
摘要:原始版本最早的卷积方式还没有任何骚套路,那就也没什么好说的了。通过卷积核插的方式,它可以比普通的卷积获得更大的感受野,这个的就介绍到这里。和前面不同的是,这个卷积是对特征维度作改进的。
1.原始版本
最早的卷积方式还没有任何骚套路,那就也没什么好说的了。
见下图,原始的conv操作可以看做一个2D版本的无隐层神经网络。
附上一个卷积详细流程:
【TensorFlow】tf.nn.conv2d是怎样实现卷积的? - CSDN博客
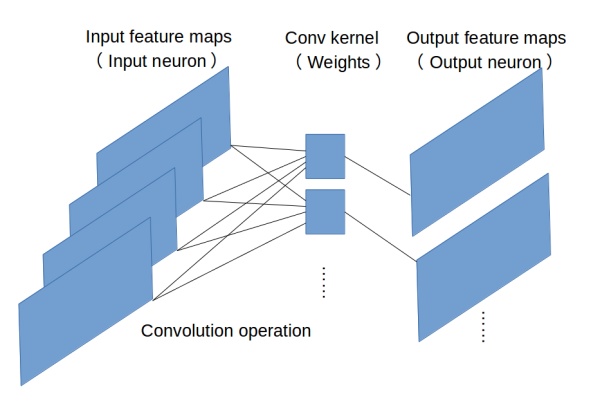
代表模型:
LeNet:最早使用stack单卷积+单池化结构的方式,卷积层来做特征提取,池化来做空间下采样
AlexNet:后来发现单卷积提取到的特征不是很丰富,于是开始stack多卷积+单池化的结构
VGG([1409.1556] Very Deep Convolutional Networks for Large-Scale Image Recognition):结构没怎么变,只是更深了
2.多隐层非线性版本
这个版本是一个较大的改进,融合了Network In Network的增加隐层提升非线性表达的思想,于是有了这种先用1*1的卷积映射到隐空间,再在隐空间做卷积的结构。同时考虑了多尺度,在单层卷积层中用多个不同大小的卷积核来卷积,再把结果concat起来。
这一结构,被称之为“Inception”
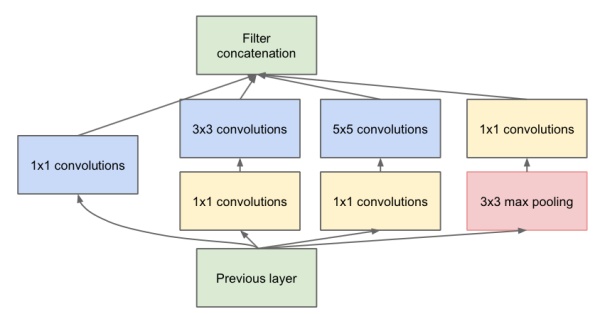
代表模型:
Inception-v1([1409.4842] Going Deeper with Convolutions):stack以上这种Inception结构
Inception-v2(Accelerating Deep Network Training by Reducing Internal Covariate Shift):加了BatchNormalization正则,去除5*5卷积,用两个3*3代替
Inception-v3([1512.00567] Rethinking the Inception Architecture for Computer Vision):7*7卷积又拆成7*1+1*7
Inception-v4([1602.07261] Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning):加入了残差结构
3.空洞卷积
Dilation卷积,通常译作空洞卷积或者卷积核膨胀操作,它是解决pixel-wise输出模型的一种常用的卷积方式。一种普遍的认识是,pooling下采样操作导致的信息丢失是不可逆的,通常的分类识别模型,只需要预测每一类的概率,所以我们不需要考虑pooling会导致损失图像细节信息的问题,但是做像素级的预测时(譬如语义分割),就要考虑到这个问题了。
所以就要有一种卷积代替pooling的作用(成倍的增加感受野),而空洞卷积就是为了做这个的。通过卷积核插“0”的方式,它可以比普通的卷积获得更大的感受野,这个idea的motivation就介绍到这里。具体实现方法和原理可以参考如下链接:
如何理解空洞卷积(dilated convolution)?
膨胀卷积--Multi-scale context aggregation by dilated convolutions
我在博客里面又做了一个空洞卷积小demo方便大家理解
【Tensorflow】tf.nn.atrous_conv2d如何实现空洞卷积? - CSDN博客
代表模型:
FCN([1411.4038] Fully Convolutional Networks for Semantic Segmentation):Fully convolutional networks,顾名思义,整个网络就只有卷积组成,在语义分割的任务中,因为卷积输出的feature map是有spatial信息的,所以最后的全连接层全部替换成了卷积层。
Wavenet(WaveNet: A Generative Model for Raw Audio):用于语音合成。
4.深度可分离卷积
Depthwise Separable Convolution,目前已被CVPR2017收录,这个工作可以说是Inception的延续,它是Inception结构的极限版本。
为了更好的解释,让我们重新回顾一下Inception结构(简化版本):
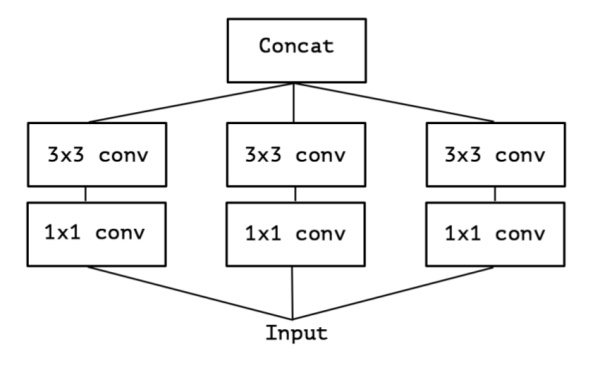
上面的简化版本,我们又可以看做,把一整个输入做1*1卷积,然后切成三段,分别3*3卷积后相连,如下图,这两个形式是等价的,即Inception的简化版本又可以用如下形式表达:
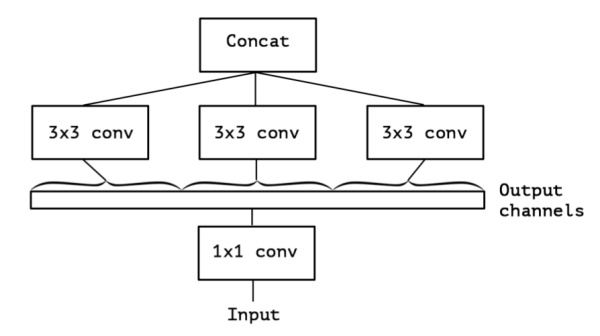
OK,现在我们想,如果不是分成三段,而是分成5段或者更多,那模型的表达能力是不是更强呢?于是我们就切更多段,切到不能再切了,正好是Output channels的数量(极限版本):
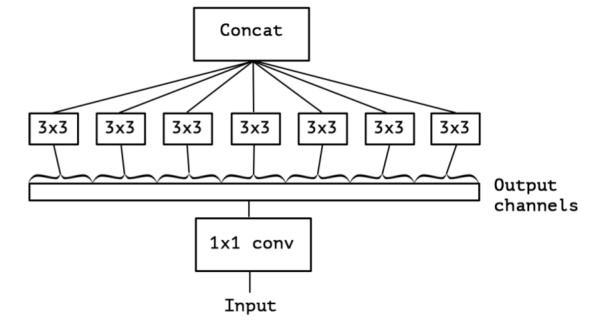
于是,就有了深度卷积(depthwise convolution),深度卷积是对输入的每一个channel独立的用对应channel的所有卷积核去卷积,假设卷积核的shape是[filter_height, filter_width, in_channels, channel_multiplier],那么每个in_channel会输出channel_multiplier那么多个通道,最后的feature map就会有in_channels * channel_multiplier个通道了。反观普通的卷积,输出的feature map一般就只有channel_multiplier那么多个通道。
具体的过程可参见我的demo:
【Tensorflow】tf.nn.depthwise_conv2d如何实现深度卷积? - CSDN博客
既然叫深度可分离卷积,光做depthwise convolution肯定是不够的,原文在深度卷积后面又加了pointwise convolution,这个pointwise convolution就是1*1的卷积,可以看做是对那么多分离的通道做了个融合。
这两个过程合起来,就称为Depthwise Separable Convolution了:
【Tensorflow】tf.nn.separable_conv2d如何实现深度可分卷积? - CSDN博客
代表模型:Xception(Xception: Deep Learning with Depthwise Separable Convolutions)
5.可变形卷积
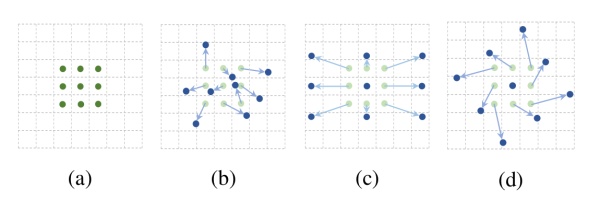
可形变卷积的思想很巧妙:它认为规则形状的卷积核(比如一般用的正方形3*3卷积)可能会限制特征的提取,如果赋予卷积核形变的特性,让网络根据label反传下来的误差自动的调整卷积核的形状,适应网络重点关注的感兴趣的区域,就可以提取更好的特征。
如下图:网络会根据原位置(a),学习一个offset偏移量,得到新的卷积核(b)(c)(d),那么一些特殊情况就会成为这个更泛化的模型的特例,例如图(c)表示从不同尺度物体的识别,图(d)表示旋转物体的识别。
这个idea的实现方法也很常规:
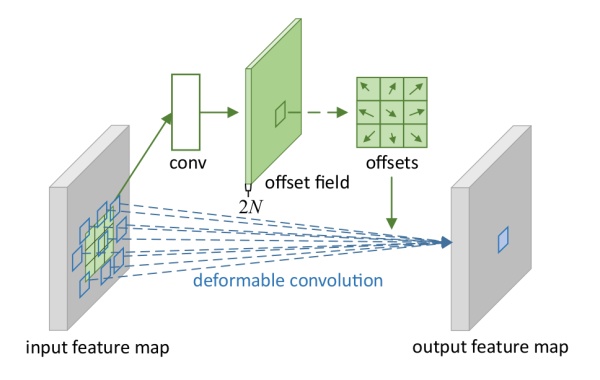
上图中包含两处卷积,第一处是获取offsets的卷积,即我们对input feature map做卷积,得到一个输出(offset field),然后再在这个输出上取对应位置的一组值作为offsets。假设input feature map的shape为[batch,height,width,channels],我们指定输出通道变成两倍,卷积得到的offset field就是[batch,height,width,2×channels],为什么指定通道变成两倍呢?因为我们需要在这个offset field里面取一组卷积核的offsets,而一个offset肯定不能一个值就表示的,最少也要用两个值(x方向上的偏移和y方向上的偏移)所以,如果我们的卷积核是3*3,那意味着我们需要3*3个offsets,一共需要2*3*3个值,取完了这些值,就可以顺利使卷积核形变了。第二处就是使用变形的卷积核来卷积,这个比较常规。(这里还有一个用双线性插值的方法获取某一卷积形变后位置的输入的过程)
这里有一个介绍性的Slide:http://prlab.tudelft.nl/sites/default/files/Deformable_CNN.pdf
代表模型:Deformable Convolutional Networks(Deformable Convolutional Networks):暂时还没有其他模型使用这种卷积,期待后续会有更多的工作把这个idea和其他视觉任务比如检测,跟踪相结合。
6.特征重标定卷积
这是ImageNet 2017 竞赛 Image Classification 任务的冠军模型SENet的核心模块,原文叫做”Squeeze-and-Excitation“,我结合我的理解暂且把这个卷积称作”特征重标定卷积“。
和前面不同的是,这个卷积是对特征维度作改进的。一个卷积层中往往有数以千计的卷积核,而且我们知道卷积核对应了特征,于是乎那么多特征要怎么区分?这个方法就是通过学习的方式来自动获取到每个特征通道的重要程度,然后依照计算出来的重要程度去提升有用的特征并抑制对当前任务用处不大的特征。
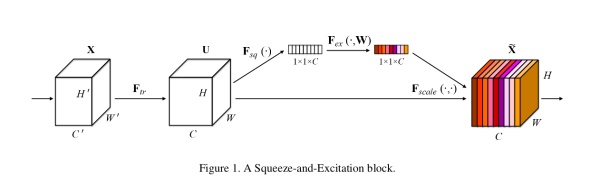
这个想法的实现异常的简单,简单到你难以置信。
首先做普通的卷积,得到了一个的output feature map,它的shape为[C,H,W],根据paper的观点,这个feature map的特征很混乱。然后为了获得重要性的评价指标,直接对这个feature map做一个Global Average Pooling,然后我们就得到了长度为C的向量。(这里还涉及到一个额外的东西,如果你了解卷积,你就会发现一旦某一特征经常被激活,那么Global Average Pooling计算出来的值会比较大,说明它对结果的影响也比较大,反之越小的值,对结果的影响就越小)
然后我们对这个向量加两个FC层,做非线性映射,这俩FC层的参数,也就是网络需要额外学习的参数。
最后输出的向量,我们可以看做特征的重要性程度,然后与feature map对应channel相乘就得到特征有序的feature map了。
虽然各大框架现在都还没有扩展这个卷积的api,但是我们实现它也就几行代码的事,可谓是简单且实用了。
另外它还可以和几个主流网络结构结合起来一起用,比如Inception和Res:
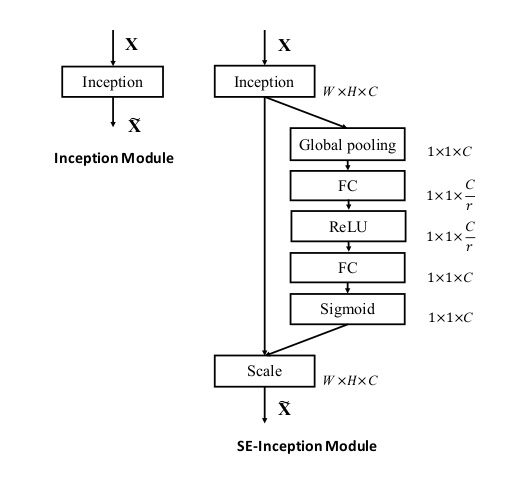
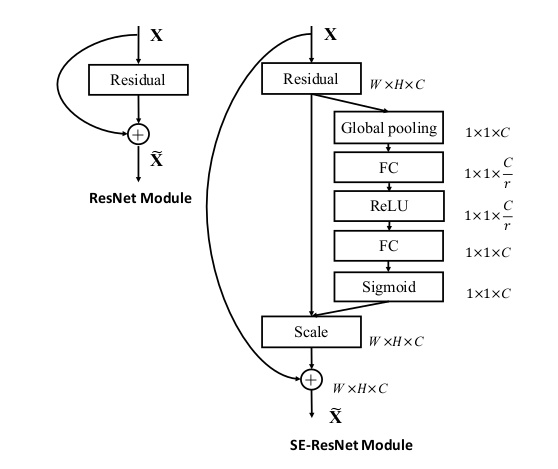
代表模型:Squeeze-and-Excitation Networks(Squeeze-and-Excitation Networks)
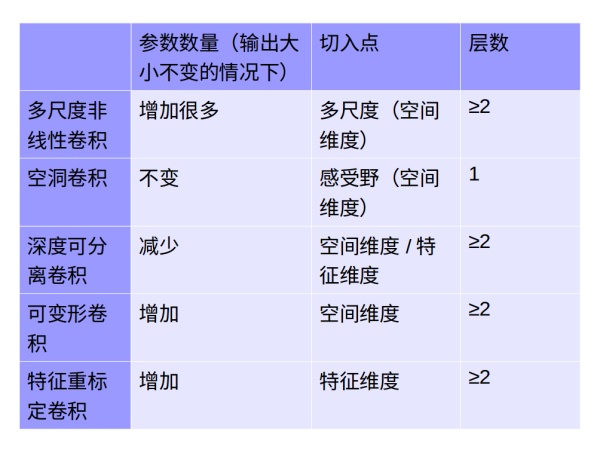
7.比较
我们把图像(height,width)作为空间维度,把channels做为特征维度。
 欢迎加入本站公开兴趣群
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4632.html
摘要:目前每年全球有万人死于车祸,损失,相关于很多国家的,自动驾驶可以很大效率的减少车祸,拯救生命。美国汽车工程师协会和美国高速公路安全局将自动驾驶技术进行了分级。特定场所的高度自动驾驶。这叫基于规则的一种自动驾驶,简单的。 来自 GitChat 作者:刘盼更多IT技术分享,尽在微信公众号:GitChat技术杂谈 进入 GitChat 阅读原文我们先以汽车在现代科技领域的演进来开始这次的ch...
摘要:而加快推动这一趋势的,正是卷积神经网络得以雄起的大功臣。卷积神经网络面临的挑战对的深深的质疑是有原因的。据此,也断言卷积神经网络注定是没有前途的神经胶囊的提出在批判不足的同时,已然备好了解决方案,这就是我们即将讨论的胶囊神经网络,简称。 本文作者 张玉宏2012年于电子科技大学获计算机专业博士学位,2009~2011年美国西北大学联合培养博士,现执教于河南工业大学,电子科技大学博士后。中国计...
摘要:目前目标检测领域的深度学习方法主要分为两类的目标检测算法的目标检测算法。原来多数的目标检测算法都是只采用深层特征做预测,低层的特征语义信息比较少,但是目标位置准确高层的特征语义信息比较丰富,但是目标位置比较粗略。 目前目标检测领域的深度学习方法主要分为两类:two stage的目标检测算法;one stage的目标检测算法。前者是先由算法生成一系列作为样本的候选框,再通过卷积神经网络进行样本...
摘要:卷积神经网络原理浅析卷积神经网络,最初是为解决图像识别等问题设计的,当然其现在的应用不仅限于图像和视频,也可用于时间序列信号,比如音频信号文本数据等。卷积神经网络的概念最早出自世纪年代科学家提出的感受野。 卷积神经网络原理浅析 卷积神经网络(Convolutional Neural Network,CNN)最初是为解决图像识别等问题设计的,当然其现在的应用不仅限于图像和视频,也可用于时间序...
摘要:从到,计算机视觉领域和卷积神经网络每一次发展,都伴随着代表性架构取得历史性的成绩。在这篇文章中,我们将总结计算机视觉和卷积神经网络领域的重要进展,重点介绍过去年发表的重要论文并讨论它们为什么重要。这个表现不用说震惊了整个计算机视觉界。 从AlexNet到ResNet,计算机视觉领域和卷积神经网络(CNN)每一次发展,都伴随着代表性架构取得历史性的成绩。作者回顾计算机视觉和CNN过去5年,总结...

阅读 1710·2021-11-22 13:53
阅读 2987·2021-11-15 18:10
阅读 2883·2021-09-23 11:21
阅读 2591·2019-08-30 15:55
阅读 565·2019-08-30 13:02
阅读 844·2019-08-29 17:22
阅读 1862·2019-08-29 13:56
阅读 3532·2019-08-29 11:31






