
摘要:本文介绍了如何利用上的免费资源更快地训练模型。本文将介绍如何在上使用训练已有的模型,其训练速度是在上训练速度的倍。使用静态训练模型,并将权重保存到文件。使用推理模型进行预测。
本文介绍了如何利用 Google Colab 上的免费 Cloud TPU 资源更快地训练 Keras 模型。

很长一段时间以来,我在单个 GTX 1070 显卡上训练模型,其单精度大约为 8.18 TFlops。后来谷歌在 Colab 上启用了免费的 Tesla K80 GPU,配备 12GB 内存,且速度稍有增加,为 8.73 TFlops。最近,Colab 的运行时类型选择器中出现了 Cloud TPU 选项,其浮点计算能力为 180 TFlops。
本文将介绍如何在 Colab 上使用 TPU 训练已有的 Keras 模型,其训练速度是在 GTX 1070 上训练速度的 20 倍。
我们首先构建一个易于理解但训练过程比较复杂的 Keras 模型,以便「预热」Cloud TPU。在 IMDB 情感分类任务上训练 LSTM 模型是个不错的选择,因为 LSTM 的计算成本比密集和卷积等层高。
流程如下所示:
构建一个 Keras 模型,可使静态输入 batch_size 在函数式 API 中进行训练。
将 Keras 模型转换为 TPU 模型。
使用静态 batch_size * 8 训练 TPU 模型,并将权重保存到文件。
构建结构相同但输入批大小可变的 Keras 模型,用于执行推理。
加载模型权重。
使用推理模型进行预测。
读者阅读本文时,可以使用 Colab Jupyter notebook Keras_LSTM_TPU.ipynb(https://colab.research.google.com/drive/1QZf1WeX3EQqBLeFeT4utFKBqq-ogG1FN)进行试验。
首先,按照下图的说明在 Colab 运行时选项中选择激活 TPU。
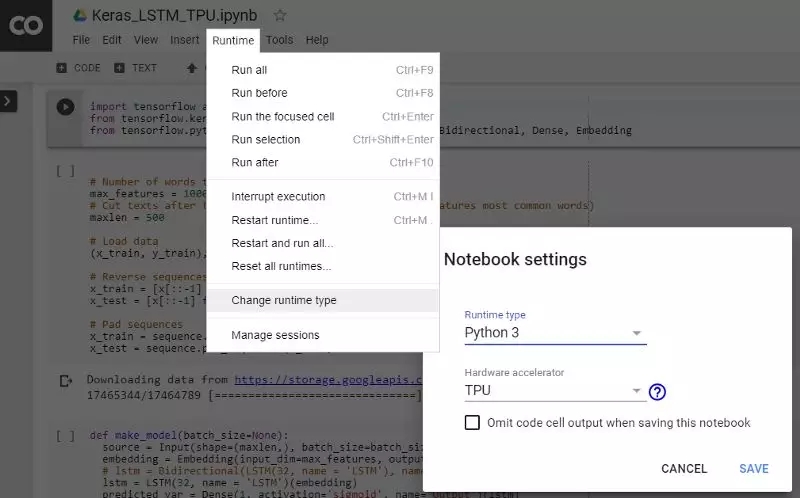
激活 TPU
静态输入 Batch Size
在 CPU 和 GPU 上运行的输入管道大多没有静态形状的要求,而在 XLA/TPU 环境中,则对静态形状和 batch size 有要求。
Could TPU 包含 8 个可作为独立处理单元运行的 TPU 核心。只有八个核心全部工作,TPU 才算被充分利用。为通过向量化充分提高训练速度,我们可以选择比在单个 GPU 上训练相同模型时更大的 batch size。最开始较好设定总 batch size 为 1024(每个核心 128 个)。
如果你要训练的 batch size 过大,可以慢慢减小 batch size,直到它适合 TPU 内存,只需确保总的 batch size 为 64 的倍数即可(每个核心的 batch size 大小应为 8 的倍数)。
使用较大的 batch size 进行训练也同样有价值:通常可以稳定地提高优化器的学习率,以实现更快的收敛。(参考论文:https://arxiv.org/pdf/1706.02677.pdf)
在 Keras 中,要定义静态 batch size,我们需使用其函数式 API,然后为 Input 层指定 batch_size 参数。请注意,模型在一个带有 batch_size 参数的函数中构建,这样方便我们再回来为 CPU 或 GPU 上的推理运行创建另一个模型,该模型采用可变的输入 batch size。
import tensorflow as tf
from tensorflow.python.keras.layers import Input, LSTM, Bidirectional, Dense, Embedding
def make_model(batch_size=None):
source = Input(shape=(maxlen,), batch_size=batch_size,
dtype=tf.int32, name="Input")
embedding = Embedding(input_dim=max_features,
output_dim=128, name="Embedding")(source)
lstm = LSTM(32, name="LSTM")(embedding)
predicted_var = Dense(1, activation="sigmoid", name="Output")(lstm)
model = tf.keras.Model(inputs=[source], outputs=[predicted_var])
model.compile(
optimizer=tf.train.RMSPropOptimizer(learning_rate=0.01),
loss="binary_crossentropy",
metrics=["acc"])
return model
training_model = make_model(batch_size=128)
此外,使用 tf.train.Optimizer,而不是标准的 Keras 优化器,因为 Keras 优化器对 TPU 而言还处于试验阶段。
将 Keras 模型转换为 TPU 模型
tf.contrib.tpu.keras_to_tpu_model 函数将 tf.keras 模型转换为同等的 TPU 模型。
import os
import tensorflow as tf
# This address identifies the TPU we"ll use when configuring TensorFlow.
TPU_WORKER = "grpc://" + os.environ["COLAB_TPU_ADDR"]
tf.logging.set_verbosity(tf.logging.INFO)
tpu_model = tf.contrib.tpu.keras_to_tpu_model(
training_model,
strategy=tf.contrib.tpu.TPUDistributionStrategy(
tf.contrib.cluster_resolver.TPUClusterResolver(TPU_WORKER)))
然后使用标准的 Keras 方法来训练、保存权重并评估模型。请注意,batch_size 设置为模型输入 batch_size 的八倍,这是为了使输入样本在 8 个 TPU 核心上均匀分布并运行。
history = tpu_model.fit(x_train, y_train,
epochs=20,
batch_size=128 * 8,
validation_split=0.2)
tpu_model.save_weights("./tpu_model.h5", overwrite=True)
tpu_model.evaluate(x_test, y_test, batch_size=128 * 8)
我设置了一个实验,比较在 Windows PC 上使用单个 GTX1070 和在 Colab 上运行 TPU 的训练速度,结果如下。
GPU 和 TPU 都将输入 batch size 设为 128,
GPU:每个 epoch 需要 179 秒。20 个 epoch 后验证准确率达到 76.9%,总计 3600 秒。
TPU:每个 epoch 需要 5 秒,第一个 epoch 除外(需 49 秒)。20 个 epoch 后验证准确率达到 95.2%,总计 150 秒。
20 个 epoch 后,TPU 上训练模型的验证准确率高于 GPU,这可能是由于在 GPU 上一次训练 8 个 batch,每个 batch 都有 128 个样本。
在 CPU 上执行推理
一旦我们获得模型权重,就可以像往常一样加载它,并在 CPU 或 GPU 等其他设备上执行预测。我们还希望推理模型接受灵活的输入 batch size,这可以使用之前的 make_model() 函数来实现。
inferencing_model = make_model(batch_size=None)
inferencing_model.load_weights("./tpu_model.h5")
inferencing_model.summary()
可以看到推理模型现在采用了可变的输入样本。
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
Input (InputLayer) (None, 500) 0
_________________________________________________________________
Embedding (Embedding) (None, 500, 128) 1280000
_________________________________________________________________
LSTM (LSTM) (None, 32) 20608
_________________________________________________________________
Output (Dense) (None, 1) 33
=================================================================
然后,你可以使用标准 fit()、evaluate() 函数与推理模型。
结论
本快速教程介绍了如何利用 Google Colab 上的免费 Cloud TPU 资源更快地训练 Keras 模型。
原文链接:https://www.kdnuggets.com/2019/03/train-keras-model-20x-faster-tpu-free.html
声明:本文版权归原作者所有,文章收集于网络,为传播信息而发,如有侵权,请联系小编及时处理,谢谢!商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
文章版权归作者所有,未经允许请勿转载,若此文章存在违规行为,您可以联系管理员删除。
转载请注明本文地址:https://www.ucloud.cn/yun/4868.html

当涉及到大规模的机器学习任务时,加速处理速度是至关重要的。Tensor Processing Units(TPUs)是一种专门为机器学习任务设计的硬件加速器,可以在训练和推断阶段显著提高TensorFlow模型的性能。 在本文中,我们将讨论如何使用TPUs加速TensorFlow模型的训练过程。首先,我们将简要介绍TPUs的工作原理,然后探讨如何在TensorFlow中使用TPUs进行训练。 ...
摘要:首先,我们一起来开一个脑洞想象一个最理想的深度学习引擎应该是什么样子的,或者说深度学习引擎的终极形态是什么看看这会给深度学习框架和专用芯片研发带来什么启发。众所周知,现在是深度学习领域应用最广的计算设备,据说比更加强大,不过目前只有可以用。 首先,我们一起来开一个脑洞:想象一个最理想的深度学习引擎应该是什么样子的,或者说深度学习引擎的终极形态是什么?看看这会给深度学习框架和AI专用芯片研发带...

阅读 1269·2023-04-26 02:02
阅读 2558·2021-09-26 10:11
阅读 3695·2019-08-30 13:10
阅读 3892·2019-08-29 17:12
阅读 862·2019-08-29 14:20
阅读 2312·2019-08-28 18:19
阅读 2380·2019-08-26 13:52
阅读 1095·2019-08-26 13:43



