
摘要:然而,幸运的是,目前更为成功的目标检测方法是图像分类模型的扩展。几个月前,发布了一个用于的新的目标检测。
随着自动驾驶汽车、智能视频监控、人脸检测和各种人员计数应用的兴起,快速和准确的目标检测系统也应运而生。这些系统不仅能够对图像中的每个目标进行识别和分类,而且通过在其周围画出适当的边界来对其进行局部化(localizing)。这使得目标检测相较于传统的计算机视觉前身——图像分类来说更加困难。
然而,幸运的是,目前更为成功的目标检测方法是图像分类模型的扩展。几个月前,Google发布了一个用于Tensorflow的新的目标检测API。随着这个版本的发布,一些特定模型的预先构建的体系结构和权重为:
•带有MobileNets的Single Shot Multibox Detector(SSD)
•带有Inception V2的SSD
•具有Resnet 101的基于区域的完全卷积网络(R-FCN)
•具有Resnet 101的Faster R-CNN
•具有Inception Resnet v2的Faster R-CNN
在我上一篇博文(https://medium.com/towards-data-science/an-intuitive-guide-to-deep-network-architectures-65fdc477db41)中,我介绍了上面列出的三种基础网络架构背后的知识:MobileNets、Inception和ResNet。这一次,我想为Tensorflow的目标检测模型做同样的事情:Faster R-CNN、R-FCN和SSD。在读完这篇文章之后,我们希望能够深入了解深度学习是如何应用于目标检测的,以及这些目标检测模型是如何激发而出,以及从一个发散到另一个的。
Faster R-CNN
Faster R-CNN现在是基于深度学习的目标检测的标准模型。它帮助激发了许多后来基于它之后的检测和分割模型,包括我们今天要研究的另外两种模型。不幸的是,在不了解它的前任R-CNN和Fast R-CNN的情况下,我们是不能够真正开始理解Faster R-CNN,所以现在我们来快速了解一下它的起源吧。
R-CNN
R-CNN是Faster R-CNN的鼻祖。换句话说,R-CNN才是一切的开端。
R-CNN或基于区域的卷积神经网络由3个简单的步骤组成:
1.使用一种称为“选择性搜索”的算法扫描可能是目标的输入图像,生成约2000个区域提案。
2.在这些区域提案之上运行卷积神经网络(CNN)。
3.取每个CNN的输出并将其馈送到a)SVM(支持向量机)以对该区域进行分类,以及b)如果存在该目标,则线性回归器可以收紧该目标的边界框。
这三个步骤如下图所示:
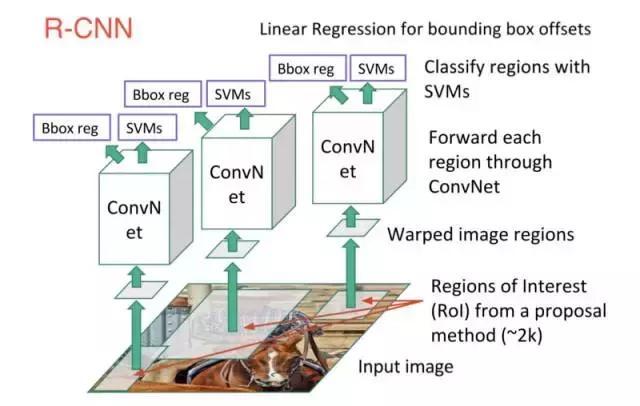
换句话说,我们首先提出区域,然后提取特征,然后根据它们的特征对这些区域进行分类。 从本质上来说,我们是将目标检测转化为图像分类问题。R-CNN是非常直观的,但同时也很慢。
Fast R-CNN
R-CNN的直系后裔是Fast-R-CNN。Fast R-CNN在许多方面都类似于原版,但是通过两个主要的增强来提高其检测速度:
1.在提出区域之前在图像上执行特征提取,因此在整个图像上仅运行一个CNN而不是在超过2000个重叠区域运行2000个CNN。
2.用softmax层代替SVM,从而扩展神经网络进行预测,而不是创建一个新的模型。
新模型看起来像这样:
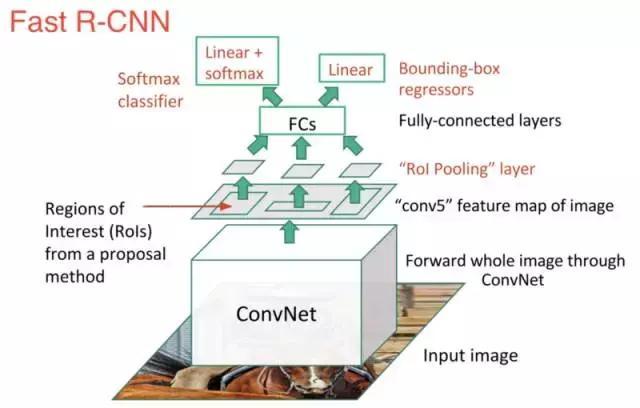
正如我们从图像中看到的那样,我们现在正在根据网络的最后一个特征映射,而不是从原始图像本身生成区域提案。因此,我们可以为整个图像训练一个CNN。
此外,代替训练许多不同的SVM来对每个目标类进行分类的方法是,有一个多带带的softmax层可以直接输出类概率。现在我们只有一个神经网需要训练,而不是一个神经网络和许多SVM。
Fast-R-CNN在速度方面表现更好,只剩下一个大瓶颈:用于生成区域提案的选择性搜索算法。
Faster R-CNN
在这一点上,我们回到了原来的目标:Faster R-CNN,Faster R-CNN的主要特点是用快速神经网络来代替慢速的选择性搜索算法。具体来说,介绍了区域提议网络(RPN)。
以下是RPN的工作原理:
•在初始CNN的最后一层,3x3滑动窗口移动到特征映射上,并将其映射到较低维度(例如256-d)。
•对于每个滑动窗口位置,它基于k个固定比例锚定框(默认边界框)生成多个可能的区域。
•每个区域提议包括a)该区域的“目标”得分,以及b)表示该区域边界框的4个坐标。
换句话说,我们来看看最后特征映射中的每一个位置,并考虑围绕它的k个不同的框:一个高框,一个宽框,一个大框等。对于每个框,我们要考虑的是它是否包含一个目标,以及该框的坐标是什么。这就是它在一个滑动窗口位置的样子:
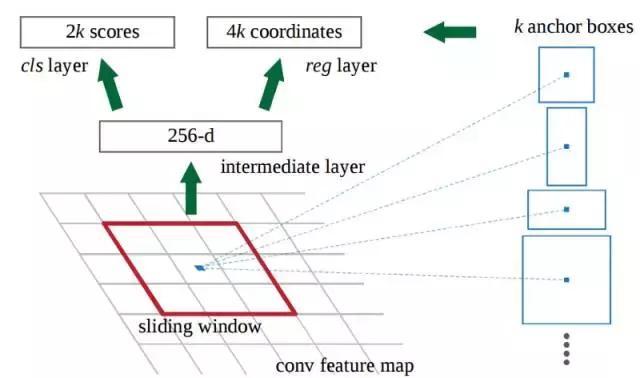
2k分数表示每个k边界框在“目标”上的softmax概率。请注意,虽然RPN输出的是边界框坐标,但它并没有尝试对任何潜在目标进行分类:其的工作仍然是提出目标区域。 如果锚箱(anchor box)的“对象”得分高于某个阈值,则该框的坐标将作为区域提议向前传递。
一旦我们有了区域提议,我们将把它们直接馈送到一个本质上是Fast R-CNN的网络中。我们添加一个池化层,一些完全连接层,最后添加一个softmax分类层和边界盒回归(bounding box regressor)。在某种意义上,Faster R-CNN = RPN + Fast R-CNN。
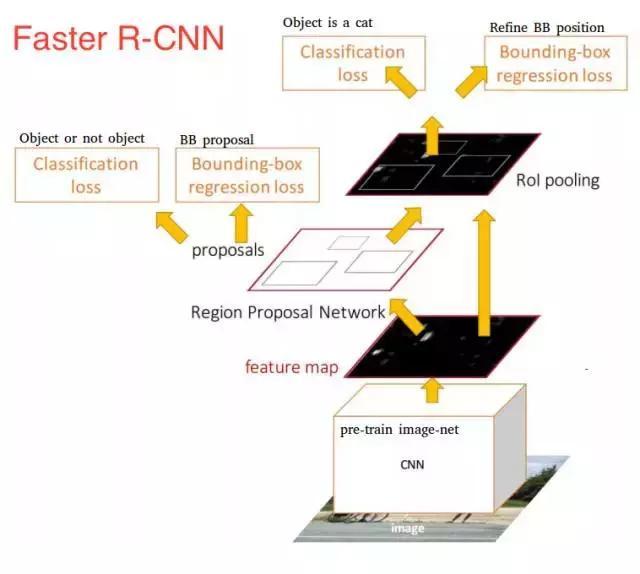
总而言之,Faster R-CNN取得了更好的速度和较先进的精度。值得注意的是,尽管未来的模型确实提高了检测速度,但是很少有模型能够能够以显著的优势战胜Faster R-CNN。换句话说,Faster R-CNN可能不是目标检测的最简单或最快的方法,但它仍然是性能较好的方法之一。例如,具有Inception ResNet的Tensorflow的Faster R-CNN是他们最慢但最准确的模型。
最后要说的是,Faster R-CNN可能看起来很复杂,但其核心设计与原始R-CNN相同:假设目标区域,然后对其进行分类。现在这是许多目标检测模型中的主要流水线,当然也包括下一个我们要介绍的。
R-FCN
还记得Fast R-CNN是如何通过在所有区域提议中共享单个CNN计算,以可以提高原始检测速度的吗?这种想法也是R-FCN背后的动机:通过较大化共享计算来提高速度。
R-FCN或基于区域的完全卷积网络,在每个单个输出中共享100%的计算。它是一个完全卷积,在模型设计中遇到了一个独特的问题。
一方面,当对目标进行分类时,我们想在模型中学习位置不变性:不管猫出现在图像中的什么位置,我们都希望的是将其分类为猫。另一方面,当执行目标象的检测时,我们想要学习位置方差:如果猫在左上角,我们要在左上角绘制一个框。那么,如果我们试图在100%的网络中共享卷积计算,那么我们如何在位置不变性和位置方差之间进行妥协呢?
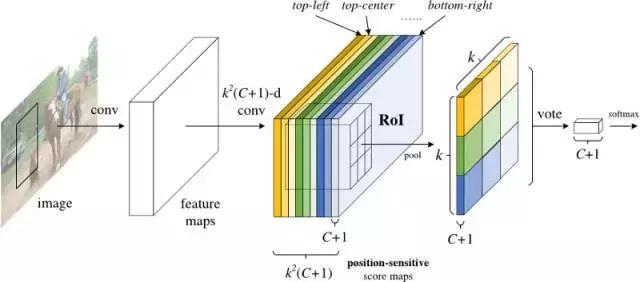
R-FCN的解决方案:位置敏感分数图(position-sensitive score maps)
每个位置敏感分数图表示一个目标类的一个相对位置。例如,一个分数图可以激活它检测到的猫的右上角的任何位置,另一个得分图可能会激活它看到一辆汽车的底部。现在你明白了吧,本质上说,这些分数图是经过训练以识别每个目标的某些部分的卷积特征图。
现在,R-FCN的工作原理如下:
1. 在输入图像上运行CNN(在这种情况下,应为ResNet)。
2.添加一个完整的卷积层以产生上述“位置敏感分数图”的分数库。应该有k2(C + 1)个分数图,其中k ^2表示用于划分目标的相对位置数(例如,3^2表示 3×3网格),C + 1表示类加上背景的数量。
3.运行完全卷积区域提议网络(RPN)来生成感兴趣的区域(RoI)。
4.对于每个RoI,将其划分为与分数图相同的k2个“bin”或子区域。
5.对于每个bin,请检查分数库,以查看该bin是否与某个目标的相应位置相匹配。例如,如果我在“左上角”bin,我将抓住与目标的“左上角”对应的得分图,并平均RoI区域中的这些值。每个类都要重复此过程。
6.一旦k2个bin中的每一个都有一个与每个类相对应的“目标匹配”值,那么,每个类就可以平均每个bin以得到一个单一的分数。
7.在剩余的C + 1维向量上用softmax对RoI进行分类。
总而言之,R-FCN看起来像这样,RPN产生了RoI的内容:
即使有了解释和图像,你可能仍然对此模型的工作原理有些困惑。老实说,当你可以想象它在做什么时,R-FCN可能就更容易理解了。这又一个用R-FCN进行实践的例子,检测一个婴儿:

简单地说,R-FCN考虑到每个区域的建议,将其划分为子区域,并在子区域内进行迭代,问:“这样看起来像婴儿的左上角吗?”,“这样看起来像婴儿的正上方吗?”“这样看起来像一个婴儿的右上角吗?”等等。它重复了所有可能的类。如果有足够多的子区域说“是的,我和宝宝的那一部分匹配”,那么在对所有类进行softmax之后,RoI被归类为一个宝宝。
通过这种设置,R-FCN能够通过提出不同的目标区域来解决位置方差,并且通过使每个区域提议返回到相同的分数图,来同时解决位置不变性。这些分数图应该学会将猫分类为猫,而不管猫出现在哪里。最重要的是,它是完全卷积的,意味着所有的计算都在整个网络中共享。
因此,R-FCN比Faster R-CNN快几倍,并且具有可观的准确性。
SSD
我们的最终模型是SSD,它表示Single-Shot Detector。像R-FCN一样,它提供了比Faster R-CNN更快的速度,但是是以一种截然不同的方式。
我们的前两个模型分别在两个不同的步骤中进行区域建议和区域分类。首先,他们使用区域提议网络来产生感兴趣的区域;接下来,他们使用完全连接层或位置敏感卷积层来对这些区域进行分类。而SSD在“single shot”中将两者同时进行,在处理图像时,同时预测边框和类。
具体来说,给定一个输入图像和一组地面真相标签,SSD将执行以下操作:
1.通过一系列卷积层传递图像,在不同的尺度上产生几个不同的特征映射(例如10×10,然后6×6,然后3×3等)。
2.对于每个这些特征映射中的每个位置,使用3x3的卷积滤波器来评估一小组默认边界框。这些默认边界框本质上等同于Faster R-CNN的锚箱。
3.对于每个框,同时预测a)边界框偏移量和b)类概率。
4.在训练过程中,将地面真相框与基于IoU的预测方框进行匹配。较好的预测框将被标记为“positive”,以及其他所有具有实际值> 0.5的IoU框。
SSD听起来很简单,但训练起来却有一个独特的挑战。在前两种模型中,区域提议网络确保了我们试图分类的所有东西都有一个成为“目标”的最小可能性。但是,使用SSD,我们跳过了该过滤步骤。我们使用多种不同的形状,以几种不同的尺度,对图像中的每个单个位置进行分类和绘制边界框。因此,我们可能会产生比其他模型更多的边界框,而几乎所有这些都是负面的样本。
为了解决这个不平衡问题,SSD做了两件事情。首先,它使用非较大抑制将高度重叠的边框组合在一个边框中。换句话说,如果有四个具有相同形状和尺寸等因素的边框包含着同样一只狗,则NMS将保持具有较高置信度的那一个,而将其余的丢弃。其次,该模型在训练期间使用一种称为难分样本挖掘(hard negative mining to balance classes)的技术来平衡类。在难分样本挖掘中,在训练的每次迭代中仅使用具有较高训练损失(即假阳性)的负面样本的一部分子集。SSD的负和正比例为3:1。
它的架构如下所示:
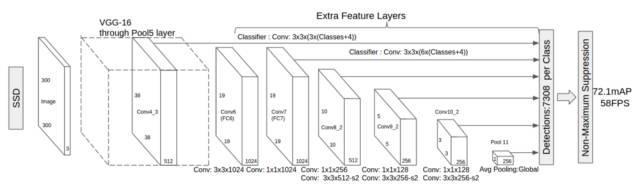
正如我上面提到的那样,“额外的特征层”在最后尺寸将缩小。这些不同大小的特征映射有助于捕获不同大小的目标。例如,以下是SSD的操作:
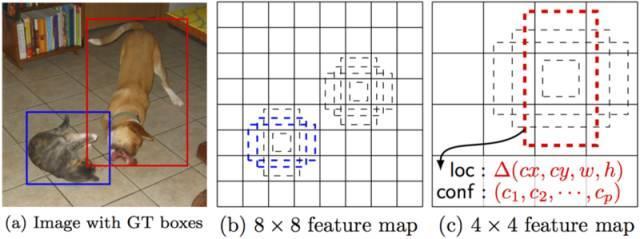
在较小的特征映射(例如4×4)中,每个单元覆盖图像种的较大区域,使得它们能够检测较大的目标。区域提议和分类同时执行:给定p目标类,每个边界框都与一个(4+p)的空间向量相关联,输出4个方框偏移坐标和p类的概率。在最后一步中,softmax再次被用于对目标进行分类。
最终,SSD与前两个模型并没有太大差别。它只是跳过“区域提议”这个步骤,而是考虑图像种每个位置的每个单个边界框,同时进行分类。因为SSD能够一次性完成所有操作,所以它是这三个模型中速度最快的,而且执行性能具有一定的可观性。
结论
Faster R-CNN,R-FCN和SSD是目前市面上较好和最广泛使用的三个目标检测模型。而其他受欢迎的模型往往与这三个模型非常相似,所有这些都依赖于深度CNN的知识(参见:ResNet,Inception等)来完成最初的繁重工作,并且大部分遵循相同的提议/分类流程。
在这一点上,想要使用这些模型的话,你只需要知道Tensorflow的API。Tensorflow有一个关于使用这些模型的一个入门教程,点击此处链接获得教程。(https://github.com/tensorflow/models/blob/master/research/object_detection/object_detection_tutorial.ipynb)
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4639.html
摘要:值得一提的是每篇文章都是我用心整理的,编者一贯坚持使用通俗形象的语言给我的读者朋友们讲解机器学习深度学习的各个知识点。今天,红色石头特此将以前所有的原创文章整理出来,组成一个比较合理完整的机器学习深度学习的学习路线图,希望能够帮助到大家。 一年多来,公众号【AI有道】已经发布了 140+ 的原创文章了。内容涉及林轩田机器学习课程笔记、吴恩达 deeplearning.ai 课程笔记、机...
摘要:是你学习从入门到专家必备的学习路线和优质学习资源。的数学基础最主要是高等数学线性代数概率论与数理统计三门课程,这三门课程是本科必修的。其作为机器学习的入门和进阶资料非常适合。书籍介绍深度学习通常又被称为花书,深度学习领域最经典的畅销书。 showImg(https://segmentfault.com/img/remote/1460000019011569); 【导读】本文由知名开源平...
摘要:本届会议共收到论文篇,创下历史记录有效篇。会议接收论文篇接收率。大会共有位主旨演讲人。同样,本届较佳学生论文斯坦福大学的,也是使用深度学习做图像识别。深度学习选择深度学习选择不过,也有人对此表示了担心。指出,这并不是做学术研究的方法。 2016年的计算机视觉领域国际顶尖会议 Computer Vision and Pattern Recognition conference(CVPR2016...
摘要:通过利用一系列利用视频局部性的优化,显著降低了在每个帧上的计算量,同时仍保持常规检索的高精度。的差异检测器目前是使用逐帧计算的逻辑回归模型实现的。这些检测器在上的运行速度非常快,每秒超过万帧。也就是说,每秒处理的视频帧数超过帧。 视频数据正在爆炸性地增长——仅英国就有超过400万个CCTV监控摄像头,用户每分钟上传到 YouTube 上的视频超过300小时。深度学习的进展已经能够自动分析这些...

阅读 3588·2021-10-18 13:30
阅读 3032·2021-10-09 09:44
阅读 2079·2019-08-30 11:26
阅读 2444·2019-08-29 13:17
阅读 824·2019-08-29 12:17
阅读 2351·2019-08-26 18:42
阅读 587·2019-08-26 13:24
阅读 3046·2019-08-26 11:39





