
摘要:在一个数据分析任务和任务混合的环境中,大数据分析任务也会消耗很多网络带宽如操作,网络延迟会更加严重。本地更新更新更新目前,我们已经复现中的实验结果,实现了多机并行的线性加速。
王佐,天数润科深度学习平台负责人,曾担任 Intel亚太研发中心Team Leader,万达人工智能研究院资深研究员,长期从事分布式计算系统研究,在大规模分布式机器学习系统架构、机器学习算法设计和应用方面有深厚积累。
在上一家公司就开始实践打磨一个深度优化的深度学习系统,当时从消除网络瓶颈,非凸优化,以及具体的深度学习算法等方面基于PaddlePaddle做了许多工作。目前公司主要深度学习算法都是跑在TensorFlow上,使用配置了GeForce GTX 1080的单机训练,一次完整的训练至少需要一周的时间,所以决定从优化TensorFlow多机并行方面提高算力。
为什么要优化 Tensorflow 多机并行
更多的数据可以提高预测性能[2],这也意味着更沉重的计算负担,未来计算力将成为AI发展的较大瓶颈。在大数据时代,解决存储和算力的方法是Scale out,在AI时代,Scale out也一定是发展趋势,并且大数据分析任务和AI/ML任务会共享处理设备(由于AI/ML迭代收敛和容错的特征,这两种任务未来不太可能使用统一平台),所以需要在分布式环境下优化资源配置[3],消除性能瓶颈。虽然现在TensorFlow能支持多机并行分布式训练,但是针对复杂网络,其训练速度反而不如单台机器[1]。目前已经有IBM[4]和Petuum[1]分别在其深度学习系统PowerAI 4.0和Poseidon中实现多机并行线性加速,本文介绍我如何通过消除TensorFlow的网络瓶颈,实现TensorFlow多机并行线性加速。
TensorFlow分布式训练的网络瓶颈分析
深度学习训练需要海量的数据,这就需要超大规模参数的网络模型拟合。如果训练数据不足,会造成欠拟合;如果网络模型参数太少,只会得到低精度的模型。目前常见网络模型参数已经上亿,参数大小达到数GB。[10]中给出了训练数据和参数大小一些例子。
训练数据和参数大小(来自[10])

目前GPU已经成为深度学习训练的标配。GPU具有数量众多计算单元和超长流水线,并且具备强大并行计算能力与浮点计算能力,可以大幅加速深度学习模型的训练速度,相比CPU能提供更快的处理速度、更少的服务器投入和更低的功耗。这也意味着,GPU集群上训练深度学习模型,迭代时间更短,参数同步更频繁。[9]中对比了主流深度学习系统在CPU和GPU上的训练性能,可以看出GPU每次迭代的时间比CPU少2个数量级。
CPU 训练 alexnet(来自[9])
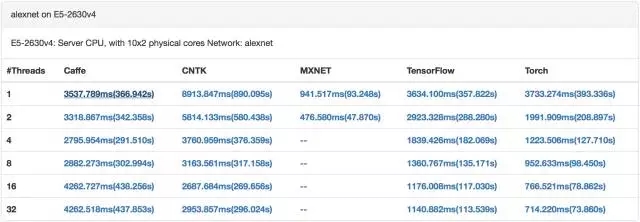
GPU 训练alexnet(来自[9])
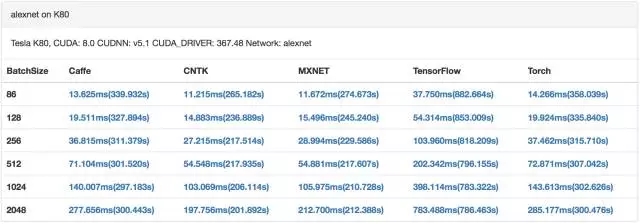
假设每0.5秒一个迭代,每个worker每秒需要通过网络传输的大于4GB,即使使用10GbE,参数同步也会瞬间把网络占满。考虑到训练数据可能通过NFS或者HDFS加载,也会占用很多网络带宽。在一个数据分析任务和AI/ML任务混合的环境中,大数据分析任务也会消耗很多网络带宽(如shuffle操作),网络延迟会更加严重。所以如果想以Scale out的方式提升算力,网络将是较大的瓶颈。[1]中通过实验证明,在8个节点进行TensorFlow分布式训练,对于VGG19网络,90%的时间花在等待网络传输上面。
网络开销(来自[2])

消除网络瓶颈的方法(一)
分布式深度学习可以采用BSP和SSP两种模式。SSP通过允许faster worker使用staled参数,从而达到平衡计算和网络通信开销时间的效果[8]。SSP每次迭代收敛变慢,但是每次迭代时间更短,在CPU集群上,SSP总体收敛速度比BSP更快,但是在GPU集群上训练,BSP总体收敛速度比SSP反而快很多[6]。
BSP模型有个缺点,就是每次迭代结束,Worker需要发送梯度更新到PS,每次迭代开始,Worker需要从PS接收更新后的参数,这会造成瞬间大量的网络传输。参数服务器通过把参数切分成block,并且shard到多台机器,比较AllReduce,有效利用网络带宽,降低网络延迟。目前主流的深度学习系统(TensorFlow,Mxnet,Petuum)都选择用参数服务器做参数同步。
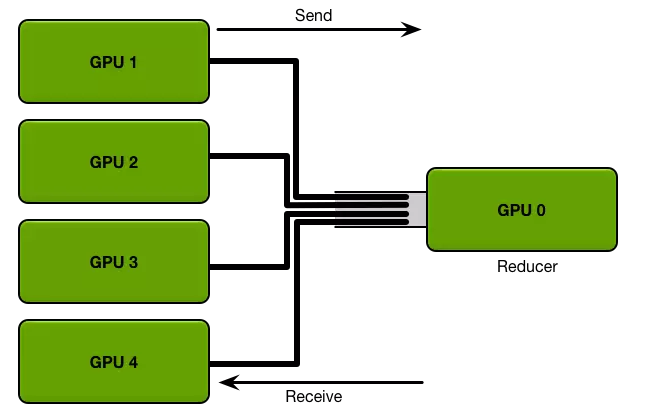
AllReduce(来自[5])
Parameter Server
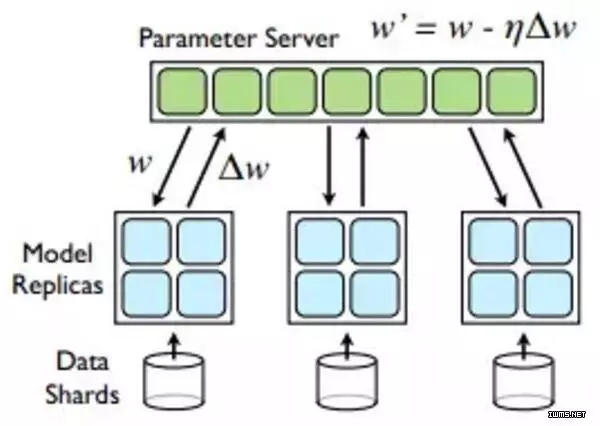
上图可以很容易看出,AllReduce拓扑中,Reducer节点成为网络传输的瓶颈。PS拓扑中,通常每台机器启动相同数量的Worker和Parameter Server,每台机器的网络传输量基本相同。
ring AllReduce(来自[5])
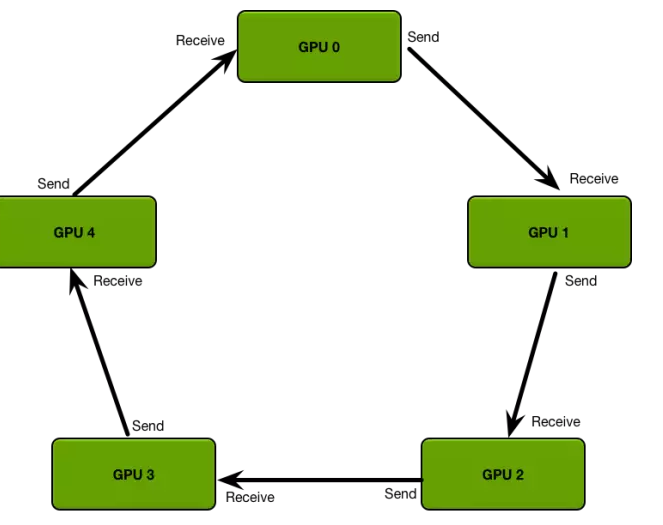
对于多机多卡训练,可以把参数现在本机聚合,再指定一个worker跟参数服务器交互,可以大量减少网络传输。可以使用PaddlePaddle提出来的ring AllReduce,优化单机多卡的本地聚合。
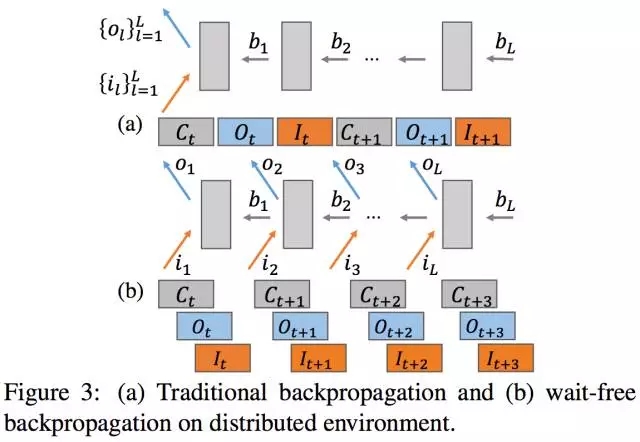
解决瞬间大量的网络传输问题另一个方法是实现GPU计算和网络通信的Overlap。在反向传播的backward阶段产生梯度时,可异步地进行梯度更新,并立即计算下一层网络的梯度。梯度更新首先要把新梯度从GPU显存拷贝到CPU内存,这种GPU-CPU的拷贝也可以和GPU计算做Overlap。因为PS是跑在CPU上,所以GPU计算也跟PS参数更新实现Overlap。
GPU计算和网络传输overlap(来自[1])
消除网络瓶颈的方法(二)
减少网络传输量也是消除网络瓶颈的有效途径。网络模型中90%参数集中在FC层。很多深度学习系统提出了减少FC层参数大小的方法,比如Adam中的Sufficient Factor,CNTK中的 1-bit quantization,Petuum中的Sufficient Factor Broadcasting[7]。

实现代码
首先得实现PS和SFB,可以参照petuum,ps-lite,angel。
TensorFlow 相关的修改主要有两个地方:

2. tensorflow/core/kernels/http://matmul_op.cc中的MalMulOp::Compute,这里需要判断是否使用PS或者SFB,从而将本地更新切换为PS更新或SFB更新。
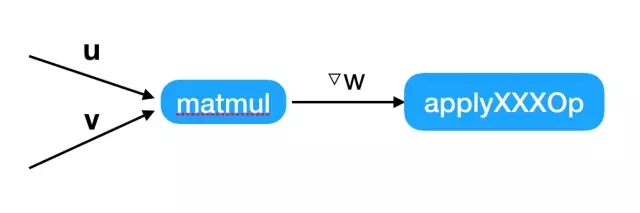
本地更新
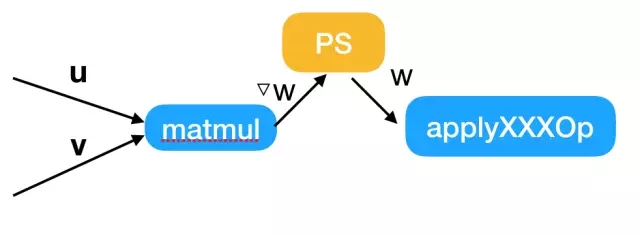
PS更新
SFB更新
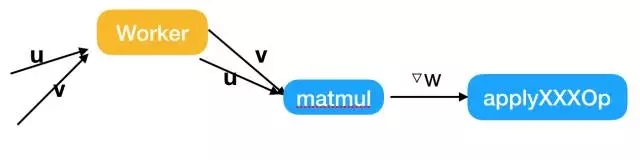
目前,我们已经复现[1]中的实验结果,实现了Tensorflow多机并行的线性加速。我们还在 Tensorflow 其他方面进行优化。
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4605.html
摘要:本文内容节选自由主办的第七届,北京一流科技有限公司首席科学家袁进辉老师木分享的让简单且强大深度学习引擎背后的技术实践实录。年创立北京一流科技有限公司,致力于打造分布式深度学习平台的事实工业标准。 本文内容节选自由msup主办的第七届TOP100summit,北京一流科技有限公司首席科学家袁进辉(老师木)分享的《让AI简单且强大:深度学习引擎OneFlow背后的技术实践》实录。 北京一流...

阅读 922·2021-09-22 15:18
阅读 1295·2021-09-09 09:33
阅读 2846·2019-08-30 10:56
阅读 1346·2019-08-29 16:30
阅读 1580·2019-08-29 13:02
阅读 1536·2019-08-26 13:55
阅读 1768·2019-08-26 13:41
阅读 2064·2019-08-26 11:56


