
摘要:训练深度神经网络需要大量的内存,用户使用这个工具包,可以在计算时间成本仅增加的基础上,在上运行规模大倍的前馈模型。使用导入此功能,与使用方法相同,使用梯度函数来计算参数的损失梯度。随后,在反向传播中重新计算检查点之间的节点。

OpenAI是电动汽车制造商特斯拉创始人 Elon Musk和著名的科技孵化器公司 Y Combinator总裁 Sam Altman于 2016年联合创立的 AI公司,使命是建立安全的人工智能,确保 AGI(Artificial general intelligence,通用人工智能)的全球效益“尽可能广泛和均匀分配”。
目前,这个非营利组织已经有 60名全职研究人员和工程人员,“摒弃随之产生的利己机会,为实现自己的使命而奋斗”。
Y Combinator和一家电动车制造商能够走到一起创办人工智能公司 OpenAI,是因为两家公司共同的目标:创造一种新的人工智能实验室,这个实验室不受包括 Google在内的任何人的控制,让人类以安全的方式开发真正的人工智能。人工智能威胁论的 Musk建立 OpenAI,除了他所说让人类以安全的方式开发真正的人工智能这一目标外,也是出于其公司未来业务的需求,特斯拉、SpaceX都需要人工智能。
他同时也是十分积极的人工智能威胁论支持者,多次直言不讳对于人工智能失去人类控制导致灾难性后果的担忧。
研究成果:使用梯度检查点节约内存
OpenAI自创立以来开发了分层强化学习算法、机器人模拟训练闭环系统等项目,近日研究员 Tim Salimans和 Yaroslav Bulatov又推出了一个工具包,可以让内存计算和模型更加适配。
训练深度神经网络需要大量的内存,用户使用这个工具包,可以在计算时间成本仅增加 20%的基础上,在 GPU上运行规模大 10倍的前馈模型。
同样地,计算反向传播的梯度损失会在训练深度神经网络的过程中占用大量内存。通过我们这个模型定义的计算图检查点节点,并在反向传播期间重新计算这些节点之间的图形部分,可以降低计算梯度的内存成本。当训练由 n层组成的深度前馈神经网络时,我们可以以这种方式将存储器消耗降低到 O(sqrt(n)),代价是执行一次额外的正向传播(参见例子:Training Deep Nets with Sublinear Memory Cost, by Chen et al(2016)。这个存储库在 Tensorflow中提供了这个功能,使用 Tensorflow图形编辑器自动重写反向传递的计算图。
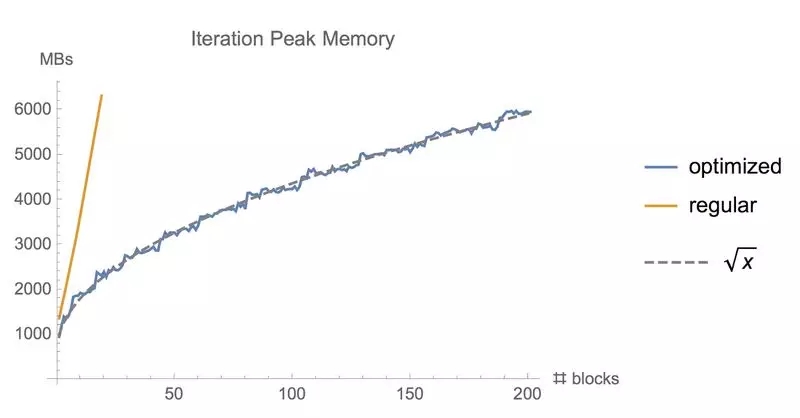
使用常规 tf.gradients函数和我们的内存优化梯度方法训练同样批量大小的 ResNet模型时所使用的内存
如何运行?
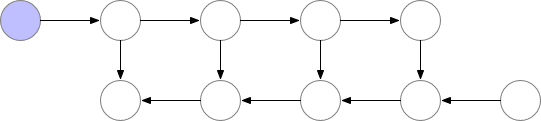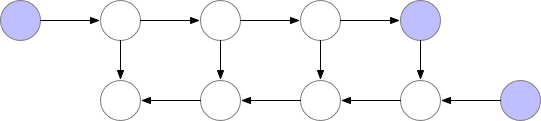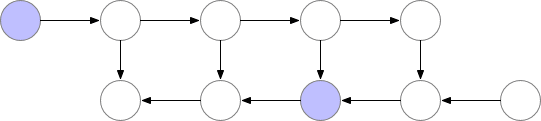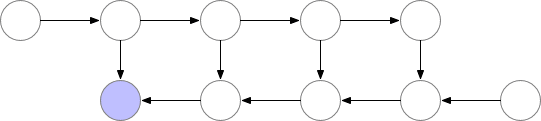
对于具有 n层的简单前馈神经网络,用于获得梯度的计算图如下所示:
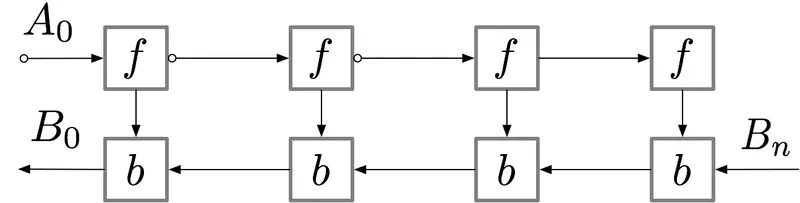
标记了 f的节点激活神经网络层。在正向传递期间,所有这些节点按顺序一一被评估。相对于这些层的激活和参数的损失梯度由用 b标记的节点表示。在反向传递期间,所有这些节点都按照相反的顺序进行评估。计算 b节点需要 f节点的计算结果,因此所有 f节点在正向传递之后都被保存在存储器中。只有当反向传播进行到足以计算出一个 f节点的所有依赖关系或子节点时,它才能从内存中消失。这意味着简单反向传播所需的内存随神经网络层数 n线性增长。下面我们显示这些节点的计算顺序。紫色阴影圆圈表示在给定时间需要保存在内存中的节点。
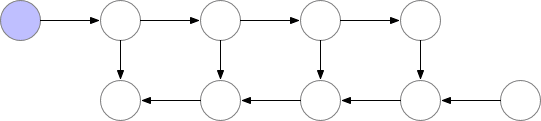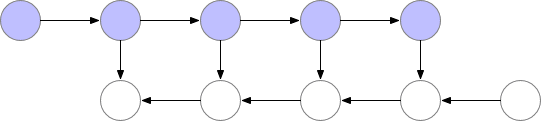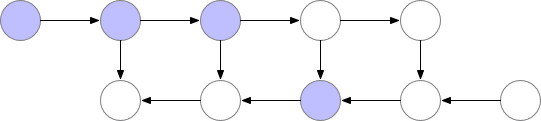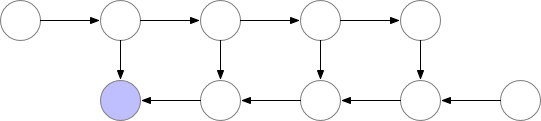
Vanilla backprop
如上所述的简单反向传播的计算效果较佳:它仅对每个节点进行一次计算。但是,如果我们愿意重新计算节点,则可以节省大量内存。例如,当需要时我们可以简单地重新计算每个节点的正向传递。执行顺序和使用的内存如下所示:
使用这种策略,图中计算神经网络层数为 n的梯度所需的内存不变,这在内存方面是最优的。但是,请注意,节点评估的数量现在扩大到 n ^2,而之前为 n:n个节点中的每一个都按 n次的顺序重新计算。因此,对于深度网络来说,图形计算变得慢得多,这使得该方法在深度学习中不切实际。
为了在内存和计算之间取得平衡,我们需要提出一个允许节点重新计算但不至于太频繁的策略。我们在这里使用的策略是将神经网络激活的一个子集标记为检查点节点。
我们选择的检查点节点
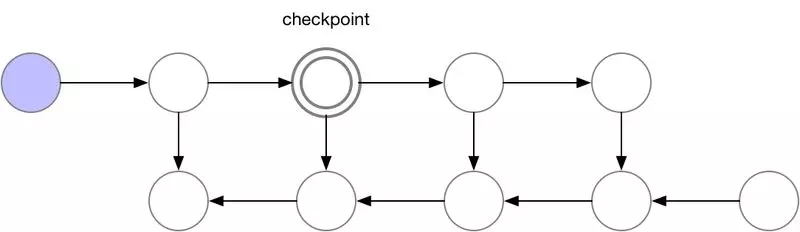
这些检查点节点在正向传递后保留在内存中,而其余节点至多重新计算一次。重新计算后,非检查点节点将保存在内存中,直到不再需要它们。对于简单前馈神经网络来说,所有的神经元激活节点都是由正向传播定义的图形分隔符或关节点。这意味着我们只需要在 backprop期间计算 b节点时,重新计算 b节点和它之前的最后一个检查点之间的节点。当 backprop计算进展到检查点节点时,所有从它重新计算的节点都可以从内存中删除。计算和内存使用的结果顺序如下所示:
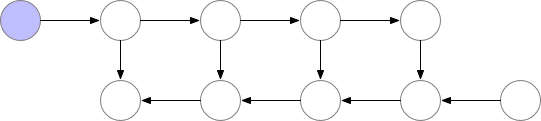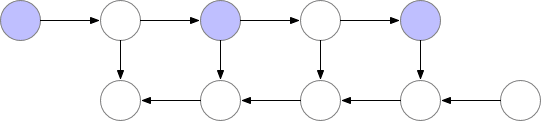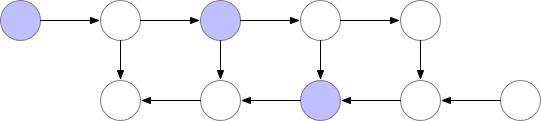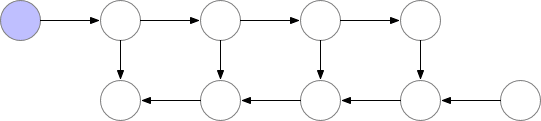
图 3.检查节点 backprop
对于本例中的简单前馈网络来说,较佳选择是将每个 sqrt(n)节点标记为检查点。这样,检查点节点的数量和检查点之间的节点数目都是 sqrt(n),这意味着所需的内存现在也与我们网络中层数的平方根成比例。由于每个节点最多只能重新计算一次,因此该策略所需的额外计算量仅相当于网络的单个正向传递。
我们的软件包可以实现检查点 backprop,如上图 3所示。这个过程是通过采用将上图(图 1)标准 backprop,并使用 Tensorflow图形编辑器对其自动重写来实现的。对于包含关节点(单节点图分隔符)的图,我们使用 sqrt(n)策略自动选择检查点,为前馈网络提供 sqrt(n)所需内存。对于只包含多节点图分隔符的普通图像,使用我们的检查点 backprop仍然有效,但是目前还需要用户手动选择检查点。
在我们软件包的 博客文章中可以找到计算图、内存使用情况和梯度计算策略的附加说明文件。
安装要求
pip install tf-nightly-gpu
pip install toposort networkx pytest
另外,在运行测试时,要确保可以找到 CUDA分析工具接口(CUPTI),例如,通过运行
```pip install toposort networkx pytestexport LD_LIBRARY_PATH =“$ {LD_LIBRARY_PATH}:/ usr / local / cuda / extras / CUPTI / lib64”
使用方法
这个存储库提供了基于 Tensorflow的 tf.gradient的替代方案。使用from memory_saving_gradients import gradients导入此功能,与使用 tf.gradients方法相同,使用梯度函数来计算参数的损失梯度。 (假设你明确地调用 tf.gradients,而不是在 tf.train.Optimizer中隐式调用)。
除了 tf.gradients的常规参数之外,我们的梯度函数还有一个额外的参数:检查点。检查点参数将通过计算图告诉您向前传递过程中所需检查点的梯度函数。随后,在反向传播中重新计算检查点之间的节点。您可以使用很多 tensor、梯度(ys,xs,检查点 = [tensor1,tensor2]),或者可以使用以下几个关键字之一:
"collection"(默认值):检查由 tf.get_collection("checkpoints")返回的所有张量。之后在定义模型时,需要确保使用 tf.add_to_collection(“检查点”,张量)将张量添加到此集合中。
"内存":使用启发式自动选择一组节点作为检查点,实现我们所需的 O(sqrt(n))内存使用。启发式方法通过自动识别图中的关节点,即在移除时将图分成两个部分的张量,然后找出这些张量的合理数目。目前,它适用于很多(但不是全部)模型。
"速度":这个选项通过检查所有操作的输出来使运行速度较大化,且通常成本高昂,即卷积和矩阵乘法。
覆盖tf.gradients
直接使用新梯度函数的一个有效果的替代方法,是覆写 Python已经注册到 tf.gradients的函数,如下所示:
import tensorflow as tf
import memory_saving_gradients
# monkey patch tf.gradients to point to our custom version, with automatic checkpoint selection
def gradients_memory(ys, xs, grad_ys=None, **kwargs):
return memory_saving_gradients.gradients(ys, xs, grad_ys, checkpoints="memory", **kwargs)
tf.__dict__["gradients"] = gradients_memory
之后,使用节约内存的版本对 tf.gradients的调用都将使用内存保存版本。
测试
测试文件夹包含用于测试代码的正确性,并分析各种模型内存使用情况的脚本。修改代码后,您可以从该文件夹运行./run_all_tests.sh来执行测试。
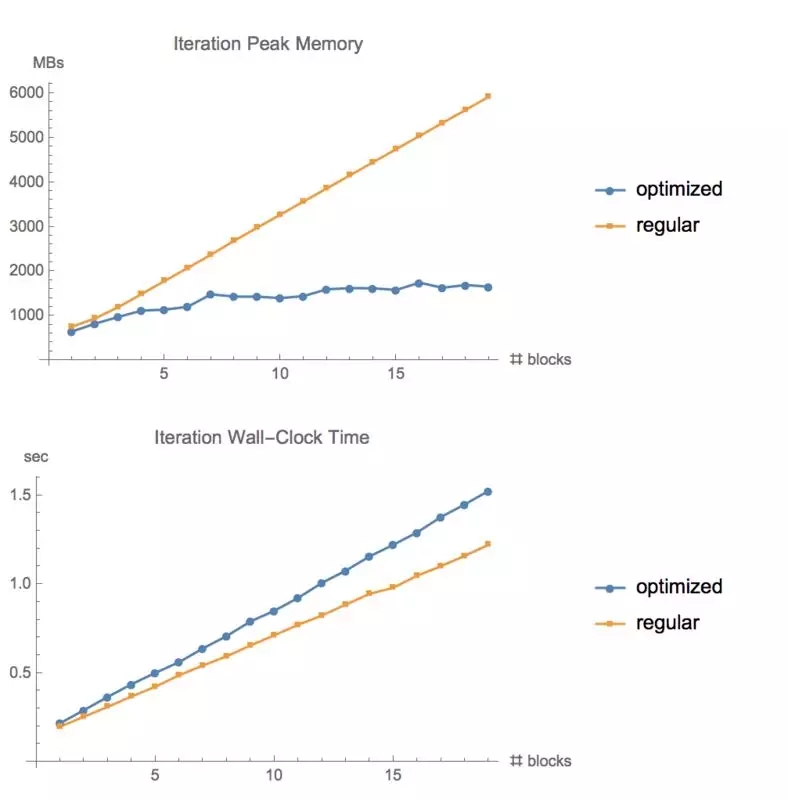
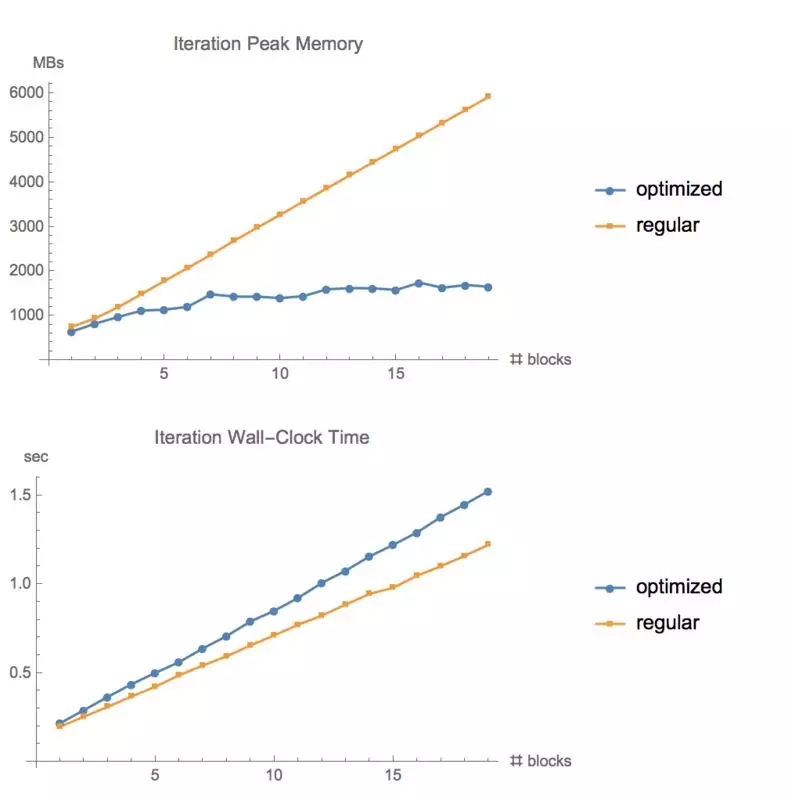
在 CIFAR10上测试不同层数的 ResNet的内存使用情况和运行时间。大小为 1280,GTX1080
限制
在运行处理大型图形过慢的模型之前,这些代码用 Python执行所有的图形操作。当前用于自动选择检查点的算法纯粹是启发式的,预计在我们测试之外的某些模型上会失败。在这种情况下,应使用手动模式选择检查点。
参考
Academic papers describing checkpointed backpropagation: Training Deep Nets with Sublinear Memory Cost, by Chen et al. (2016), https://arxiv.org/pdf/1604.06174.pdfMemory-Efficient Backpropagation Through Time, by Gruslys et al. (2016) https://arxiv.org/pdf/1604.06174.pdf
Explanation of using graph_editor to implement checkpointing on TensorFlow graphs: https://github.com/tensorflow/tensorflow/issues/4359#issuecomment-269241038, https://github.com/yaroslavvb/stuff/blob/master/simple_rewiring.ipynb
Experiment code/details: https://medium.com/@yaroslavvb/testing-memory-saving-on-v100-8aa716bbdf00
TensorFlow memory tracking package:
https://github.com/yaroslavvb/chain_constant_memory/blob/master/mem_util_test.py
Implementation of "memory-poor" backprop strategy in TensorFlow for a simple feed-forward net:
https://github.com/yaroslavvb/chain_constant_memory/
再度招兵买马
在过去的几个月,OpenAI一直保持沉默。而近期,这家公司似乎渴望把更多的人才招揽到团队中去,发布了多个招聘职位。
从公司发布的工作岗位上看,团队不仅需要招聘协调员,还要招聘更多的人员。
https://twitter.com/OpenAI/status/951498942541283328?ref_src=twsrc%5Etfw&ref_url=https%3A%2F%2Finterestingengineering.com%2Felon-musk-and-openai-want-to-create-an-artificial-intelligence-that-wont-spell-doom-for-humanity
目前,OpenAI官网招聘页面放出的招聘岗位(以旧金山为例)主要包括技术人员(基础架构工程师,机器学习方面工程师、研究院、工作人员、实习生)、运营人员(业务经理、招聘协调员)。
招聘页面:https://jobs.lever.co/openai
当初,OpenAI花了大价钱邀请一众大佬加盟,其中就包括曾在谷歌和 Facebook实习过的研究员 Wojciech Zaremba,说 OpenAI开出的价钱“近乎疯狂”。那么,疯狂的 offer价钱在 2016年时到底是什么水平呢?据微软研究院副总裁 Peter Lee称,当时一名较高级研究员的 offer远超过美国全国橄榄球联赛的较高级四分卫的酬劳,这还是在没有硅谷跟你抢人才的情况下。Zaremba说道,OpenAI给他开出的价格是市场平均水平的两至三倍。
联想到最近 OpenAI人才流失比较严重,比如加州伯克利大学教授、机器人学习大牛 Pieter Abbeel离开 OpenAI创立智能机器人公司 Embodied Intelligence,想必这次招聘他们出的价钱也不会低。
原文链接:
https://github.com/openai/gradient-checkpointing
https://openai.com/
https://interestingengineering.com/elon-musk-and-openai-want-to-create-an-artificial-intelligence-that-wont-spell-doom-for-humanity
欢迎加入本站公开兴趣群商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4718.html
摘要:更广泛地说,这些结果表明神经网络训练不需要被认为是一种炼丹术,而是可以被量化和系统化。中间的曲线中存在弯曲,渐变噪声标度预测弯曲发生的位置。 由于复杂的任务往往具有更嘈杂的梯度,因此越来越大的batch计算包,可能在将来变得有用,从而消除了AI系统进一步增长的一个潜在限制。更广泛地说,这些结果表明神经网络训练不需要被认为是一种炼丹术,而是可以被量化和系统化。在过去的几年里,AI研究人员通过数...
摘要:第一个主流产品级深度学习库,于年由启动。在年月日宣布,的开发将终止。张量中最基本的单位是常量变量和占位符。占位符并没有初始值,它只会分配必要的内存。是一个字典,在字典中需要给出每一个用到的占位符的取值。 为什么选择 TensorFlow?在本文中,我们将对比当前最流行的深度学习框架(包括 Caffe、Theano、PyTorch、TensorFlow 和 Keras),帮助你为应用选择最合适...
摘要:七强化学习玩转介绍了使用创建来玩游戏将连续的状态离散化。包括输入输出独热编码与损失函数,以及正确率的验证。 用最白话的语言,讲解机器学习、神经网络与深度学习示例基于 TensorFlow 1.4 和 TensorFlow 2.0 实现 中文文档 TensorFlow 2 / 2.0 官方文档中文版 知乎专栏 欢迎关注我的知乎专栏 https://zhuanlan.zhihu.com/...
摘要:为了进一步了解的逻辑,图对和进行了展开分析。另外,在命名空间中还隐式声明了控制依赖操作,这在章节控制流中相关说明。简述是高效易用的开源库,有效支持线性代数,矩阵和矢量运算,数值分析及其相关的算法。返回其中一块给用户,并将该内存块标识为占用。 3. TF 代码分析初步3.1 TF总体概述为了对TF有整体描述,本章节将选取TF白皮书[1]中的示例展开说明,如图 3 1所示是一个简单线性模型的TF...
摘要:我仍然用了一些时间才从神经科学转向机器学习。当我到了该读博的时候,我很难在的神经科学和的机器学习之间做出选择。 1.你学习机器学习的历程是什么?在学习机器学习时你最喜欢的书是什么?你遇到过什么死胡同吗?我学习机器学习的道路是漫长而曲折的。读高中时,我兴趣广泛,大部分和数学或科学没有太多关系。我用语音字母表编造了我自己的语言,我参加了很多创意写作和文学课程。高中毕业后,我进了大学,尽管我不想去...

阅读 3136·2023-04-25 18:58
阅读 1227·2021-11-25 09:43
阅读 1455·2021-10-25 09:46
阅读 3748·2021-09-09 11:40
阅读 2097·2021-08-05 09:59
阅读 1078·2019-08-29 15:07
阅读 1097·2019-08-29 12:48
阅读 951·2019-08-29 11:19






