project. http://novel.ict.ac.cn/diannao/
[3]. Daofu Liu. PuDianNao: A Polyvalent Machine Learning Accelerator. ASPLOS, 2015.
[4]. Shaoli Liu. Cambricon: An Instruction Set Architecture for Neural Networks", in Proceedings of the 43rd ACM/IEEE International Symposium on Computer Architecture. ISCA, 2016.
[5]. Olivier Temam. A Defect-Tolerant Accelerator for Emerging High-Performance Applications. ISCA, 2012.
[6]. Fixed-point arithmetic. Fixed-point arithmetic
[7]. Latency Numbers Every Programmer Should Know. https://gist.github.com/jboner/2841832
[8]. D. Larkin, A. Kinane, V. Muresan, and N. E. O’Connor. An Efficient Hardware Architecture for a Neural Network Activation Function Generator. Advances in Neural Networks, ser. Lecture Notes in Computer Science, vol. 3973. Springer, 2006, pp. 1319–1327.
[9] T. Chen, Z. Du, N. Sun, J. Wang, and C. Wu. DianNao: a small-footprint high-throughput accelerator for ubiquitous machine learning. Proceedings of the 19th International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), Salt Lake City, UT, USA, 2014, pp. 269–284.
[10]. Song Han. Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding. ICLR16.
[11]. Forrest N. Iandola. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size. Arxiv, 2016.
[12]. 杨军. ISCA 2016有哪些看点. ISCA 2016 有哪些看点? - 杨军的回答
作者:杨军链接:https://www.zhihu.com/question/41216802/answer/124409366
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
3. DaDianNao
DaDianNao[1]这篇文章是Diana项目[5]的第二篇代表性论文,发表在Micro 2014[6],并且获得了当届的best paper。这篇论文里针对主流神经网络模型尺寸较大的应用场景(想像一下AlexNet这样的模型已经包含约6千万个权重参数),提出了一种具备伸缩性,并通过这种伸缩性可以承载较大尺寸模型的加速器设计架构。”Da”也取得是中文“大”的谐音,用来意指伸缩性。这款加速器与针对嵌入式设备应用场景提出的ShiDianNao[13]不同,针对的应用场景是服务器端的高性能计算,所以在计算能耗比上虽然相比于baseline(GPU/CPU)会有提升,但其设计核心还是专注于高性能地支持大尺寸模型,所以在硬件资源的使用上也远比[13]要更为大方一些。
在我的理解中,这款加速器的核心设计思想包括几个:
I. 使用eDRAM[3]代替SRAM/DRAM,在存储密度/访存延迟/功耗之间获得了大模型所需的更适宜的trade-off(参见下表)。

II. 在体系结构设计中以模型参数为中心。模型参数(对应于神经网络中的突触连接)存放在固定的eDRAM存储区域中,需要通过访存操作完成加载的是网络神经元(即对应于神经层layer的input/outout neurons)。这样设计考虑的原因是,无论是神经网络的training还是inference环节,对于于DaDianNao的问题场景,模型的尺寸要远远大于数据尺寸以及网络神经层的神经元数据尺寸,所以将尺寸更大的神经网络模型参数固定,而将尺寸较小的神经元通过访存操作进行加载、通信,可以减少消耗在访存上的开销。此外,模型参数会布署在距离计算部件很近的布局区域里,以减少计算部件工作过程中的访存延时(这也是Computational RAM思想[10]的典型应用)。另一个原因在文章里没有提到,而是我个人结合DianNao系列论文的解读,模型参数在整体计算过程中会不断地被复用,而神经元被复用的频率则并不高,所以将模型参数存放在固定的存储区域里,可以充分挖掘模型参数的data locality,减少片外访存带宽,同时提升整体加速器的性能。
III. 神经网络模型具备良好的模型可分特性。以常用的CNN/DNN这两类神经层为例。 当单层CNN/DNN layer对应的模型参数较大,超过了DaDianNao单片存储极限时(参见下图的一下大尺寸的CNN/DNN layer,具体到这些layer所对应的应用场景,可以参见DaDianNao的原始论文中的参考文献),可以利用这种模型可分性,将这个layer划分到多个芯片上,从而通过多片连接来支持大尺寸模型。想更具体的把握这个问题,不妨这样思考,对于CNN layer来说,每个feature map的计算(以及计算这个feature map所需的模型参数)实际上都是可以分配在不同的芯片上的,而DNN layer来说,每个output neuron的计算(以及计算这个output neuron所需的模型参数)也都是可以分配在不同的芯片上的。
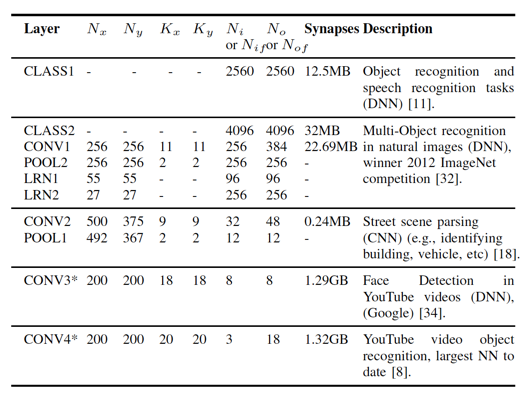
正是基于上面的三个设计原则,在这篇论文中给出了DaDianNao的设计方案。在我的理解中,DaDianNao的逻辑结构与DianNao[11](见下图)是非常相似的:
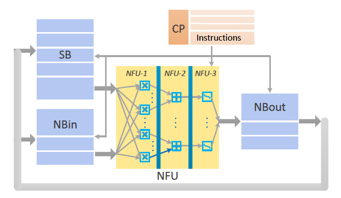
DaDianNao的主要区别还是在于针对存储神经层输入输出数据的NBin/NBout,存储神经连接参数的SB的组织方式,以及其与核心计算单元NFU的数据交互方式进行了针对大模型的专门考量。
把握DaDianNao的核心要素,也在于理解其访存体系的设计思想及细节。
单个DaDianNao芯片内的访存体系设计的高层次图如下:
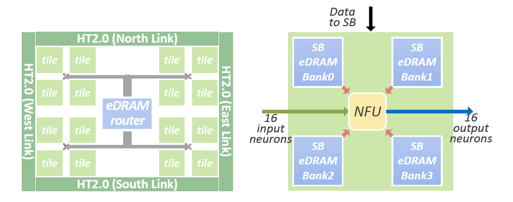
左图是单个芯片的高层次图,可以看到,单个芯片由16个Tile组成。右图则是单个Tile的顶层结构图。
每个tile内部会由一个NFU配上4个用于存储SB的eDRAM rank组成。而NBin/NBout则对应于左图eDRAM router所连接的两条棕色的eDRAM rank。
看到上面的高层次图,会感受到在DaDianNao里,SB其实是采用了distributed的方式完成设计的,并不存在一个centralized的storage用于存储模型的参数。这个设计细节的选取考量我是这样理解的:
I.eDRAM与DRAM相比,虽然因为其集成在了芯片内部,latency显著变小,但是因为仍然有DRAM所存在的漏电效应,所以还是需要周期性的刷新,并且这个刷新周期与DRAM相比会变得更高[4],而周期性的刷新会对访存性能带来一定的负面影响。所以通过将SB存储拆分成多个Bank,可以将周期性刷新的影响在一定程度上减小。
II.将SB拆分开,放置在每个NFU的周围,可以让每个计算部分在计算过程中,访问其所需的模型参数时,访存延迟更小,从而获得计算性能上的收益。
NFU的内部结构图如下所示:
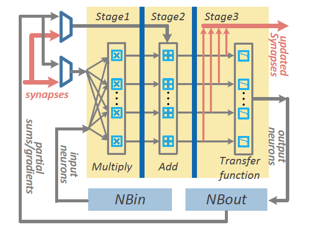
从上图,能够看到NFU的每个Pipeline Stage与NBin/NBout/SB的交互连接通路。 而针对不同的神经层,NFU的流水线工作模式可以见下图:
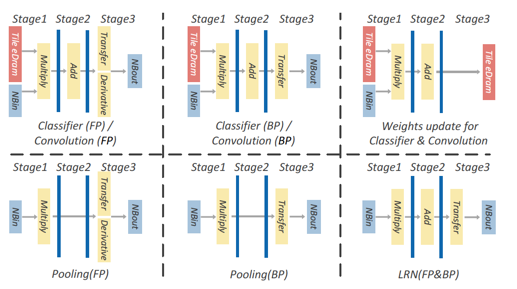
注意,上图里红色的“The eDram”代表的就是SB存储。
以上是单个DaDianNao芯片的设计,而单个DaDianNao的片上用于存储模型参数的SB存储仍然有限(见下图,单个芯片里,用于NBin/NBout的central eDRAM尺寸是4MB,而每个Tile里用于SB的eDRAM尺寸则是2MB,每个芯片由16个Tile组成,所以单个芯片的eDRAM总量是2 * 16 + 4 = 36MB),所以为了支持大模型,就需要由多个DaDianNao芯片构成的多片系统。

DaDianNao里的多片互联部分并没有进行定制开发,而是直接使用了HyperTransport 2.0[12]通信IP,在每个DaDianNao芯片的四周(每个芯片会跟上下左右四个邻近的DaDianNao芯片连接)提供了共四组HT 2.0的通信通道,每个通道的通信带宽是在in/out方向分别达到6.6GB/s,支持全双工通信,inter-chip的通讯延迟是80ns。
有了inter-chip的连接支持,DaDianNao就可以支持大尺寸的模型了。不同模型,在inter-chip的工作模式下,通信的数据量也有较大的差异:
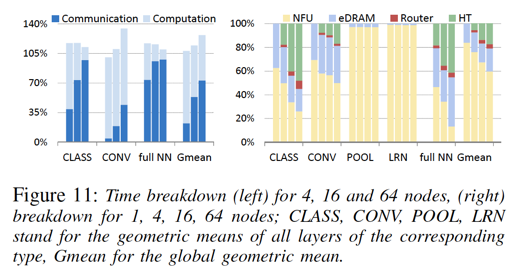
能够看到,相较于卷积层(CONV),全连接层(full NN)在多片模式下,通信耗时明显更多。 同样,卷积层的多片加速比也远大于全连接层(对于一些全连接层,甚至在Inference环节,出现多片性能低于单片的情形,这也算make sense,毕竟,inference环节的计算通信比要小于training环节):
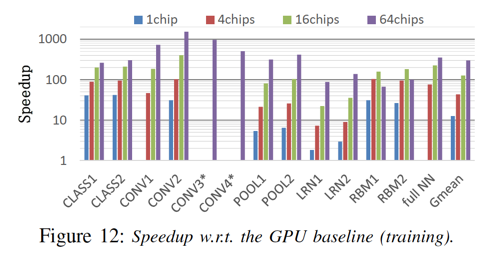
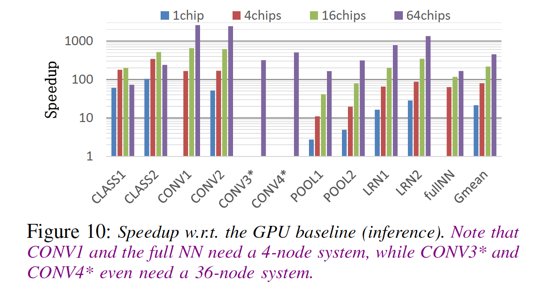
具体的细节评估指标,在这里就不再引入,感兴趣的同学可以直接参考原始论文。
References:
[1]. Yunji Chen. DaDianNao: A Machine-Learning Supercomputer. Micro, 2014.
[2]. S.-N. Hong and G. Caire. Compute-and-forward strategies for cooperative distributed antenna systems. In IEEE Transactions on Information Theory, 2013.
[3] eDRAM. eDRAM
[4]. Mittal. A Survey Of Architectural Approaches for Managing Embedded DRAM and Non-volatile On-chip Caches. IEEE TPDS, 2014.
[5]. A Brief Introduction to The Dianao Project. http://novel.ict.ac.cn/diannao/
[6]. Micro 2014. MICRO-47 Home Page
[7]. N. Maeda, S. Komatsu, M. Morimoto, and Y. Shimazaki. A 0.41a standby leakage 32kb embedded sram with lowvoltage resume-standby utilizing all digital current comparator in 28nm hkmg cmos. In International Symposium on VLSI Circuits (VLSIC), 2012.
[8]. G. Wang, D. Anand, N. Butt, A. Cestero, M. Chudzik, J. Ervin, S. Fang, G. Freeman, H. Ho, B. Khan, B. Kim, W. Kong, R. Krishnan, S. Krishnan, O. Kwon, J. Liu, K. McStay, E. Nelson, K. Nummy, P. Parries, J. Sim, R. Takalkar, A. Tessier, R. Todi, R. Malik, S. Stiffler, and S. Iyer. Scaling deep trench based edram on soi to 32nm and beyond. In IEEE International Electron Devices Meeting (IEDM), 2009.
[9]. DDR3 SDRAM Part Catalog. Micron Technology, Inc.
[10]. Computational RAM. Computational RAM
[11] T. Chen, Z. Du, N. Sun, J. Wang, and C. Wu. DianNao: a small-footprint high-throughput accelerator for ubiquitous machine learning. Proceedings of the 19th International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), Salt Lake City, UT, USA, 2014, pp. 269–284.
[12]. HyperTransport. HyperTransport
[13]. Zidong Du. ShiDianNao: Shifting Vision Processing Closer to the Sensor. ISCA, 2015.
4.DianNao
[1]是DianNao项目[2]的第一篇,也是篇开创性论文,发在了ASPLOS 14上,并且获得了当年的best paper。
如果用一句话来提炼这篇论文的核心思想,我想可以这样总结:
结合神经网络模型的数据局部性特点以及计算特性,进行存储体系以及专用硬件设计,从而获取更好的性能加速比以及计算功耗比。
因为我阅读DianNao项目系列论文是按时间序反序延展的,先后读的是PuDianNao[5]->ShiDianNao[4]->DaDianNao[3],最后读的是DianNao这篇论文。所以从设计复杂性来说,ASPLOS 14的这篇论文应该说是最简单的。当然,这样说并不是说这篇论文的价值含量比其他论文低。恰恰相反,我个人以为这篇论文的价值其实是较高的,因为这是一篇具备开创性意义的论文,在科研领域,我认为starter要比follower更有意义的多,这种意义并不会因为follower在执行操作层面的出色表现就可以减色starter的突破性贡献。 因为starter是让大家看到了一种之前没有人看到的可能性,而follower则是在看到了这种可能性之后,在执行操作层面的精雕细琢。几个经典的例子就是第一个超导材料的发现带动了后续多种超导材料的发现,以及刘易斯百米短跑突破10秒之后带动了多位运动员跑入10秒之内的成绩。
在[1]这篇论文里,先是回顾了之前常见的神经网络的全硬件实现方案(full-hardware implementation)——将每个神经元都映射到具体的硬件计算单元上,模型权重参数则作为latch或是RAM块实现,具体的示意结构图如下:
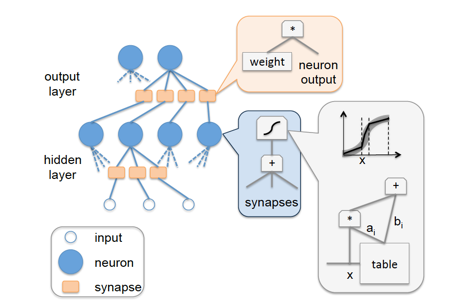
这种方案的优点很明显,实现方案简洁,计算性能高,功耗低。缺点也不难想象,扩展性太差,无论是模型topology的变化,还是模型尺寸的增加都会使得这种方案无法应对。下面针对不同 input neurons/网络权重数 的network layer给出了full-hardware implementation在硬件关键路径延时/芯片面积/功耗上的变化趋势,能够直观地反映出full-hardware这种实现方案的伸缩性问题:
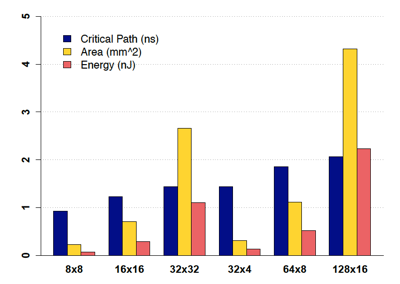
针对full-hardware方案的不足,在[1]里提出了基于时分复用原则的加速器设计结构:
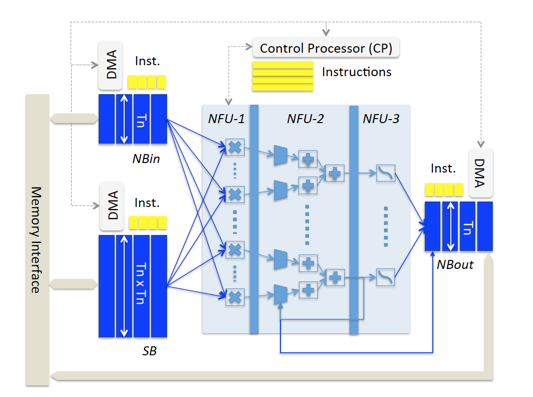
在这个设计结构里,加速器芯片里包含三块片上存储,分别是用于存储input neurons的NBin、存储output neurons的NBout以及用于存储神经网络模型权重参数的SB。这三块存储均基于SRAM实现,以获取低延时和低功耗的收益。片上存储与片外存储的数据交互方式通过DMA来完成,以尽可能节省通讯延时。
除了片上存储以外,另一个核心部件则是由三级流水线组成的NFU(Neural Functional Unit),完成神经网络的核心计算逻辑。
时分复用的思想,正是体现在NFU和片上存储的时分复用特性。针对一个大网络,其模型参数会依次被加载到SB里,每层神经layer的输入数据也会被依次加载到NBin,layer计算结果写入到NBout。NFU里提供的是基础计算building block(乘法、加法操作以及非线性函数变换),不会与具体的神经元或权重参数绑定,通过这种设计,DianNao芯片在支持模型灵活性和模型尺寸上相较于full-hardware implementation有了明显的改进。
DianNao加速器的设计中一些比较重要的细节包括:
I. 使用16位定点操作代替32位浮点,这在模型的精度方面,损失并不大:
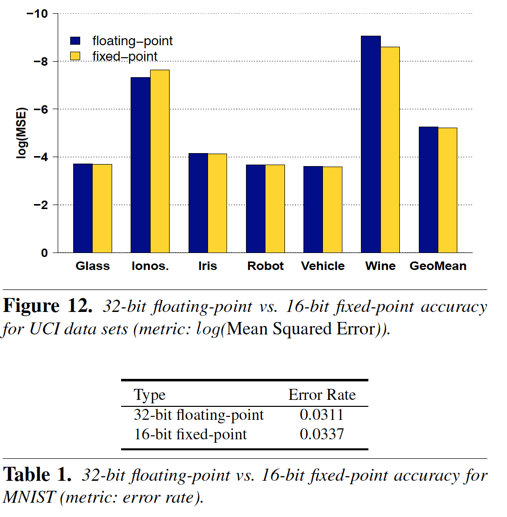
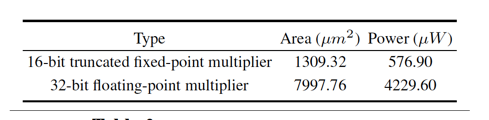
但是在芯片面积和功耗上都获得了明显的收益:
II. 之所以将片上SRAM存储划分为NBin/NBout/SB这三个分离的模块,是考虑到SRAM的不同访存宽度(NBin/NBout与SB的访存宽度存在明显差异,形象来说,NBin/NBout的访存宽度是向量,而SB则会是矩阵)在功耗上存在比较明显的差异:
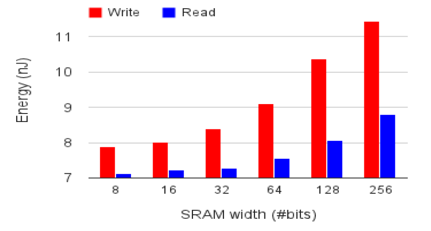
拆分成不同的模块,可以在功耗/性能上找到更佳的设计平衡点。而将访存宽度相同的NBin/NBout也拆分开来的原因则是为了减少data conflict,因为NBin/NBout扮演的还是类似于cache的角色,而这两类数据的访存pattern并不尽相同,如果统一放在一块SRAM里,cache conflict的概率会增大,所以通过将访存pattern相近的数据对应于不同的SRAM块,“专款专用”,可以进一步减少cache conflict,而cache conflict的减少,无论是对于性能的提升,还是功耗的减少都会有着正面的意义。
III. 对input neurons数据以及SB数据局部性的挖掘。用通俗一些的说法,其实就是把输入数据的加载与计算过程给overlap起来。在针对当前一组input neurons进行计算的同时,可以通过DMA启动下一组input neurons/SB参数的加载。当然,这要求精细的co-ordination逻辑保证。另外,这也会要求NBin/SB的SRAM存储需要支持双端口访问,这对功耗和面积会带来一定的影响[6]。
IV. 对output neurons数据局部性的挖掘。在设计上,为NFU引入了专用寄存器,用于存储output neurons对应的partial计算结果(想象一下对应于全连接层的一个output neuron,input neurons太多,NBin放不下,需要进行多次加载计算才能完成一个output neuron的完整结果的输出)。并且会在设计上将NBout用作专用寄存器的扩展,存放partial计算结果,以减少将partial计算结果写入片外存储的性能开销。
整体上的设计思想大体上如上所述。
在实验评估上,可能是因为作为第一个milestone的工作结果,还有很多细节有待雕琢,所以在baseline的选取上与后续的几篇论文相比,显得有些保守,在这篇论文里只选取了CPU作为baseline,并未将GPU作为baseline。具体的评估细节及指标可以直接参看原始论文,我这里不再重复。
References:
[1]. Tianshi Chen. DianNao: A Small-Footprint High-Throughput Accelerator for Ubiquitous Machine-Learning. ASPLOS, 2014.
[2]. A Brief Introduction to The Dianao Project. http://novel.ict.ac.cn/diannao/
[3]. Yunji Chen. DaDianNao: A Machine-Learning Supercomputer. Micro, 2014.
[4]. Zidong Du. ShiDianNao: Shifting Vision Processing Closer to the Sensor. ISCA, 2015.
[5]. Daofu Liu. PuDianNao: A Polyvalent Machine Learning Accelerator. ASPLOS, 2015.
[6]. What is dual-port RAM. Dual port memory, dual ported memory, Ports, sdram, sram, sdram, memories
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4434.html
摘要:年,中科院计算所半导体所有关研制大规模集成电路的单位和厂合并,成立中科院微电子中心。目前是国资比例最高通过中国长城控股的国产企业,是聚焦国家战略需求和重大项目的国家队。年,海光信息同达成合作,共同合资成立两家子公司,引入架构授权。本文将重点围绕国产CPU的发展历程与当前产业链各领军企业的布局情况作详尽解读(并包含特大号独家整理的最新进展),具体如下:1、国产CPU发展历程回溯2、飞腾:PK生...
摘要:受到其他同行在上讨论更好经验的激励,我决定买一个专用的深度学习盒子放在家里。下面是我的选择从选择配件到基准测试。即便是深度学习的较佳选择,同样也很重要。安装大多数深度学习框架是首先基于系统开发,然后逐渐扩展到支持其他操作系统。 在用了十年的 MacBook Airs 和云服务以后,我现在要搭建一个(笔记本)桌面了几年时间里我都在用越来越薄的 MacBooks 来搭载一个瘦客户端(thin c...
摘要:月日,各项竞赛的排名将决定最终的成绩排名。选手通过训练模型,对虚拟股票走势进行预测。冠军将获得万元人民币的奖励。 showImg(https://segmentfault.com/img/bVUzA7?w=477&h=317); 2017年9月4日,AI challenger全球AI挑战赛正式开赛,来自世界各地的AI高手,将展开为期三个多月的比拼,获胜团队将分享总额超过200万人民币的...

阅读 2796·2023-04-25 22:09
阅读 2917·2021-10-14 09:47
阅读 2142·2021-10-11 11:10
阅读 2784·2021-10-09 09:44
阅读 3507·2021-09-22 14:57
阅读 2597·2019-08-30 15:56
阅读 1687·2019-08-30 15:55
阅读 854·2019-08-30 14:13




