
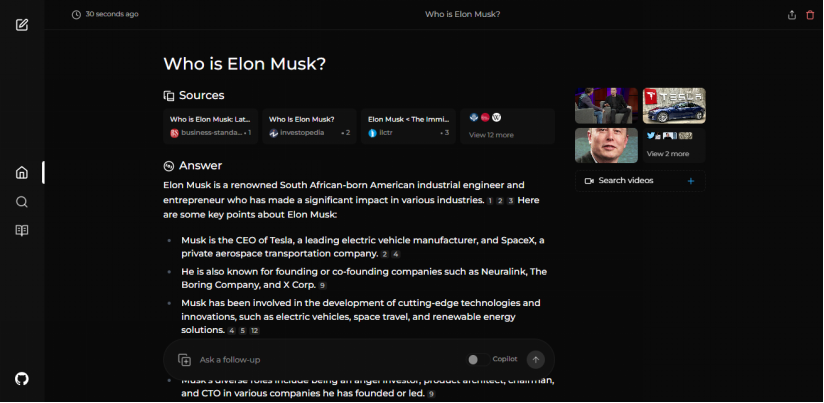
Perplexica是一个开源的人工智能搜索工具,也可以说是一款人工智能搜索引擎,它深入互联网以找到答案。受Perplexity AI启发,它是一个开源选择,不仅可以搜索网络,还能理解您的问题。它使用先进的机器学习算法,如相似性搜索和嵌入式技术,以精细化结果,并提供附有来源的清晰答案。利用SearxNG保持最新和完全开源,Perplexica确保您始终获取最新的信息,而不会损害您的隐私。特点本地L...

Llama3-8B-Chinese-Chat 是基于 Meta-Llama-3-8B-Instruct 模型通过 ORPO进行微调的中文聊天模型。与原始的 Meta-Llama-3-8B-Instruct 模型相比,此模型显著减少了中文问题英文回答"和混合中英文回答的问题。此外,相较于原模型,新模型在回答中大量减少了表情符号的使用,使得回应更加正式。与 Llama-3-8B-nsturc...
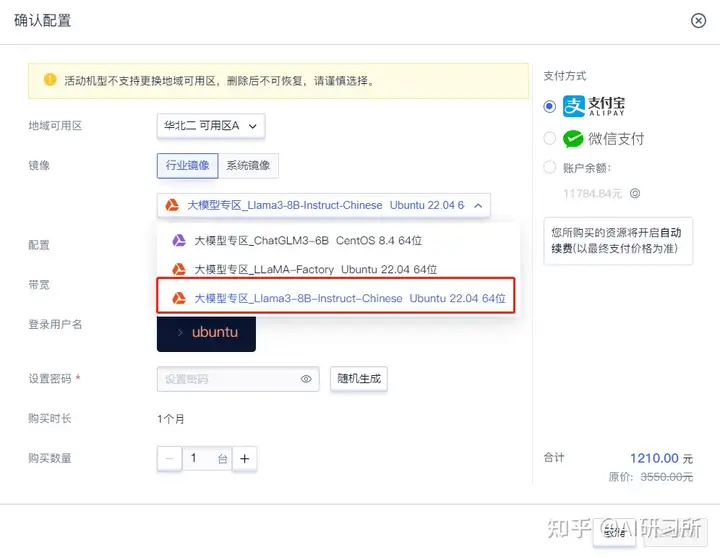
2024年4月18日,Meta AI正式宣布推出开源大模型Llama3,这标志着开源大型语言模型(LLM)领域的又一重大突破。Llama3以其卓越的性能和广泛的应用前景,或将推动人工智能技术快速迈进新纪元。为方便AI应用企业及个人AI开发者快速体验Llama3的超高性能,近期优刻得GPU云主机上线Llama3-8B-Instruct-Chinese镜像,一键配置,快速部署模型开发环境。为客户提供开...
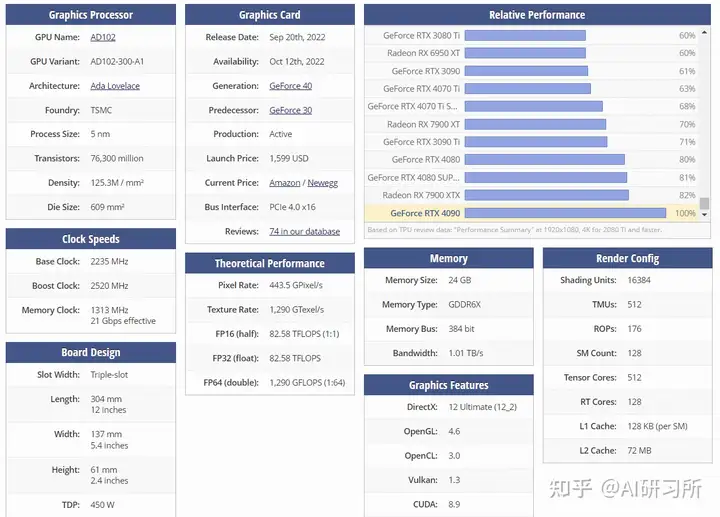
随着人工智能的持续火热,好的加速卡成为了各行业的重点关注对象,因为在AI机器学习中,通常涉及大量矩阵运算、向量运算和其他数值计算。这些计算可以通过并行处理大幅提高效率,而高端显卡的存在,使得在处理要求拥有大量算力的任务时,变得不那么难了。这篇文章大家伙聊聊RTX4090这款显卡,4090论性能不如H100,论价格不如3090,那为什么能成为众多企业、高校科研人员眼中的香饽饽?1. 强大的性能RTX...
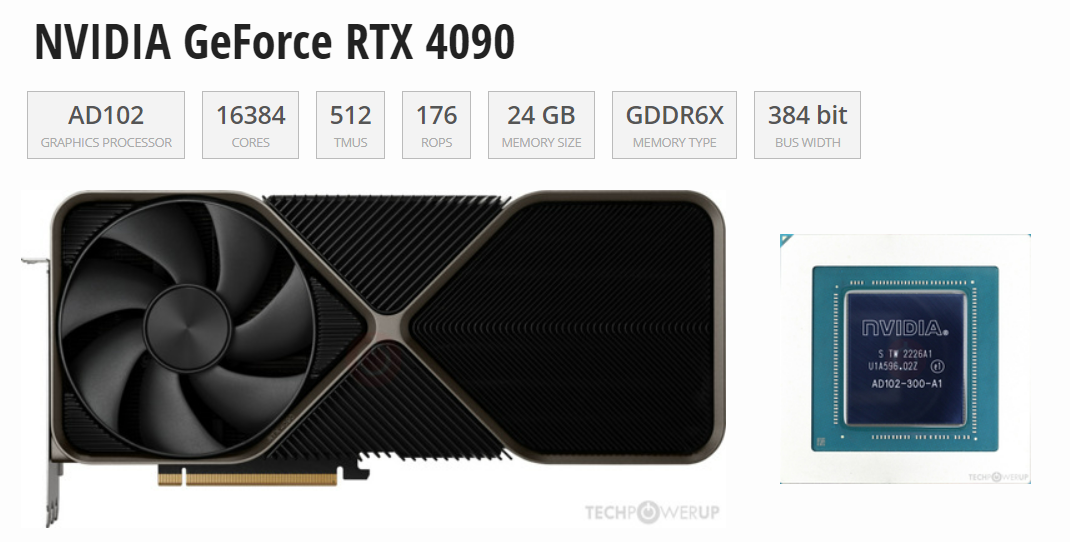
图示为GPU性能排行榜,我们可以看到所有GPU的原始相关性能图表。同时根据训练、推理能力由高到低做了排名。我们可以看到,H100 GPU的8位性能与16位性能的优化与其他GPU存在巨大差距。针对大模型训练来说,H100和A100有绝对的优势首先,从架构角度来看,A100采用了NVIDIA的Ampere架构,而H100则是基于Hopper架构。Ampere架构以其高效的图形处理性能和多任务处理能力而...






