
摘要:调研首先要确定微博领域的数据,关于微博的数据可以这样分类用户基础数据年龄性别公司邮箱地点公司等。这意味着深度学习在推荐领域应用的关键技术点已被解决。
当2012年Facebook在广告领域开始应用定制化受众(Facebook Custom Audiences)功能后,“受众发现”这个概念真正得到大规模应用,什么叫“受众发现”?如果你的企业已经积累了一定的客户,无论这些客户是否关注你或者是否跟你在Facebook上有互动,都能通过Facebook的广告系统触达到。“受众发现”实现了什么功能?在没有这个系统之前,广告投放一般情况都是用标签去区分用户,再去给这部分用户发送广告,“受众发现”让你不用选择这些标签,包括用户基本信息、兴趣等。你需要做的只是上传一批你目前已有的用户或者你感兴趣的一批用户,剩下的工作就等着Custom Audiences帮你完成了。
Facebook这种通过一群已有的用户发现并扩展出其他用户的推荐算法就叫Lookalike,当然Facebook的算法细节笔者并不清楚,各个公司实现Lookalike也各有不同。这里也包括腾讯在微信端的广告推荐上的应用、Google在YouTube上推荐感兴趣视频等。下面让我们结合前人的工作,实现自己的Lookalike算法,并尝试着在新浪微博上应用这一算法。
调研
首先要确定微博领域的数据,关于微博的数据可以这样分类:
用户基础数据:年龄、性别、公司、邮箱、地点、公司等。
关系图:根据人↔人,人↔微博的关注、评论、转发信息建立关系图。
内容数据:用户的微博内容,包含文字、图片、视频。
有了这些数据后,怎么做数据的整合分析?来看看现在应用最广的方式——协同过滤、或者叫关联推荐。协同过滤主要是利用某兴趣相投、拥有共同经验群体的喜好来推荐用户可能感兴趣的信息,协同过滤的发展有以下三个阶段:
第一阶段,基于用户喜好做推荐,用户A和用户B相似,用户B购买了物品a、b、c,用户A只购买了物品a,那就将物品b、c推荐给用户A。这就是基于用户的协同过滤,其重点是如何找到相似的用户。因为只有准确的找到相似的用户才能给出正确的推荐。而找到相似用户的方法,一般是根据用户的基本属性贴标签分类,再高级点可以用上用户的行为数据。
第二阶段,某些商品光从用户的属性标签找不到联系,而根据商品本身的内容联系倒是能发现很多有趣的推荐目标,它在某些场景中比基于相似用户的推荐原则更加有效。比如在购书或者电影类网站上,当你看一本书或电影时,推荐引擎会根据内容给你推荐相关的书籍或电影。
第三阶段,如果只把内容推荐多带带应用在社交网络上,准确率会比较低,因为社交网络的关键特性还是社交关系。如何将社交关系与用户属性一起融入整个推荐系统就是关键。在神经网络和深度学习算法出现后,提取特征任务就变得可以依靠机器完成,人们只要把相应的数据准备好就可以了,其他数据都可以提取成向量形式,而社交关系作为一种图结构,如何表示为深度学习可以接受的向量形式,而且这种结构还需要有效还原原结构中位置信息?这就需要一种可靠的向量化社交关系的表示方法。基于这一思路,在2016年的论文中出现了一个算法node2vec,使社交关系也可以很好地适应神经网络。这意味着深度学习在推荐领域应用的关键技术点已被解决。
在实现算法前我们主要参考了如下三篇论文:
Audience Expansion for Online Social Network Advertising 2016
node2vec: Scalable Feature Learning for Networks Aditya Grover 2016
Deep Neural Networks for YouTube Recommendations 2016
第一篇论文是LinkedIn给出的,主要谈了针对在线社交网络广告平台,如何根据已有的受众特征做受众群扩展。这涉及到如何定位目标受众和原始受众的相似属性。论文给出了两种方法来扩展受众:
1. 与营销活动无关的受众扩展;
2. 与营销活动有关的受众扩展。
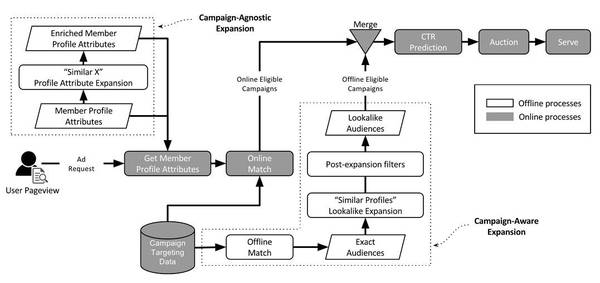
图1 LinkedIn的Lookalike算法流程图
在图1中,LinkedIn给出了如何利用营销活动数据、目标受众基础数据去预测目标用户行为进而发现新的用户。今天的推荐系统或广告系统越来越多地利用了多维度信息。如何将这些信息有效加以利用,这篇论文给出了一条路径,而且在工程上这篇论文也论证得比较扎实,值得参考。
第二篇论文,主要讲的是node2vec,这也是本文用到的主要算法之一。node2vec主要用于处理网络结构中的多分类和链路预测任务,具体来说是对网络中的节点和边的特征向量表示方法。
简单来说就是将原有社交网络中的图结构,表达成特征向量矩阵,每一个node(可以是人、物品、内容等)表示成一个特征向量,用向量与向量之间的矩阵运算来得到相互的关系。
下面来看看node2vec中的关键技术——随机游走算法,它定义了一种新的遍历网络中某个节点的邻域的方法,具体策略如图2所示。

图2 随机游走策略
假设我们刚刚从节点t走到节点v,当前处于节点v,现在要选择下一步该怎么走,方案如下:
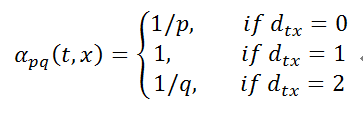
其中dtx表示节点t到节点x之间的最短路径,dtx=0表示会回到节点t本身,dtx =1表示节点t和节点x直接相连,但是在上一步却选择了节点v,dtx=2表示节点t不与x直接相连,但节点v与x直接相连。其中p和q为模型中的参数,形成一个不均匀的概率分布,最终得到随机游走的路径。与传统的图结构搜索方法(如BFS和DFS)相比,这里提出的随机游走算法具有更高的效率,因为本质上相当于对当前节点的邻域节点的采样,同时保留了该节点在网络中的位置信息。
node2vec由斯坦福大学提出,并有开源代码,这里顺手列出,这一部分大家不用自己动手实现了。https://github.com/aditya-grover/node2vec
注:本文的方法需要在源码的基础上改动图结构。
第三篇论文讲的是Google如何做YouTube视频推荐,论文是在我做完结构设计和流程设计后看到的,其中模型架构的思想和我们不谋而合,还解释了为什么要引入DNN(后面提到所有的feature将会合并经历几层全连接层):引入DNN的好处在于大多数类型的连续特征和离散特征可以直接添加到模型当中。此外我们还参考了这篇论文对于隐含层(FC)单元个数选择。图3是这篇论文提到的算法结构。
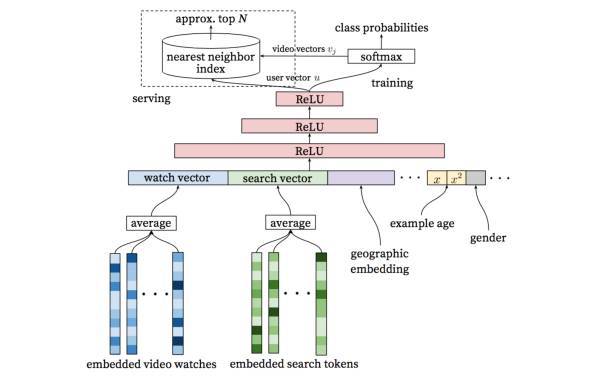
图3 YouTube推荐结构图
实现
(a)数据准备
获得用户的属性(User Profile),如性别、年龄、学历、职业、地域、能力标签等;
根据项目内容和活动内容制定一套受众标签(Audience Label);
提取用户之间的关注关系,微博之间的转发关系;
获取微博message中的文本内容;
获得微博message中的图片内容。
(b)用户标签特征处理
根据步骤a中用户属性信息和已有的部分受众标签系统。利用GBDT算法(可以直接用xgboost)将没有标签的受众全部打上标签。这个分类问题中请注意处理连续值变量以及归一化。
将标签进行向量化处理,这个问题转化成对中文单词进行向量化,这里用word2vec处理后得到用户标签的向量化信息Label2vec。这一步也可以使用word2vec在中文的大数据样本下进行预训练,再用该模型对标签加以提取,对特征的提取有一定的提高,大约在0.5%左右。
(c)文本特征处理
将步骤a中提取到的所有微博message文本内容清洗整理,训练Doc2Vec模型,得到单个文本的向量化表示,对所得的文本作聚类(KMeans,在30w的微博用户的message上测试,K取128对文本的区分度较强),最后提取每个cluster的中心向量,并根据每个用户所占有的cluster获得用户所发微博的文本信息的向量表示Content2vec。
(d)图像特征(可选)
将步骤a中提取到的所有的message图片信息整理分类,使用预训练卷积网络模型(这里为了平衡效率选取VGG16作为卷积网络)提取图像信息,对每个用户message中的图片做向量化处理,形成Image2vec,如果有多张图片将多张图片分别提取特征值再接一层MaxPooling提取重要信息后输出。
(e)社交关系建立(node2vec向量化)
将步骤a中获得到的用户之间的关系和微博之间的转发评论关系转化成图结构,并提取用户关系sub-graph,最后使用node2Vec算法得到每个用户的社交网络图向量化表示。
图4为简历社交关系后的部分图示。
图4 用户社交关系
(f)将bcde步骤得到的向量做拼接,经过两层FC,得到表示每个用户的多特征向量集(User Vector Set, UVS)。这里取的输出单元个数时可以根据性能和准确度做平衡,目前我们实现的是输出512个单元,最后的特征输出表达了用户的社交关系、用户属性、发出的内容、感兴趣的内容等的混合特征向量,这些特征向量将作为下一步比对相似性的输入值。
(g)分别计算种子用户和潜在目标用户的向量集,并比对相似性,我们使用的是余弦相似度计算相似性,将步骤f得到的用户特征向量集作为输入x,y,代入下面公式计算相似性:
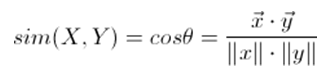
使用余弦相似度要注意:余弦相似度更多的是从方向上区分差异,而对的数值不敏感。因此没法衡量每个维度值的差异,这里我们要在每个维度上减去一个均值或者乘以一个系数,或者在之前做好归一化。
(h)受众扩展
获取种子受众名单,以及目标受众的数量N;
检查种子用户是否存在于UVS中,将存在的用户向量化;
计算受众名单中用户和UVS中用户的相似度,提取最相似的前N个用户作为目标受众。
最后我们将以上步骤串联起来,形成如图5所示。
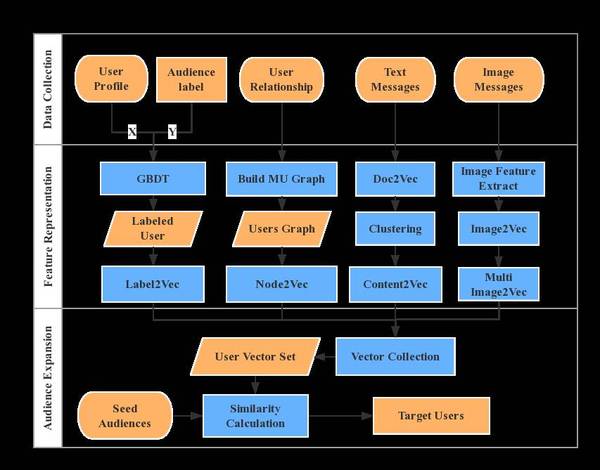
图5 Lookalike算法示意图
在以上步骤中特征提取完成后,我们使用一个2层的神经网络做最后的特征提取,算法结构示意图如图6所示。

图6 Lookalike算法结构图
其中FC1层也可以替换成MaxPooling,MaxPooling层具有强解释性,也就是在用户特征群上提取最重要的特征点作为下一层的输入,读者可以自行尝试,这里限于篇幅问题就不做展开了。
讲到这里,算法部分就已基本完结,其中还有些工程问题,并不属于本次主题探讨范围,这里也不做讨论了。
结果
我司算法团队根据Lookalike思想完整实现其算法,并在实际产品中投入试用。针对某客户(乳品领域世界排名前三的品牌主)计算出结果(部分):
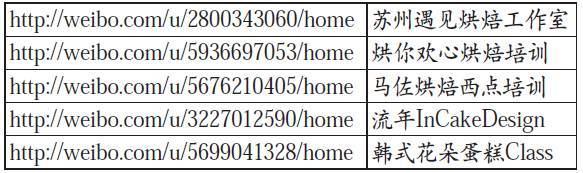
表1 部分计算结果
可以观察到以上微博ID的主题基本都是西点企业或西点培训企业,和品牌主售卖的乳品有很高的关联性:乳品是非常重要的西点原料,除终端用户外,西点相关企业就是乳品企业主需要寻找的最重要的受众之一。
探讨
特征表达
除了以上提到的特征外,我们也对其他的重要特征表达做了处理和变换:根据我们的需求,需要抽取出人的兴趣特征,如何表达一个人的兴趣?除了他自己生成的有关内容外,还有比较关键的一点是比如“我”看了一些微博,但并没有转发,大多数情况下都不会转发,但有些“我”转发了,有些“我”评论了;“我”转发了哪些?评论了哪些?这次距上次的浏览该人的列表时间间隔多久?都代表“我”对微博的兴趣,而间接的反应“我”的兴趣特征。这些数据看来非常重要,又无法直接取得,怎么办?
下面来定义一个场景,试图描述出我们对看过的内容中哪些是感兴趣的,哪些不是感兴趣的:
(a)用户A,以及用户A关注的用户B;
(b)用户A的每天动作时间(比如他转发、评论、收藏、点赞)起始时间,我们定义为苏醒时间A_wake(t);
(c)用户B每天发帖(转发、评论)时间:B_action(t);
(d)简单假设一下A_wake(t)> B_action(t),也就是B_action(t)的评论都能看到。这就能得到用户A对应了哪些帖子;
(e)同理,也可知用户A 在A_wake(t)时间内转发了、评论了哪些帖子;
(f)结合上次浏览间隔时间,可以描述用户A对哪些微博感兴趣(post ive),哪些不感兴趣(negative)。
全连接层的激活单元比对提升
在Google那篇论文中比对隐含层(也就是我们结构图中的FC层)各种单元组合产生的结果,Google选择的是最后一种组合,如图7所示。
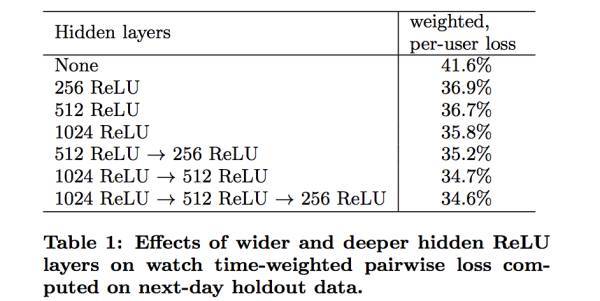
图7 YouTube推荐模型隐含层单元选择对比
我们初期选用了512 tanh→256 tanh 这种两层组合,后认为输入特征维度过大,512个单元无法完整的表达特征,故又对比了 1024→512组合,发现效果确实有微小提升大概在0.7%。另外我们的FC层输入在(-1,1)区间,考虑到relu函数的特点没有使用它,而是使用elu激活函数。测试效果要比tanh函数提升0.3%-0.5%。
附node2vec伪码:

感谢我司算法组周维在拟写这篇文章时提供的帮助。
作者简介
吴岸城,菱歌科技首席算法科学家,致力于深度学习在文本、图像、预测推荐领域的应用。曾在中兴通讯、亚信(中国)担任研发经理、高级技术经理等职务。
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4553.html
摘要:是你学习从入门到专家必备的学习路线和优质学习资源。的数学基础最主要是高等数学线性代数概率论与数理统计三门课程,这三门课程是本科必修的。其作为机器学习的入门和进阶资料非常适合。书籍介绍深度学习通常又被称为花书,深度学习领域最经典的畅销书。 showImg(https://segmentfault.com/img/remote/1460000019011569); 【导读】本文由知名开源平...
摘要:通过书籍学习,比如除了上述的先学知识,你还应该了解一些流行的深度学习库和运行他们的语言。你也可以查看查看的中的第讲,概要性的了解一些深度学习库。 作者:chen_h微信号 & QQ:862251340微信公众号:coderpai简书地址:https://www.jianshu.com/p/cd0... 原文:https://www.analyticsvidhya.c... 介绍 ...
摘要:普通程序员,如何转向人工智能方向,是知乎上的一个问题。领域简介,也就是人工智能,并不仅仅包括机器学习。但是,人工智能并不等同于机器学习,这点在进入这个领域时一定要认识清楚。 人工智能已经成为越来越火的一个方向。普通程序员,如何转向人工智能方向,是知乎上的一个问题。本文是对此问题的一个回答的归档版。相比原回答有所内容增加。 目的 本文的目的是给出一个简单的,平滑的,易于实现的学习方法,帮...
摘要:因为在每一时刻对过去的记忆信息和当前的输入处理策略都是一致的,这在其他领域如自然语言处理,语音识别等问题不大,但并不适用于个性化推荐,一个用户的听歌点击序列,有正负向之分。 在内容爆炸性增长的今天,个性化推荐发挥着越来越重要的作用,如何在海量的数据中帮助用户找到感兴趣的物品,成为大数据领域极具挑战性的一项工作;另一方面,深度学习已经被证明在图像处理,计算机视觉,自然语言处理等领域都取得了不俗...
摘要:为了更好地为机器学习或深度学习提供先验知识,知识图谱的表示学习仍是一项任重道远的研究课题。 肖仰华:复旦大学计算机科学技术学院,副教授,博士生导师,上海市互联网大数据工程技术中心副主任。主要研究方向为大数据管理与挖掘、知识库等。大数据时代的到来,为人工智能的飞速发展带来前所未有的数据红利。在大数据的喂养下,人工智能技术获得了前所未有的长足进步。其进展突出体现在以知识图谱为代表的知识工程以及深...
摘要:阿里妹导读作为大神,贾扬清让人印象深刻的可能是他写的框架,那已经是六年前的事了。经过多年的沉淀,成为阿里新人的他,对人工智能又有何看法最近,贾扬清在阿里内部分享了他的思考与洞察,欢迎共同探讨交流。 showImg(https://segmentfault.com/img/remote/1460000018868775); 阿里妹导读:作为 AI 大神,贾扬清让人印象深刻的可能是他写的...

阅读 2608·2021-09-28 09:36
阅读 3806·2021-09-22 15:41
阅读 4824·2021-09-04 16:45
阅读 2356·2019-08-30 15:55
阅读 2951·2019-08-30 13:49
阅读 961·2019-08-29 16:34
阅读 2485·2019-08-29 12:57
阅读 1814·2019-08-26 18:42







