
摘要:橡树岭国家实验室的研究人员通过使用基于的方法,将数千个网络划分开,在超过个上运行,从而进行大规模深度学习。神经元装置,特别是那些像橡树岭国家实验室开发的脉冲神经网络,,可以卸载一些包含时间序列元素神经网络。

橡树岭国家实验室图
从系统的架构的复杂性上来讲,摩尔定律很难对其适用。
尽管如此,过去两年来,我们一直在迎来了新一轮针对深度学习和其他专业工作的新架构热潮,并涌现出FPGA、更快的GPU,以及迅速出现的开放架构等。这些架构在顶尖的系统架构师中一样不落,它们急于被应用,以建立可以有效消化不断增长的数据集的系统,具有更好的性能、更低的功耗,同时保持可编程性和可扩展性。
橡树岭国家实验室的研究人员通过使用基于MPI的方法,将数千个网络划分开,在超过18000个GPU上运行,从而进行大规模深度学习。正如科研人员所讨论的那样,将深度学习和机器学习添加到超级计算应用程序组合中,可以更好地利用大量的科学数据库,并提高了仿真的复杂性和最终的功能。

Thomas Potok
科学家创建自动生成的神经网络,以方便研究人员对神经网络进行更进一步的硬件调查。托马斯•波托克(Thomas Potok)和他的团队建立了一个新颖的深度学习工作流,充分利用了超级计算机、神经元设备和量子计算机。Thomas E. Potok博士是橡树岭国家实验室(ORNL)计算数据分析小组的创始人。

titan超算图
他们评估了这三个计算平台的优势,并发现他们能够通过使用HPC模拟数据作为其在titan超算上的自动网络工具生成的卷积神经网络的基准线,然后将该网络的单元移动到量子计算机(使用南加州大学 /洛克希德设计的1000量子位计算机)和神经元(由橡树岭国家实验室开发)设备上,来处理他们最擅长的单元。
比较超算、量子计算机和神经元装置在深度学习应用中的性能是比较困难的,因为测量标准是不同的,有各有所长。Potok表示,量子系统可以提供深度连接的网络并表达更多的信息,而不需要传统机器的计算成本,但是,无法跨越整个深度学习工作流。
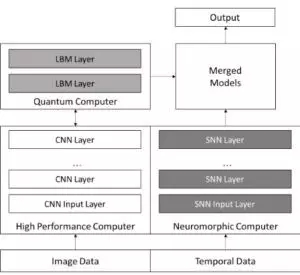
上图显示了ORNL研究人员应用的超混合深度学习架构。数据运行在Titan超算上的卷积网络上,之后移动到量子计算一侧,然后脉冲神经网络/神经元利用以时间为中心的数据深挖这些结果。
神经元装置,特别是那些像橡树岭国家实验室(DANNA)开发的脉冲神经网络(spiking neural network,SNN),可以卸载一些包含时间序列元素神经网络。换句话说,HPC模拟和网络初始化在超级计算机上完成地较好,卷积神经网络的高阶函数可以通过量子机来解决,而结果则可以从神经网络设备以时间层面进行进一步分析。
“有了科学的数据,你通常会得到一个与时间相关的成像。你会得到一个与粒子交互的传感器。对于神经网络,我们可以采用标准卷积神经网络,并且具有互补的脉冲神经网络,用于数据或实验的时间单元。我们可以同时使用这些技术,不仅可以从图像中的某个位置层面看待这个问题,而且可以在时间层面上看待这个问题。”

“三四年前,当我们开始关注这一领域的时候,吴恩达和其他人都试图在节点之间扩展神经网络。问题是,人们没法超过64个节点”,Potok解释说,“我们采取了不同的做法;我们选择了难度较大的挑战,通过配置网络、构建拓扑和参数,并使用进化优化来自动配置它,而不是建立一个巨大的18000个节点的深度学习系统,我们使它成为了一个优化问题。
“大公司已经能够自动执行标注图像或识别语音,但是这需要很多人为这些网络辛苦工作。在HPC中,有很多数据集,但是没有很多人在使用它们,了解它们的人更少,”Potok说。“试图建立一个在那里工作的深度学习网络将是艰巨的,这就是HPC开始流行的原因。我们可以很快地为一个新的数据集定制一个深度学习网络,并快速获得结果。最重要的是,它可以在Titan上进行扩展,然后到Summit超算或者是一台超级计算机上。”

所有这些可能听起来像是对集成发起了挑战,即许多数据类型的工作朝着同一个最终结果进行——即使在整个问题中,输入和输出在分布式网络上是分步生成的。Potok认为上述的架构确实有效,但实际测试将会合并CNN和SNN,看看可能会取得什么样的结果。最终,较大的问题就是混合架构如何需要满足计算和应用需求。拥有一种新的、更强大的、可扩展的方式来创建更复杂的模拟结果将是有益的,但是很多设备尚未规模化生产。
当然,超大型理论工作是国家实验室最擅长的部分,但这可能会超越下一代机器的概念。Potok并不认为在未来五年内会出现如此大规模的混合体系结构,而是认为,在未来十年,所有三种计算模式都将有希望。换句话说,不仅计算平台是全新的,而且解决问题的方式也是全新的。
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4511.html
摘要:在经历五年多的落后之后,如今美国终于在超级计算机领域再度超越中国,重夺头名桂冠。这一消息在本周于德国法兰克福举行的年度国际超级计算机大会上正式公布。在经历五年多的落后之后,如今美国终于在超级计算机领域再度超越中国,重夺头名桂冠。这台由IBM公司为田纳西州橡树岭国家实验室建造的Summit超级计算机(如上图所示)在本周一发布的全球超算五百强中位列第一(这份榜单每年发布两轮,列举世界上五百台最为...
摘要:现在,腾讯正在将新服务器集成到它为大数据工作负载提供服务的超大规模数据中心上。这将有助于腾讯抑制数据中心的扩张。 上图:IBM 为高性能计算提供的Linux 服务器,图片来源:IBMIBM已经推出了三代Power8 Linux服务器,旨在加快人工智能、深度学习和先进分析的应用。IBM的副总裁Stefanie Chiras在VentureBeat的采访中说,这个新系统开发了Nvidia NVL...
摘要:深度学习方法是否已经强大到可以使科学分析任务产生最前沿的表现在这篇文章中我们介绍了从不同科学领域中选择的一系列案例,来展示深度学习方法有能力促进科学发现。 深度学习在很多商业应用中取得了前所未有的成功。大约十年以前,很少有从业者可以预测到深度学习驱动的系统可以在计算机视觉和语音识别领域超过人类水平。在劳伦斯伯克利国家实验室(LBNL)里,我们面临着科学领域中最具挑战性的数据分析问题。虽然商业...
摘要:而从贝叶斯概率视角描述深度学习会产生很多优势,即具体从统计的解释和属性,从对优化和超参数调整更有效的算法,以及预测性能的解释这几个方面进一步阐述。贝叶斯层级模型和深度学习有很多相似的优势。 论文地址:https://arxiv.org/abs/1706.00473深度学习是一种为非线性高维数据进行降维和预测的机器学习方法。而从贝叶斯概率视角描述深度学习会产生很多优势,即具体从统计的解释和属性...
摘要:,,微软显然位居第二,占有大约的市场份额,领先于和谷歌,位列第三和阿里巴巴。与此同时,谷歌一年来情绪错综复杂。然而,谷歌云主管的离开,使得不久的将来成为一个有趣的未来。,对已经过度紧张的安全部门的沉重负担。永别了,2018年,大家好,2019年:云计算的最后12个月——以及HorizonTweet2018年是另一个精彩的一年,当它涉及到云计算时,伴随着新兴的技术,这些技术补充并依赖于云。相应...

阅读 4373·2021-09-22 16:03
阅读 5730·2021-09-22 15:40
阅读 1555·2021-09-06 15:02
阅读 1072·2019-08-30 15:53
阅读 2549·2019-08-29 15:35
阅读 1300·2019-08-23 18:22
阅读 3583·2019-08-23 16:06
阅读 811·2019-08-23 12:27






