
摘要:迭代次,重复执行三次重复计算了三次,使用相同的图片,相同的卷积神经网络模型,相同的迭代次数次,却得到了区别明显的三张结果图。推测原因由于卷积神经网络中的若干层,实际是对图像进行了均值处理,导致了边缘细节的丢失。
作为一个脱离了低级趣味的码农,春节假期闲来无事,决定做一些有意思的事情打发时间,碰巧看到这篇论文: A neural style of convolutional neural networks,译作卷积神经网络风格迁移。 这不是“暮光女”克里斯丁的研究方向吗?!连好莱坞女星都开始搞人工智能发paper,真是热的可见一斑!
这篇文章中讲述了如何用深层卷积神经网络来将一张普通的照片转化成一幅艺术风格的画作(比如梵高的星夜),可以看做是DL(deep learning)在NPR(非真实渲染non photography rendering)领域的一次革命(不难想象以后DL这种跨领域的革命会越来越多)。
论文地址:A Neural Algorithm of Artistic Style
项目地址:https://github.com/muyiguangda/neural-style
算法解析
(对算法不感兴趣的童鞋,可以直接跳过这一部分,看最终实验结果)
【总流程】

如上,a有个别名是conv1_1,b是conv2_1,依次类推,c,d,e对应conv3_1,conv4_1,conv5_1;输入图片有风格图片style image和内容图片content image,输出的是就是合成图片,然后用合成图片为指导训练,但是训练的对象不像是普通的神经网络那样训练权值w和偏置项b,而是训练合成图片上的像素点,以达到损失函数不断减少的效果。论文使用的是随机的噪声像素图为初始合成图,但是使用原始图片会快一点。
首先他定义了两个loss,分别表示最终生成的图x和style图a的样式上的loss,以及x和content图p的内容上的loss,α,β是调节两者比例的参数。最终的loss function是两者的加和。通过optimize总的loss求得最终的x。
所用的CNN网络是VGG-19,利用了它16个卷积层和5个pooling层来生成feature。实际指的是Conv+ReLU的复合体。
当然,使用其他pre-trained的model也是完全可以的,比如GoogLet V2,ResNet,VGG16 都是可以的(作者这哪是以VGG19为例)。
【内容损失函数】

l代表第l层的特征表示,p是原始图片,x是生成图片。
假设某一层得到的响应是Fl∈RNl∗Ml,其中Nl为l层filter的个数,Ml为filter的大小。Flij表示的是第l层第i个filter在位置j的输出。
公式的含义就是对于每一层,原始图片生成特征图和生成图片的特征图的一一对应做平方差
求内容损失函数梯度下降如下:
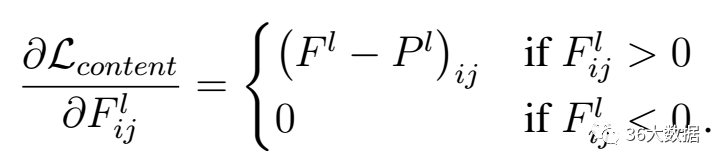
【风格损失函数】
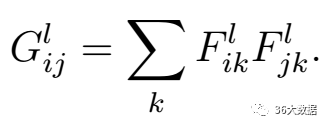
F是生成图片的特征图。上面式子的含义:Gram第i行,第j列的数值等于把生成图在第l层的第i个特征图与第j个特征图分别拉成一维后相乘求和。
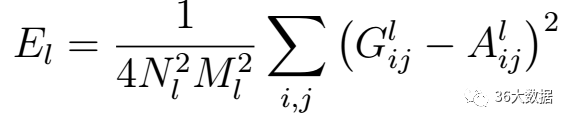
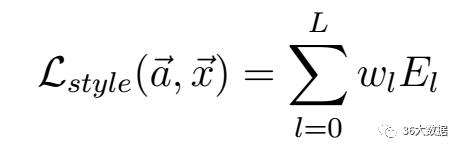
上面是风格损失函数,Nl是指生成图的特征图数量,Ml是图片宽乘高。a是指风格图片,x是指生成图片。G是生成图的Gram矩阵,A是风格图的Gram矩阵,wl是权重。
【总损失】

实验结果
下面是内容图,风格图,以及迭代10次,100次,500次,1000次,10000次,10万次的计算结果及分析:
【原图】
原图片如果尺寸过大,导致input层的batch size过大,会大大增加程序计算量(从而延长计算时间),容易引起程序不稳定,而对最终效果并没有明显提升,因此建议把图片尺寸尽量缩小(在像素不失真的前提下),推荐值:800 ppi x 600 ppi.

【风格图】
风格图不需要和内容图尺寸一致。可以适当裁剪,保留风格最突出的部分。

【迭代10次】
由于原始的输入是一张白噪声图片,因此,在迭代次数较少时,仍然没有形成内容图的轮廓。

【迭代100次】
天安门的轮廓初现

【迭代500次】
已经基本接近最终效果,既能看到天安门的形状,又有梵高“星夜”的线条风格和颜色搭配。

【迭代1000次】
500次到1000次,画面构成的变化已经不剧烈,基本趋于平稳。

【迭代500次,重复执行三次】
重复计算了三次,使用相同的图片,相同的卷积神经网络模型,相同的迭代次数(500次),却得到了区别明显的三张结果图。这是非常有意思的地方!
(a) (b) (c)


最近看完一本书,叫《随机漫步的傻瓜》,主要讨论随机性这个概念,随机性中隐藏着不可预测的风险,也蕴含着无限的可能性。没有随机变异,生物进化可能还处在单细胞阶段。
如果计算机只是一个工具,让它解一个方程组,如果已知数确定,计算条件确定,无论计算多少次,结果都是同一个。
这个例子中,结果出现了差异,说明这个系统中一定有随机的成分存在。
机器学习中随机性出现的部分通常如下:1. 训练样本的乱序操作;2. 随机梯度下降;3. 模型随机赋初始值。
本例中还多一条:初始输入的白噪声图像是随机生成的。
【迭代10000次】
可以看到画面右上部分,内容渐渐丢失,呈现灰色化。
推测原因:由于卷积神经网络中的若干pooling层,实际是对图像进行了均值处理,导致了边缘细节的丢失。

pooling层示意图:
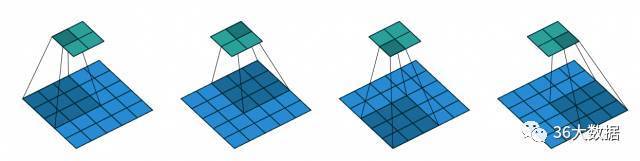
那么,迭代100000次是什么样子的呢?
【迭代十万次】
画面朝着两极化趋势发展,灰色区域更加暗淡,彩色区域更加明亮,两者之间的界限更加分明,失去了过渡。

End.
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4440.html
摘要:这一新程序被称为,是一个完整的深度学习系统,它的架构已经嵌入手机中。因此,移动设备环境对机器学习系统提出了机遇和挑战。展望下一步,加上这样的研究工具链,是的机器学习产品的核心。 风格迁移一直是机器学习领域内的一项重要任务,很多研究机构和研究者都在努力打造速度更快、计算成本更低的风格迁移机器学习系统,比如《怎么让你的照片带上艺术大师风格?李飞飞团队开源快速神经网络风格迁移代码 》、《谷歌增强型...
早期成果卷积神经网络是各种深度神经网络中应用最广泛的一种,在机器视觉的很多问题上都取得了当前较好的效果,另外它在自然语言处理,计算机图形学等领域也有成功的应用。第一个真正意义上的卷积神经网络由LeCun在1989年提出[1],后来进行了改进,它被用于手写字符的识别,是当前各种深度卷积神经网络的鼻祖。接下来我们介绍LeCun在早期提出的3种卷积网络结构。 文献[1]的网络由卷积层和全连接层构成,网络...
摘要:诞生于年,是最早的卷积神经网络之一,并且推动了深度学习领域的发展。间隔从年到年神经网络处于孵化阶段。与来自谷歌的开始追求减少深度神经网络的计算开销,并设计出第一个架构参见。 LeNet5LeNet5 诞生于 1994 年,是最早的卷积神经网络之一,并且推动了深度学习领域的发展。自从 1988 年开始,在许多次成功的迭代后,这项由 Yann LeCun 完成的开拓性成果被命名为 LeNet5(...
摘要:在计算机视觉领域,对卷积神经网络简称为的研究和应用都取得了显著的成果。文章讨论了在卷积神经网络中,该如何调整超参数以及可视化卷积层。卷积神经网络可以完成这项任务。 在深度学习中,有许多不同的深度网络结构,包括卷积神经网络(CNN或convnet)、长短期记忆网络(LSTM)和生成对抗网络(GAN)等。在计算机视觉领域,对卷积神经网络(简称为CNN)的研究和应用都取得了显著的成果。CNN网络最...
摘要:结果,我们当时非常抱以厚望的就是卷积神经网络模型,或者说是。单反相机可以让摄影师调节透镜类型和光圈大小,更好地控制把相片里的哪个部分作为焦点。更进一步,单反相机的传感器更大,对光线更敏感,即使在非常昏暗的环境下也可以拍出非常漂亮的相片。 Yelp的数据库中已经存储了几千万张相片,用户们现在每天都会上传大概十万张,而且速度还在不断加快。事实上,我们发现相片的上传增长率大于相片的查看率。这些相片...

阅读 2518·2021-11-22 09:34
阅读 2416·2021-09-22 15:22
阅读 2312·2019-08-29 15:05
阅读 2368·2019-08-26 10:43
阅读 3648·2019-08-26 10:26
阅读 1337·2019-08-23 18:29
阅读 3787·2019-08-23 16:42
阅读 2257·2019-08-23 14:46






